
I'm building a game.
No, it's not a serious game that I intend to make money on or have thousands of users playing simultaneously. It's a game that serves two purposes:
- Help me learn about front-end development with Next.js (I'm always trying to learn something new)
- Educate others about caching use cases (it's not just about databases, it can totally be used for short-lived data in games)
It's a fun learning experience for me where I get to stretch my skills and apply current serverless best practices in a fun and relatable manner. The game is called Acorn Hunt and is open-sourced on GitHub if you want to follow along as I build it out.
I was working on the API the other day and I noticed several repetitive validations with my endpoints. Not only that, but all the endpoints were prefixed with the same resources to provide the right context, like POST /games/{gameId}/points and DELETE /games/{gameId}/super-abilities.
For my use case, a user can have a single active game at any given time. So I figured I could add the active game to the user session.
A user session remembers a user's preferences, actions, and data for a specific time they visit your site.
This data is short-lived, or ephemeral, and only applies to this specific time the user is logged into the game. When the user logs out, we throw all the personalized information away and rebuild it the next time they sign in.
With this in mind, I was able to simplify not only the implementation of the API, but also make the API paths shorter and easier to consume.
Building a User Session
It's important to note a distinction in the types of data we store for a user. You have long-lived and rarely changing data, like username, email, and signUpDate, and you have frequently changing, temporary data like gameId, websocketConnectionId, and signInTime.
These two types of data are pulled from different areas of our application and consolidated into a single UserSession class.

The long-lived data is pulled from the user store. This could be an identity provider (IdP) like Okta or Amazon Cognito, or it could come straight from your database.
The short-lived session data comes from a cache. Since the data here needs to be rebuilt every time the user logs in, we use a service like Momento to set a short time to live (TTL) and expire the data automatically.
The user session infers necessary data for our endpoints. Since the current gameId is kept in the user session, we can remove it from the path of our endpoints and use the stored value instead. This makes the path shorter and removes the need to build multiple validations because we can trust the source of the data. Compare the before and after of the Add Points endpoint.
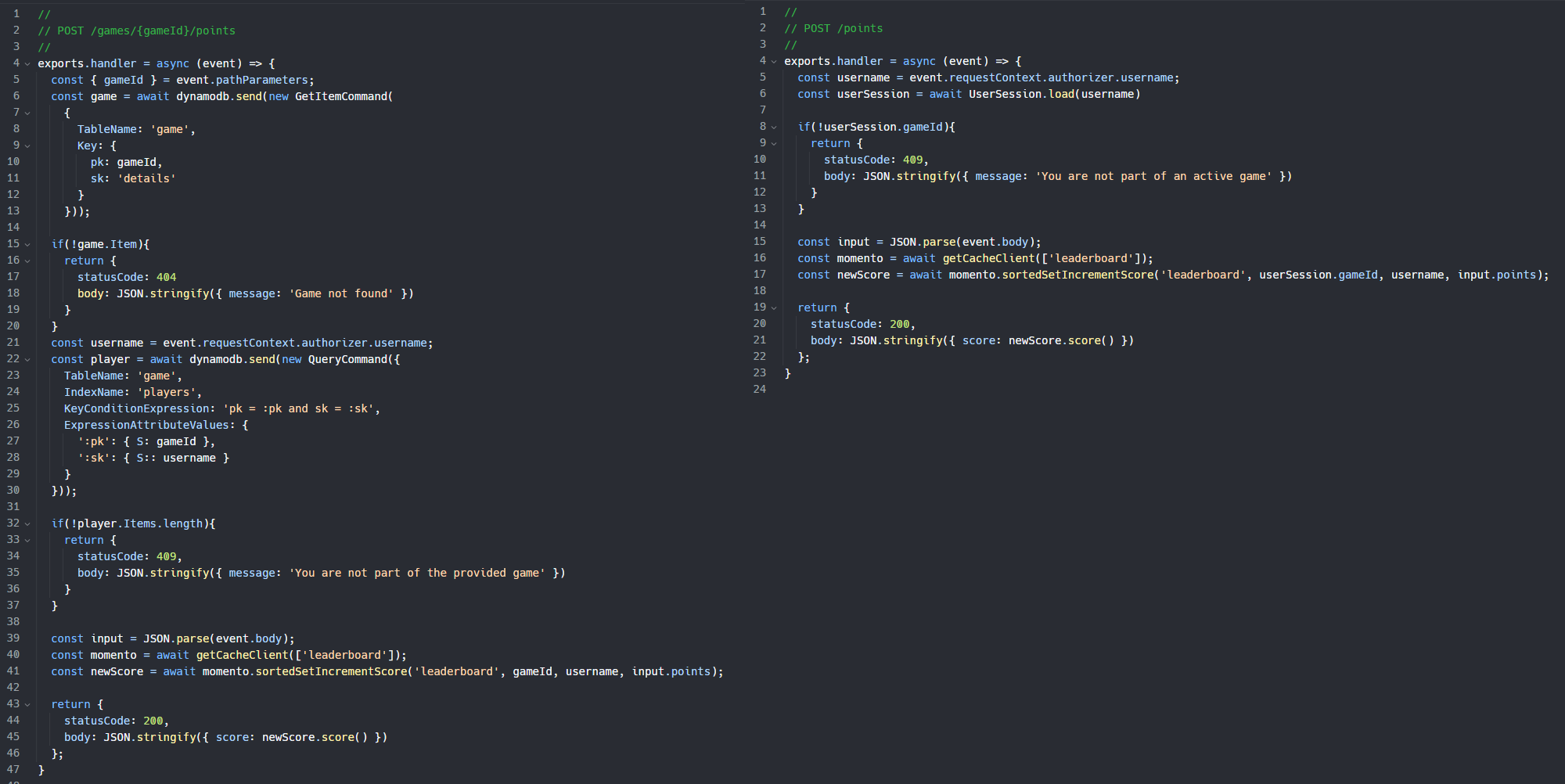
You can see the implementation with the user session has half the lines of code! Since gameId is loaded from our data store, there's no need to validate if the game exists or if the user is a part of it. Trust the data that comes out of your cache and it will make your code less complex and easier to maintain.
Not only do we get the benefit of less code to maintain, but the endpoints are simpler too! We went from POST /games/{gameId}/points to POST /points. This is easier to read and easier to integrate with!
What Data Belongs In A User Session?
After seeing how much simpler our code is, it might be tempting to throw everything in a user session. But that's not always the best idea. User session data is cached and one of the hardest problems in computer science is cache invalidation.
User session data should be frequently accessed and regularly updated data. To identify candidates for session data, take a look at the endpoints in your API. Do you see the same path parameters in most of your calls? Are there constraints around a single "active" parameter or resource? That might be a good candidate for your user session!
Your goal here is to improve developer experience. By shortening your paths and caching data in your handlers, you lower the chances of client-side errors (like providing an invalid gameId) and increase the performance of your app by responding faster.
Let's take some examples from Acorn Hunt. The first pass at my API had the following endpoints:

The majority of the paths started with /games/{gameId}. Each one of them had the same validations in the implementation: does the game exist and is the caller an active player in it? This was a huge indicator that things could be simplified by inferring that data from the user session.
I also found myself passing a WebSocket connection id around in several calls. Whenever a user would send a message, score a point, or move on the screen, the other players in the game needed to be notified of the change. To prevent sending a push notification to the player making the call, I was providing the WebSocket connection in the payload to tell the backend to omit it from the broadcast.
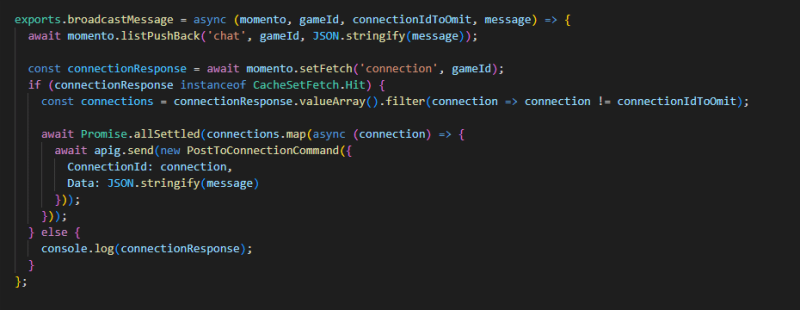
Once I moved the WebSocket connection to the user session, I was able to make the request simpler on the caller and make the application feel like it "just works". Whenever you have a chance to take complexity off your callers - do it. Even if it means significantly more work for you in your backend implementation, it is almost always worth it for the boost in developer experience.
Be Careful With Lambda Authorizers
When building applications with an AWS serverless tech stack, a common pattern is to use a Lambda authorizer for authentication. This feature of API Gateway runs a Lambda function to validate credentials and enrich a user context before running the downstream services behind your endpoints.
An authorizer will validate the incoming token, optionally build a user context, and return an IAM policy with the allowed endpoints the caller can invoke.
I make heavy usage of the user context from authorizers. It loads the long-lived and rarely changing data out of my user store and passes it to the downstream services so I don't have to implement that logic in multiple places. The important thing to note is that the authorizer utilizes its own cache. It caches the user context and policy so the function doesn't need to run every time an endpoint is invoked. This is a great feature to save money and increase performance, but it means you can't put your frequently-changing data in the generated user context.
Load your user sessions in downstream services after the call has been authorized. This enables you to fetch the data from the user session cache every time instead of relying on the authorizer cache. While authorizer caching is a fantastic tool, it's bitten me a few times when I try to fetch data that invalidates more frequently than the authorizer!
Final Thoughts
User sessions are about developer experience. Look for patterns in your APIs that could be abstracted away into a server-side user session. How can you take an ordinary experience and make it magical?
Make meaningfully shorter paths in your APIs. If you have a use case where data can be "active", like an active game, take that as an opportunity to infer resources based on the caller. Save the recent calls to build a context for the user for this time using your app. End users love it when applications remember what they are doing.
Do your best to separate short-lived and long-lived data. Long-lived data doesn't change very often and can be cached for longer amounts of time. This data could even be persisted as entity attributes in your database. Short-lived data is relevant right now. It's captured when you sign in and expires when you sign out.
I've built many APIs where I required the caller to set the context with every API request. They had longer paths to call and were required to pass more data in either as headers or in the request body. But not anymore.
Think about what you can take on as the API developer. What can be saved from call A that can be used to make for a better experience in call B? Throw it in a cache and take advantage of it!
For a hands-on example, check out the source code in GitHub!
Happy coding!

Top comments (0)