
This is the second part of my "Build in Public with Kiro" series. I'm an AWS Community Builder, and this is the story of what happens when you share something early, people actually care, and the project grows faster than you expected.
🏃 TL;DR
Since the first article, KiroGraph went from a CLI agent prototype (v0.5.0) to a multi-client, 30+ language, architecture-aware code knowledge graph (v0.13.1). It's now published on npm, has a full documentation site, an interactive graph dashboard, and supports Claude Code and Codex alongside Kiro. Most of this happened because people showed up, contributed, and pushed the project in directions I hadn't planned.
 davide-desio-eleva
/
kirograph
davide-desio-eleva
/
kirograph
Semantic code knowledge graph for Kiro: fewer tool calls, instant symbol lookups, 100% local.
![]()
KiroGraph
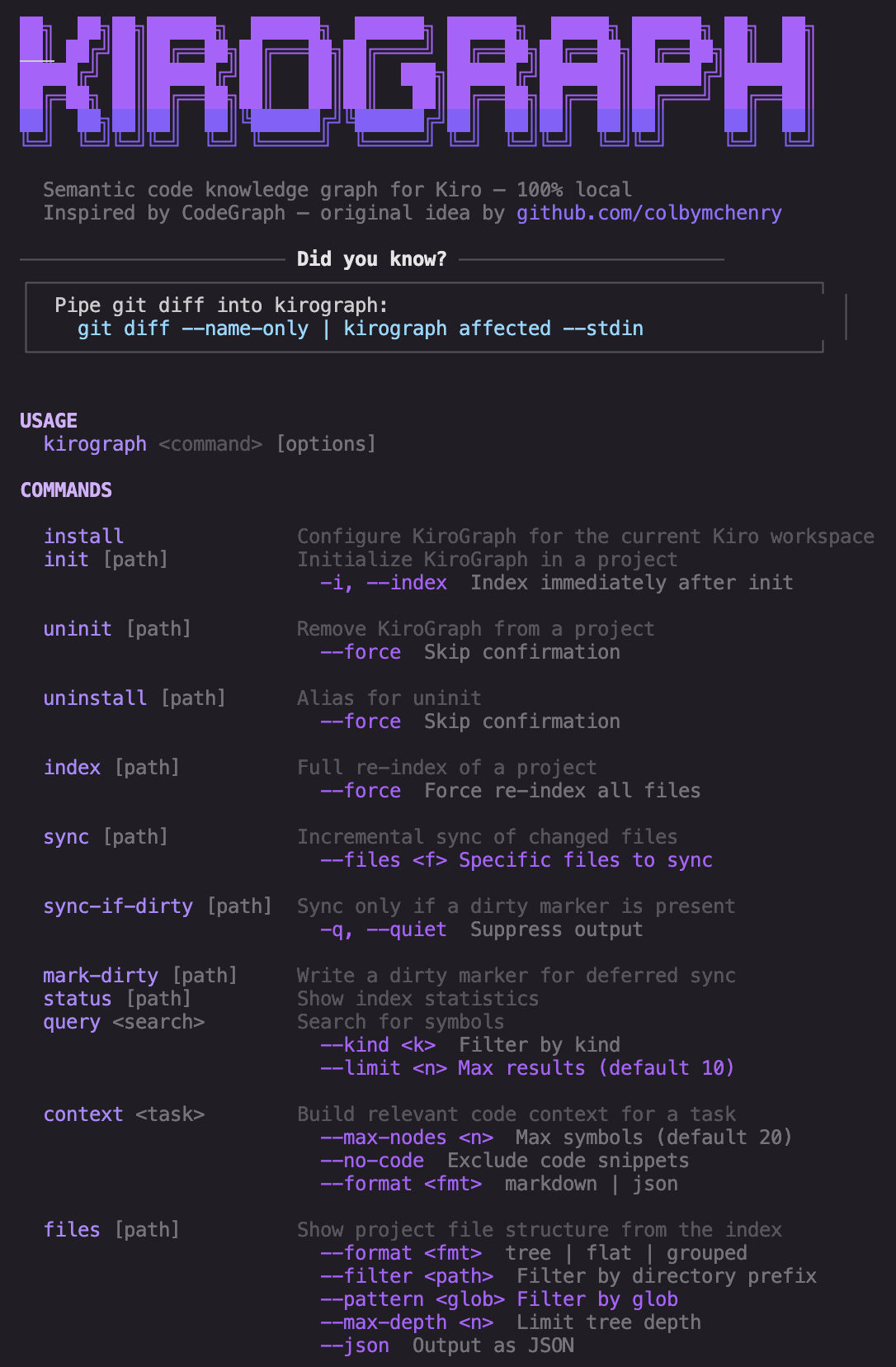
Semantic code knowledge graph for Kiro: fewer tool calls, instant symbol lookups, 100% local.
Inspired by CodeGraph by colbymchenry for Claude Code, rebuilt natively for Kiro's MCP and hooks system.
Full support is for Kiro only. Experimental integrations for 34 other MCP-capable tools (Cursor, Copilot, Claude Code, Windsurf, Cline, and more) are available with auto-detection. See Integrations for the full list.
Why KiroGraph?
When you ask Kiro to work on a complex task, it explores your codebase using file reads, grep, and glob searches. Every one of those is a tool call, and tool calls consume context and slow things down.
KiroGraph gives Kiro a semantic knowledge graph that's pre-indexed and always up to date. Instead of scanning files to understand your code, Kiro queries the graph instantly: symbol relationships, call graphs, type hierarchies, impact radius, all in a single MCP tool call.
The result is fewer tool…
📈 Where we left off
The first post covered the core idea: pre-index your codebase into a semantic graph so the AI agent queries structure instead of re-reading files. At that point KiroGraph had structural indexing, seven semantic engines, an interactive installer, and a CLI agent for kiro-cli.
That was v0.5.0. Here's what happened next.
👻 Kiro acceleration effect
I want to be honest about something: this pace of development wouldn't have been possible without Kiro.
KiroGraph went from v0.5.0 to v0.13.1 in about five weeks, adding architecture analysis, 14 new languages, 17 framework resolvers, an interactive graph dashboard, multi-client support, npm publication, a documentation site, and dozens of bug fixes. As a side project. With a day job.
Kiro's spec-driven development is the reason. When I need to add a new framework resolver, I don't start from a blank file. I write a spec, Kiro breaks it into tasks, and the implementation flows from there. The agent understands the existing patterns (especially with KiroGraph indexing itself), so new code fits the architecture without me hand-holding every decision.
But here's where it gets interesting for open source specifically.
🔄 Simpler to contribute
When contributors work in a TypeScript codebase that isn't their primary stack, it's Kiro that makes that possible. The spec-driven approach gives structure to the work, the agent handles the TypeScript idioms, and the contributor focuses on what they actually know: the domain expertise. Someone who knows Elixir deeply can contribute a full Phoenix framework resolver without being a TypeScript expert. Someone who understands how Claude Code's MCP configuration works can wire up a multi-client integration without knowing the internals of the indexing pipeline.
I received PRs for features I wouldn't have imagined building myself, in domains where I lack expertise, and they were solid. My role shifted from "implement everything" to "review and guide". That's a fundamentally different way to run an open source project.
🔀 It works the other way around as well
Community members bring ideas from their domain. Architecture analysis, coupling metrics, layer detection patterns. These came from people who understood the problem space deeply. I had the codebase context and the TypeScript implementation skills. Kiro bridged the gap: their ideas became specs, specs became tasks, tasks became working code. Fast.
This is the pattern I didn't anticipate: community members bring domain knowledge and ideas, Kiro accelerates the implementation regardless of who writes the code, and the project ships features that no single person would have built alone.
🌐 People as global reviewer
When you build in public with an AI-accelerated workflow, the community acts as a global reviewer. People try KiroGraph on codebases I've never seen, in languages I don't write daily, with frameworks I've never used. They find the bugs that only surface in production-like conditions.
he multi-language call edge bug in v0.12.0 had actually existed since v0.1.0. Nobody noticed because nobody was using KiroGraph on a Java project until someone did.
Speed matters here and when a bug report comes in, I can fix it very quickly. Kiro understands the codebase, the fix is scoped, the PR is merged, and the reporter sees their issue resolved in hours, not weeks. That responsiveness builds trust, and trust brings more contributors.
⚡ Acceleration is real
I'm not being hyperbolic: combination of Kiro's spec-driven development, KiroGraph's self-indexing feedback loop, and a community that both contributes code and stress-tests the result creates a development velocity that feels disproportionate to the effort. One person maintaining a 30+ language code analysis tool with 18 MCP tools, seven semantic engines, and an interactive dashboard shouldn't be sustainable. But it is, because the tooling makes it sustainable.
If you're hesitant to contribute to a project because the stack isn't your primary one, Kiro removes that barrier: the domain expertise is yours while the implementation details are handled.
👥 Kiro Community
As mentioned earlier, the project's trajectory changed because people from *Kiro Community engaged with it. Two main examples:
Maurizio Argoneto commented on the first post about "hierarchical summarization" and the "big picture" problem. That conversation directly influenced the architecture analysis feature, one of the most useful additions for understanding large codebases at a high level.
Alessandro Franceschi contributed Elixir/Phoenix language support and the multi-client integration (Claude Code and Codex), expanding KiroGraph well beyond its original Kiro-only scope.
I was initially reluctant to open this project to other AI clients, agents, or IDEs, but Alessandro explained the situation to me very clearly: people are using Kiro in a wide range of ways and within a multi-tool AI development process that fits their needs. Restricting this project to Kiro alone would, in my view, mean closing the door to those who actually want to use it in this scenario. So I’m not opening it to competing AIs, but rather to complementary ones.
The stargazers, the folks who opened issues, the people who tried it on their own codebases and reported what broke. All of that feedback shaped what got built and in what order. That's the kind of feedback loop that makes building in public worthwhile.


Kiro Community is really outstanding in this.

The project has been recognized by AWS Community Builders team


And also enthusiastically endorsed by Kiro Ambassadors

Noted by Vice President at Amazon Web Services

Loved by far more people than I might imagine (those are just sample, I may be missing some screenshots, apologies for that!)







📊 New features by numbers
As a result, from v0.5.0 to v0.13.1, I've added several features:
30+ languages supported (up from 17)
17 framework resolvers added
18 MCP tools (up from 12)
Interactive graph dashboard with search, path finding, clustering, heat maps
Architecture analysis with coupling metrics
Multi-client support (Kiro, Claude Code, Codex)
Full documentation site
Published on npm
🏗️ What got built
Now let's walk through the features themselves.
🏛️ Architecture analysis (v0.6.0)
An architecture layer that detects packages (via manifest files like package.json, go.mod, Cargo.toml, pom.xml, etc.) and assigns files to architectural layers: api, service, data, ui, shared. Each layer uses language-specific glob patterns, so a Python Flask project and a TypeScript Express project both get correctly classified.
On top of that, KiroGraph now computes coupling metrics between packages: afferent coupling (Ca), efferent coupling (Ce), and instability (Ce / (Ca + Ce)). Three new MCP tools expose this to the agent: kirograph_architecture, kirograph_coupling, kirograph_package.
The practical effect: when Kiro needs to understand where a new feature should live, or whether a refactor will create circular dependencies between packages, it can query the architecture graph instead of guessing from file paths.
🧠 Embedding model selection (v0.7.0)
The installer now presents an arrow-key menu with four curated models plus a custom option. The embeddingDim config field means all vector engines adapt automatically. Migrated from @xenova/transformers (v2) to @huggingface/transformers (v3), enabling support for modern ONNX models.
🔧 The esbuild migration (v0.8.0)
The old tsc build took 5-10 seconds. After migrating to esbuild + tsx, builds dropped to ~400ms with incremental watch mode. Type checking is now decoupled (npm run typecheck), so you get fast feedback during development and correctness checks when you need them.
Small change, big quality-of-life improvement. Especially when you're iterating on the tool using the tool itself.
🪨 Caveman mode (v0.9.0)
Inspired by caveman by JuliusBrussee. The insight: KiroGraph's graph tools already return compact, structured data. The bottleneck in long sessions isn't the tool calls, it's the verbose prose the agent wraps around them.
Caveman mode compresses the agent's communication style. Four levels: off, lite, full, ultra. At ultra, you get abbreviations, arrows for causality, maximum compression. The rules are injected via the steering file and CLI agent prompt, so they're always in context with zero extra tool calls.
It never touches code blocks, file paths, or technical terms. Only prose. And it auto-reverts to normal for security warnings or irreversible actions.
kirograph caveman ultra # maximum compression
kirograph caveman off # back to normal
📊 Hotspots, snapshots & dead code (v0.10.0)
Three new MCP tools that give the agent analytical capabilities:
kirograph_hotspots finds the most-connected symbols by edge degree. Before you touch a function, you want to know if it's called from 3 places or 300.
kirograph_surprising finds non-obvious cross-file connections. Scores edges by path distance × kind weight. The highest-scoring pairs are the ones that represent unexpected coupling worth investigating.
kirograph_diff compares the current graph against a saved snapshot. Save before a refactor, diff after. See exactly what changed structurally.
Plus CLI commands for all of them, and a snapshot system (kirograph snapshot save|list|diff) that stores lightweight graph states in .kirograph/snapshots/.
🎨 Interactive graph dashboard (v0.11.0)
kirograph export now renders a full interactive graph visualization. No server required, works offline, three static files.
This is the kind of thing that's hard to describe in text. You open it in a browser and suddenly the structure of your codebase is visible. Where the hotspots are, which modules are tightly coupled, where the dead ends live.

🧬 Elixir, Phoenix, Java/C# edge cases (v0.12.0)
Full Elixir language support: modules, functions, macros, protocols, implementations, structs. Plus Phoenix framework detection with route extraction from router.ex.
The bigger fix in this release was improving multi-language call edge extraction. It turned out that walkForCalls only recognized call_expression (JS/TS/Go/Rust), which meant C#, Java, Python, Ruby, and PHP produced zero call edges. The kirograph_callers and kirograph_callees tools were silently returning nothing for those languages. Fixed now, with per-language name extraction using tree-sitter field lookups.
Same story for inheritance edges in C# and Java, and namespace/package import resolution. These were the kind of bugs that only surface when real people try the tool on real codebases in languages other than TypeScript.
🔄 Sync progress & stability (v0.12.1)
Large codebase support got serious attention here. Paginated embedding (pages of 2,000 instead of loading everything into memory), WASM parser poisoning detection (skip a language if its parser aborts instead of retrying every file), sync progress output, and a staleness warning in kirograph_status when the index is behind.
The MCP sync awareness is particularly nice: when pending unindexed files exceed a threshold, the agent gets a warning and can choose to wait rather than working with stale data.
📚 Documentation site & npm (v0.12.2)
KiroGraph is now published on npm (npm install -g kirograph) and has a full documentation site with dark theme, responsive layout, scroll-spy navigation, and pages for docs, MCP tools, CLI reference, and changelog.

This was overdue. A tool that saves tokens shouldn't require reading source code to understand how to use it.

And also how it evolves

🌍 The big language expansion (v0.13.0)

14 new languages in one release: Scala, Lua, Zig, Bash, OCaml, Elm, Solidity, Vue, Objective-C, YAML, HCL/Terraform, CSS, SCSS, HTML.
So many languages that I had to add a search feature to the docs.
17 new framework resolvers: Play (Scala), Nuxt/Vue, Solidity (Hardhat/Foundry/Truffle), SST, AWS CDK, Serverless Framework, AWS SAM, Terraform/OpenTofu, Pulumi, CloudFormation, Kubernetes/Helm, Docker Compose, Ansible, Angular, and AWS Amplify Gen 2.
My best pick: since I regularly work on IaC projects, why shouldn’t I use KiroGraph for them?

This is where the project's scope expanded significantly. KiroGraph started as a TypeScript-focused tool. Now it indexes infrastructure-as-code (Terraform resources, CloudFormation stacks, Kubernetes manifests), smart contracts (Solidity with Hardhat/Foundry detection), and serverless configurations (SAM, CDK, SST handler resolution).
The framework resolvers are particularly useful: they understand that a handler string like "src/handlers/auth.handler" in a SAM template points to an actual function symbol, and they create the edge in the graph. The agent can then trace from an API route all the way to the implementation without reading YAML files.
🤝 Multi-client support (v0.13.1)
KiroGraph can now be installed for Claude Code and Codex in addition to Kiro.
kirograph install --target claude # .mcp.json + .kirograph/claude.md + CLAUDE.md import
kirograph install --target codex # .kirograph/codex.md + AGENTS.md block
All targets share the same .kirograph/ data. Installing another target only writes that tool's integration files. The graph is the graph, regardless of which agent queries it.
Kiro remains the primary supported target. Claude Code and Codex are marked experimental, but they work. The community asked for it, and it made sense: the value of a pre-indexed code graph isn't tied to a specific IDE.
🔭 What's next
The roadmap from the first post is mostly done.
What's left and what's new:
- Smarter sync: content hash per embedding to skip unchanged symbols even when the file was modified. The paginated embedding in v0.12.1 was a step, but there's more to gain.
- Cross-project search: for monorepos and workspaces with shared libraries. The graph is per-project right now.
- Richer graph traversal: "explain this path" semantically, not just the nodes but why each edge exists.
- Plugin system for engines and languages: the abstractions are clean enough that external contributions could be self-contained packages.
- Kiro Power packaging: embedding KiroGraph into a configurable Kiro Power to reduce friction for folks who just want to install and go.
But in reality, the community is shaping the roadmap: this tool is designed to save tokens and improve the AI’s understanding of the provided code, so it is the users who ultimately determine what matters most.
This is happening daily:

What’s really on my mind: I’m particularly curious about what it would mean to integrate features from RTK into KiroGraph. I’m not aiming for a “one tool for everything” approach, but if I had to prioritize, this is probably what I’d focus on first (spoiler here).
🎯 Try it
npm install -g kirograph
cd your-project
kirograph install
The installer walks you through everything. Start with cosine if you're not sure which engine to pick. Switch later if you need to.
davide-desio-eleva
/
kirograph
Semantic code knowledge graph for Kiro: fewer tool calls, instant symbol lookups, 100% local.
![]()
KiroGraph
Semantic code knowledge graph for Kiro: fewer tool calls, instant symbol lookups, 100% local.
Inspired by CodeGraph by colbymchenry for Claude Code, rebuilt natively for Kiro's MCP and hooks system.
Full support is for Kiro only. Experimental integrations for 34 other MCP-capable tools (Cursor, Copilot, Claude Code, Windsurf, Cline, and more) are available with auto-detection. See Integrations for the full list.
Why KiroGraph?
When you ask Kiro to work on a complex task, it explores your codebase using file reads, grep, and glob searches. Every one of those is a tool call, and tool calls consume context and slow things down.
KiroGraph gives Kiro a semantic knowledge graph that's pre-indexed and always up to date. Instead of scanning files to understand your code, Kiro queries the graph instantly: symbol relationships, call graphs, type hierarchies, impact radius, all in a single MCP tool call.
The result is fewer tool…
The repo is public. PRs are welcome. If you build on it, find a bug, or have thoughts on where it should go next, I'd love to hear from you.
A very special thanks to the Stargazers, your support means a lot and truly makes a difference.
🙋 Who am I
I'm D. De Sio and I work as a Head of Software Engineering in Eleva.
As of Feb 2026, I’m an AWS Certified Solution Architect Professional and AWS Certified DevOps Engineer Professional, but also a User Group Leader (in Pavia), an AWS Community Builder and, last but not least, a #serverless enthusiast.


Top comments (0)