Introduction
In part 1 of the series, we introduced the recently released AWS Lambda Profiler Extension for Java. We explored how to build it as a Lambda extension, publish it as a Lambda layer, and use this layer in our sample application. In this article of the series, I'd like to show you how it helped me to improve Lambda performance (especially to reduce Lambda cold start times) by identifying additional Lambda SnapStart priming potential in my sample application.
Setting up a sample application
For this purpose, I reused my sample application to store and retrieve products from the database. I use API Gateway, 2 Lambda functions, and DynamoDB. For the Lambda runtime, I use Corretto Java 21.

You can find the source code in my pure-lambda-21 repo. I only updated dependencies in the pom.xml to use its recent versions.
The following needs to be installed to build and deploy the sample application:
- Java 21, for example Amazon Corretto 21
- Apache Maven
- AWS CLI
- AWS SAM
In order to build the application, execute mvn clean package.
In order to build the application, execute sam deploy -g.
To create the product with id equal to 1, execute
curl -m PUT -d '{ "id": 1, "name": "Print 10x13", "price": 0.15 }' -H "X-API-Key: a6ZbcDefQW12BN56WEV7" https://{$API_GATEWAY_URL}/prod/products
To retrieve the product with id equal to 1, execute
curl -H "X-API-Key: a6ZbcDefQW12BN56WEV7" https://{$API_GATEWAY_URL}/prod/products/1
Lambda SnapStart and Priming
You've probably already read my article series about AWS Lambda SnaptStart and know that I like to explore SnapStart priming techniques.
In the article Measuring priming, end-to-end latency and deployment time, I explained the Lambda SnapStart priming techniques, including DynamoDB request invocation priming.
You can find the source code for it in the class GetProductByIdWithDynamoDBPrimingHandler.
The relevant part of the code is this one :
@Override
public void beforeCheckpoint(org.crac.Context<? extends Resource> context) throws Exception {
productDao.getProduct("0");
}
I additionally instantiated ObjectMapper in the static initializer block of the class.
By executing this code before creating a SnapStart snapshot of the whole Firecracker microVM, we ensure that all classes involved in making a DynamoDB request (basically from the dynamodb artifact from AWS SDK for Java v2) will be loaded, and the HTTP Client (default one is Apache HTTP Client) will be initialized, and Jackson Serializer/Deserializer (ObjectMapper) will be initialized as well. Both are expensive one-time operations for the life cycle of the Lambda function and take several hundred milliseconds on my local notebook. All of these will become a part of the snapshot and will already be there after restoring it. We are not interested in the result of the search by product with id equals to 0. This product may not even exist in the database, as our goal is to prime (initialize) certain invocations and load as many Java classes as possible.
By doing this kind of priming, we could significantly reduce the cold start time of the Lambda function, see my measurement from November 2023 provided in the AWS Lambda SnapStart - Part 9 Measuring Java 21 Lambda cold starts article.
I experimented a lot with different priming techniques for this sample application and tested some small improvements like this one:
@Override
public void beforeCheckpoint(org.crac.Context<? extends Resource> context) throws Exception {
APIGatewayProxyRequestEvent requestEvent = new APIGatewayProxyRequestEvent();
requestEvent.setPathParameters(Map.of("id","0"));
this.handleRequest(requestEvent, new MockLambdaContext());
}
But the cold start remained the same, as additionally creating the instance of the simple APIGatewayProxyRequestEvent class (and this loading the class and all classes it's referencing) and doing a sample request didn't bring much improvement due to the simplicity of this class.
Improving Lambda SnapStart Priming with the help of AWS Lambda Profiler Extension for Java
The question that I was asking myself was how to prime the stuff happening before the handleRequest method of the Lambda function is invoked. What happens when API Gateway invokes the Lambda function is that it sends a huge JSON payload, which then will be deserialized into the APIGatewayProxyRequestEvent object. You can find the example of such JSON here. This task is performed by the AWS Lambda Java Runtime Interface Client in the cold start phase before the concrete Lambda function will be invoked with the payload (in our case, it'sthe APIGatewayProxyRequestEvent object). Dealing with serialization/deserialization might be an expensive task with a lot of one-time initializations. So I thought, can the AWS Lambda profiler extension for Java help me to find how to hook into it without a lot of debugging?
Let's see what profiling revealed to me :
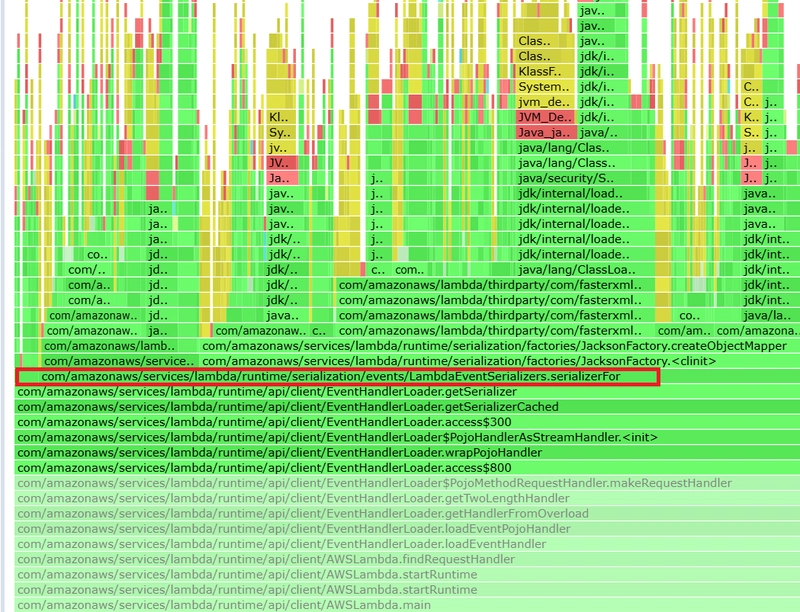
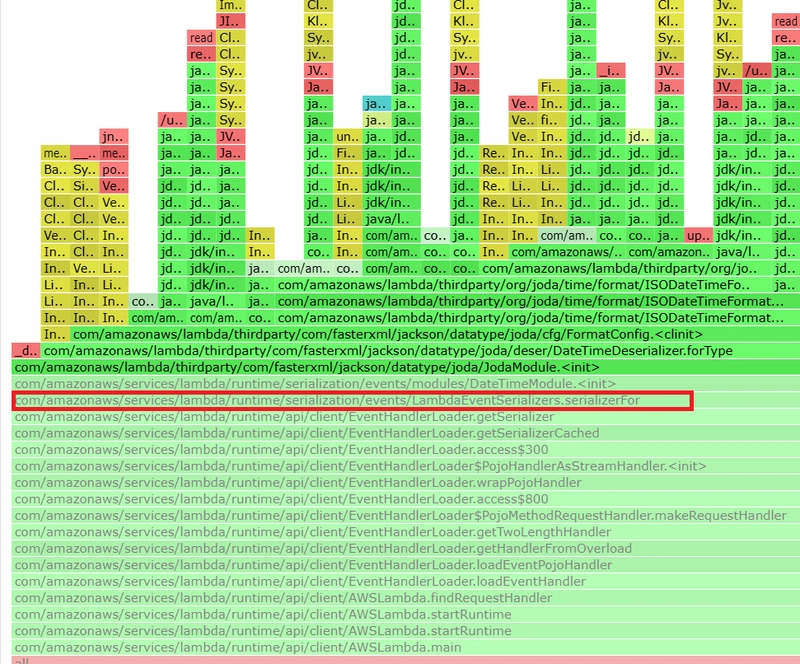
In the first flame graph, we see below the initialization of the EvenHandlerLoader class, but this API seems to be mostly private or protected. But then I saw the LambdaEventSerializers.serializerFor invocation, which (I assume that for my use case, the serialization into APIGatewayProxyRequestEvent will happen there) is public and is a part of the following dependency:
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-serialization</artifactId>
</dependency>
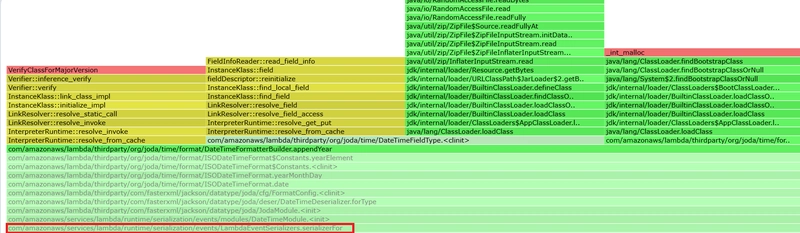
I dove deeper and saw down the chain (flame graphs 2 and 3) and additionally in the source code that many classes will be loaded (mainly from the package com.amazonaws.lambda.thirdparty and its sub packages) and not only APIGatewayProxyRequestEvent serializer, but also Joda DateTime (de)serializers will be instatiated. I also identified that separately packaged com.amazonaws.lambda.thirdparty.com.fasterxml.jackson.databind.ObjectMapper is also instantiated. So, I asked myself, can I prime all this, and came up with the following implementation GetProductByIdWithFullPrimingHandler. Here are the relevant code fragments:
private static String getAPIGatewayProxyRequestEventAsJson() {
final APIGatewayProxyRequestEvent proxyRequestEvent = new APIGatewayProxyRequestEvent ();
proxyRequestEvent.setHttpMethod("GET");
proxyRequestEvent.setPathParameters(Map.of("id","0"));
return objectMapper.writeValueAsString(proxyRequestEvent);
}
Here I created an APIGatewayProxyRequestEvent object and set only the attributes that I access in the handlerRequest method, like path parameters (by invoking requestEvent.getPathParameters().get("id");). You may need to set more depending on your use case, like invoke setBody method on the proxyRequestEvent object for the POST request for creating a new product. Then we converted this object into its JSON representation.
@Override
public void beforeCheckpoint(org.crac.Context<? extends Resource> context) throws Exception {
APIGatewayProxyRequestEvent requestEvent =
LambdaEventSerializers.serializerFor(APIGatewayProxyRequestEvent.class, ClassLoader.getSystemClassLoader())
.fromJson(getAPIGatewayProxyRequestEventAsJson());
this.handleRequest(requestEvent, new MockLambdaContext());
}
This is the code of the initial priming. We use LambdaEventSerializers.seriaizerFor to find and load the serializer for the APIGatewayProxyRequestEvent class. By invoking the fromJson method and passing the JSON representation of the previously constructed APIGatewayProxyRequestEvent, we get back the serialized APIGatewayProxyRequestEvent object. After this, I simply invoke the handleRequest method, which then searches for the product with id 0 and does DynamoDB request invocation priming on top.
It might sound a bit complicated and requires some additional fairly simple code, but anyway, I wanted to measure the impact of it.
You can see the impact of this SnapStart priming on the following flame graphs (starting from GetProductByIdWithFullPrimingHandler.beforeCheckpoint invocation and above):

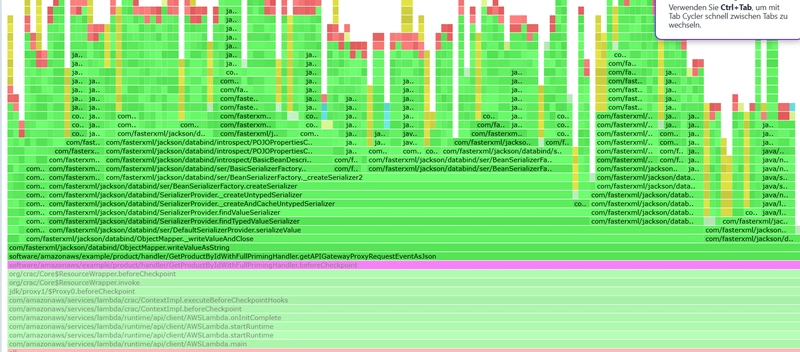
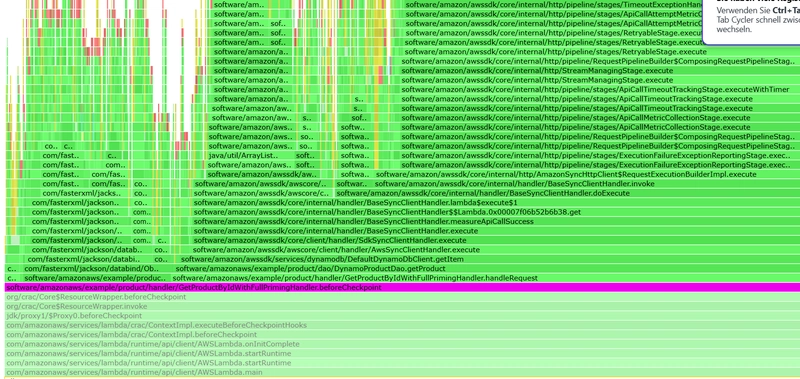
Lambda invocation itself now loads fewer Java classes and does less initialization because everything has been primed, as this flame graph shows:

Measuring cold and warm start time of the AWS Lambda function
The results of the experiment below were also based on reproducing more than 100 cold and approximately 100.000 warm starts with the Lambda function with a 1024 MB memory setting and using the "-XX:+TieredCompilation -XX:TieredStopAtLevel=1" Java compilation option for the duration of 1 hour. The experiments have been performed with the Java Corretto version java:21.v32. For it, I used the load test tool hey, but you can use whatever tool you want, like Serverless-artillery or Postman.
I'd also like to better visualize the effect of the Lambda SnapStart snapshot tiered cache, showing you the performance measurements for all 100 cold starts, but also for the last 70 cold starts, dropping the approximately first 30 slower cold starts. Depending on how often the respective Lambda function is updated and some layers of the cache are invalidated, the Lambda function can experience thousands or tens of thousands of cold starts, so that the first longer-lasting cold starts are no longer significant. You can read more about the effect of the Lambda SnapStart snapshot tiered cache in the article and talk by Mike Danilov AWS Lambda Under the Hood. I also investigated this effect for using pure Java 21 on AWS Lambda in my article AWS SnapStart - Part 17 Impact of the snapshot tiered cache on the cold starts with Java 21.
I will compare cold and warm start times of DynamoDB request invocation priming with (full) APIGatewayProxyRequestEvent priming only.
Cold (c) and warm (w) start time in ms:
| Scenario Description | c p50 | c p75 | c p90 | c p99 | c p99.9 | c max | w p50 | w p75 | w p90 | w p99 | w p99.9 | w max |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SnapStart enabled with DynamoDB invocation priming, all | 812 | 887 | 1336 | 1382 | 1385 | 1386 | 5.47 | 6.21 | 7.27 | 15.09 | 39.75 | 813 |
| SnapStart enabled with DynamoDB invocation priming, last 70 | 789 | 835 | 906 | 1014 | 1014 | 1014 | 5.47 | 6.11 | 7.16 | 15.09 | 37.91 | 416 |
| SnapStart enabled with full APIGatewayProxyRequestEvent priming, all | 642 | 671 | 1207 | 1227 | 1232 | 1241 | 5.64 | 6.30 | 7.27 | 15.50 | 38.45 | 748 |
| SnapStart enabled with full APIGatewayProxyRequestEvent , last 70 | 628 | 652 | 686 | 791 | 791 | 791 | 5.59 | 6.25 | 7.21 | 15.14 | 36.37 | 264 |
| SnapStart enabled with full APIGatewayProxyRequestEvent priming, with provided serialization dependency, all | 623 | 687 | 1228 | 1259 | 1263 | 1263 | 5.38 | 6.01 | 7.16 | 15.83 | 40.39 | 637 |
| SnapStart enabled with full APIGatewayProxyRequestEvent priming, with provided serialization dependency, last 70 | 605 | 626 | 687 | 740 | 740 | 740 | 5.29 | 6.01 | 7.05 | 15.59 | 36.72 | 246 |
Conclusion
In this article, I introduced (full) APIGatewayProxyRequestEvent SnapStart priming and compared its Lambda performance with DynamoDB request invocation priming. We see that the former has consistently lower (up to several hundred milliseconds, depending on the percentile) cold start times, which is quite impressive. Particularly, the effect of the APIGatewayProxyRequestEvent SnapStart priming is noticeable with respect to the SnapStart tiered cache (see the last 70 measurements). The warm start times are nearly the same besides the max values, as the proper priming reduces one-time initialization during the handleRequest method invocation as well. It's up to you to adopt this for your use case or not, because yes, it requires some additional code to be written.
If you don't like to use APIGatewayProxyRequestEvent SnapStart priming, please also remove the dependency on aws-lambda-java-serialization in the pom.xml as it contributes an additional 4 MB to the Lambda deployment artifact size.
There is, for sure, even more potential to find out what to prime, thanks to the flame graphs in general, but also to reduce the cold start time using the above-discussed priming. For example, by using a more complex structure of the JSON API Gateway payload sent to the Lambda function (with more potential to prime things), which will later be serialized into an object of type APIGatewayProxyRequestEvent.
I also don't want to make any general comparisons between these measurements and my measurements from November 2023, provided in the AWS Lambda SnapStart - Part 9 Measuring Java 21 Lambda cold starts article (at least for DynamoDB invocation request priming). The reasons for that are:
- I updated dependencies’ versions and noticed that the Lambda overall deployment artifact size got approx. 10% bigger because of that, which contributes to the additional cold start times.
- Now Lambda uses a different Java Corretto version (java:21.v32). As I measured it in November 2023, it was java:21.v3 or so. Some changes (hopefully improvements) have been possible since then.
- Lambda SnapStart snapshot restore times might have improved since then.
You can apply this type of Lambda SnapStart to any kind of input event (the first parameter of the handleRequest method), see all supported input events in the com.amazonaws.services.lambda.runtime.events package of the aws-lambda-java-events dependency.
Update from 14 April 2025: You can find the Lambda performance measurements using the introduced Lambda SnapStart Priming technique with the different Lambda memory settings in this article.
Update from 7 July 2025
I discovered that the aws-lambda-java-serialization dependency is also provided by the AWS Lambda Java Runtime Interface Client, so we can set its scope to provided like this :
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-serialization</artifactId>
<version>1.1.5</version>
<scope>provided</scope>
</dependency>
With this, we'll reduce the deployment artifact size by 4.5 MBs. In the measurements above for "SnapStart enabled with full APIGatewayProxyRequestEvent priming". We initially provided the results without setting the scope to the "provided" only. Now we added those with scope set to provided (see explicit "with provided serialization dependency" in the scenario description above) and see slightly lower Lambda cold and warm start times by not packaging aws-lambda-java-serialization dependency in the deployment artifact comparing to the initial measurements when we packaged aws-lambda-java-serialization dependency.
Please also check out my website for more technical content and upcoming public speaking activities.

Top comments (0)