Introduction
AWS recently released AWS Lambda Profiler Extension for Java. The Lambda profiler extension allows you to profile your Java functions with high fidelity and no code changes. It uses the async-profiler project to produce profiling data and automatically uploads the data as HTML flame graphs to S3, which can be viewed in the browser.
If you'd like to know more about the async-profiler, you can read these articles:
Or watch this video Profiling Java Applications with the async-profiler.
If you'd like to know more about the flame graphs in general, you can read the collection of resources by Brendan Gregg named Flame Graph, who contributed a lot to this area.
How to build AWS Lambda Profiler Extension for Java
You can follow the instructions on how to build AWS Lambda Profiler Extension for Java here. It uses Gradle for that. I've already built such an extension.zip from the source code (state 19 March 2025) and published it in extension.zip in my aws-lambda-java-profiler repo. So if you'd like to give it a quick try, you can use it.
The Lambda extension zip file contains the profiler-extension.jar, which is the source code of the profile with the subfolder with the name extensions, which contains a file with the name profile-extension, which is by convention the name of the Lambda extension. This file has the following content :
set -euo pipefail
exec -- java -jar /opt/profiler-extension.jar
What happens here is that the extension will be started. Please make sure that the file profile-extension is executable (-rwxr-xr-x).
If you build this extension by yourself, you might run into the issue with the mismatch of the versions of the dependencies. AWS Lambda Java Profiler uses the following dependencies that you might also use in your application, see build.gradle :
- com.amazonaws:aws-lambda-java-core (currently version 1.2.3)
- com.amazonaws:aws-lambda-java-events (currently version 3.11.5)
- software.amazon.awssdk:s3 (currently version 2.31.2)
They also bring other dependencies, like sdk-core.jar, which is in use by other AWS SDK clients like dynamodb. For example, if your application uses a different version of software.amazon.awssdk:bom, you might run into the issue that I described here. In this case, you have different versions of dependencies via the Lambda layer of the extension and the classpath of your application, and the former takes precedence. For now, you can recompile the extension using the same version as your application to solve this problem.
Then you need to publish the extension as a Lambda layer. With AWS CLI, you need to execute the following:
aws lambda publish-layer-version \
--layer-name aws-lambda-java-profiler-layer \
--description "Profiler Layer" \
--license-info "MIT" \
--zip-file fileb://extension.zip \
--compatible-runtimes java11 java17 java21 \
--compatible-architectures "arm64" "x86_64"
You can choose another layer name instead of aws-lambda-java-profiler-layer, but you need to reference it in the IaC of your application later.
Sample application that uses AWS Lambda Profiler Extension for Java
I use my sample application to demonstrate how to configure and use the profiler.

You can find the source code in my aws-lambda-21-with-profiler-sample-project.
To use the profile, you need to do the following steps (also see AWS SAM template):
- Create an S3 Bucket to store the flame graph. In my case, I use an S3 bucket with the name aws-pure-java21-lambda-with-profiler-bucket for it.
- Set the value of the Lambda Function environment variable AWS_LAMBDA_PROFILER_RESULTS_BUCKET_NAME to the name of the created S3 Bucket
- Set the value of the Lambda Function environment variable JAVA_TOOL_OPTIONS to -XX:+UnlockDiagnosticVMOptions -XX:+DebugNonSafepoints -javaagent:/opt/profiler-extension.jar to register the profiler as the java agent
In my AWS SAM template, this part looks like this:
Globals:
Function:
Runtime: java21
....
Environment:
Variables:
AWS_LAMBDA_PROFILER_RESULTS_BUCKET_NAME: aws-pure-java21-lambda-with-profiler-bucket
AWS_LAMBDA_PROFILER_DEBUG: true
JAVA_TOOL_OPTIONS: -XX:+UnlockDiagnosticVMOptions -XX:+DebugNonSafepoints -javaagent:/opt/profiler-extension.jar
- Reference the previously published Lambda extension layer for the Lambda function(s)
- Give those Lambda functions permission to write flame graphs to the S3 bucket
In my AWS SAM template, this part looks for the Lambda function GetProductByIdFunction like this :
GetProductByIdFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: GetProductByIdWithJava21WithProfilerLayer
....
Layers:
- !Sub arn:aws:lambda:${AWS::Region}:${AWS::AccountId}:layer:aws-lambda-java-profiler-layer:15
Handler: software.amazonaws.example.product.handler.GetProductByIdHandler::handleRequest
Policies:
.....
- S3WritePolicy:
BucketName: aws-pure-java21-lambda-with-profiler-bucket
And the same for all other Lambda functions. Please use the Lambda layer name that you used when publishing it (see above, in my case it is aws-lambda-java-profiler-layer) and its correct version number. In my case, it's version number 15, as I experimented quite a bit with it. In your case, it might be version 1.
The following needs to be installed to build and deploy the sample application:
- Java 21, for example Amazon Corretto 21
- Apache Maven
- AWS CLI
- AWS SAM
In order to build the application, execute mvn clean package.
In order to build the application, execute sam deploy -g.
To create the product with id equal to 1, execute
curl -m PUT -d '{ "id": 1, "name": "Print 10x13", "price": 0.15 }' -H "X-API-Key: a6ZbcDefQRW12BN56WEBF7" https://{$API_GATEWAY_URL}/prod/products
To retrieve the product with id equal to 1, execute
curl -H "X-API-Key: a6ZbcDefQRW12BN56WEBF7" https://{$API_GATEWAY_URL}/prod/products/1
During the usage of our application, the flame graphs will be generated in the subfolders of our S3 bucket for each year/months/day for each Lambda function, see the example below:
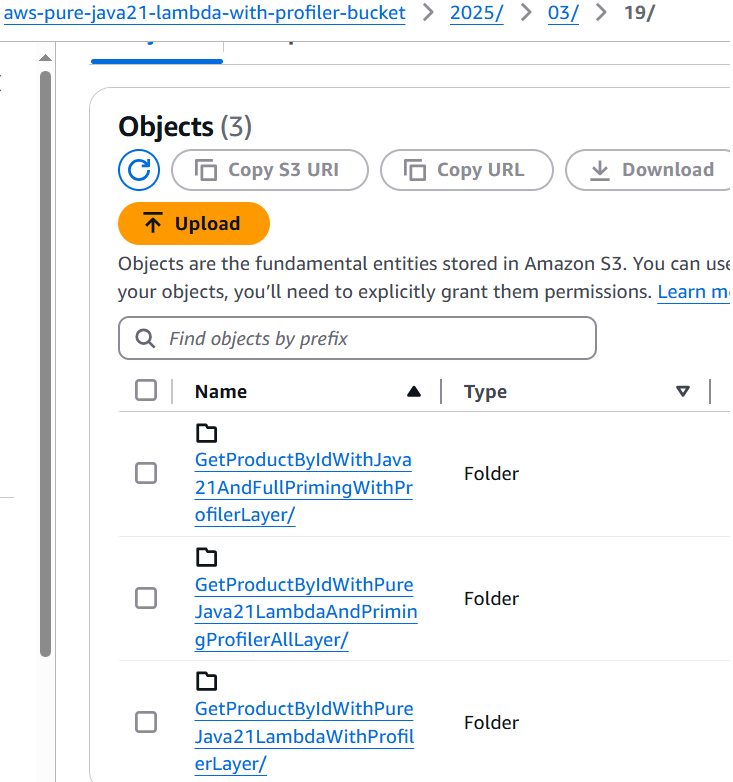
Of course, we'll get the expected flame graphs like this below :
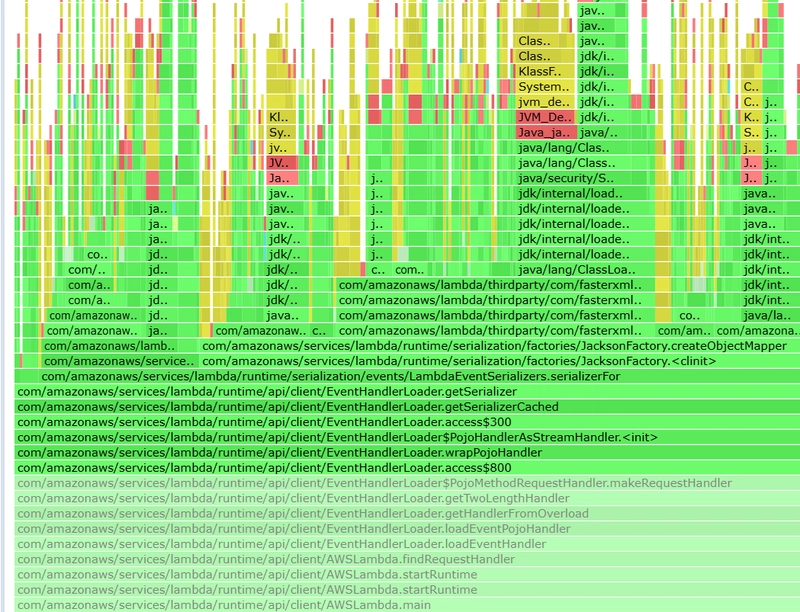
They help us profile our application. The resulting flame graphs use the following colors:
- green is Java
- yellow is C++
- orange is a kernel
- red is the remainder (native user-level, or kernel modules)
I'd like to express my huge gratitude to Maxime David, who helped me to make my examples work by immediately jumping into the investigation of my issues and answering all my questions.
Conclusion
In this article, we introduced the recently released AWS Lambda Profiler Extension for Java. We explored how to build it as a Lambda extension, publish it as a Lambda layer, and use this layer in our sample application.
You've probably already read my article series about AWS Lambda SnaptStart and know that I like to explore SnapStart priming techniques. In the next part of this article series, I'll explain how these flame graphs gave me some ideas about how to prime even more and therefore to reduce the cold starts of the Lambda function. Stay tuned!
Please also check out my website for more technical content and upcoming public speaking activities.

Top comments (0)