
Documentation has been one of the earliest fields to see large changes due to ChatGPT, and more recently GPT-4. Especially technical documentation, being in the intersection of AI-tinkerers (programmers) and written content, has seen a lot of movement. We've seen experiments in generating documentation, new ways of interacting with documentation, and lots of people wondering what the future will look like.
We at Doctave are, for obvious reasons, looking at this space carefully. In this post will take a look at the AI-powered documentation landscape: what we have seen work and not work so far. And finally, we will make some guesses about what the future holds.
Disclaimer: Things are moving fast
I am writing this in mid-May of 2023. The pace of change in AI means that the opinions and statements of fact in this piece may be out of date very quickly.
As an example, less than a week ago, as of time of writing, Anthropic announced 100K context windows for their Claude model: equivalent to around 75,000 words. This may already change the dynamics discussed in this post when released to the public.
This post will also only focus on AI in the context of (technical) documentation, instead of AI capabilities broadly, which should not be underestimated.
It's important to stay humble when things are moving this fast.
What we've seen so far
AI applied to documentation has touched how we both read and write documentation.
On the writing side, OpenAI's Codex model, powering GitHub Copilot, has turned out to be great at understanding what a piece of source code is doing and producing documentation at least at the function level. ChatGPT has also proved to be a valuable tool for expanding, rewording, or editing any type of prose: including documentation.
On the reading side, companies have started adding AI-powered chat interfaces to their docs. And for popular tools you can even get ChatGPT to tell you the incantation you need without having to even look at the docs.
These are just the earliest experiments, but let's dive into them a bit.
AI-powered documentation chat
Chat interfaces powered by OpenAI's API was one of the first things people started playing with. It was an obvious leap from the ChatGPT interface: what if you could have a discussion with an AI that knows everything about your documentation?
As far as I can tell, Supabase was the first large company to add such an interface (aptly named "Clippy") to their developer documentation:
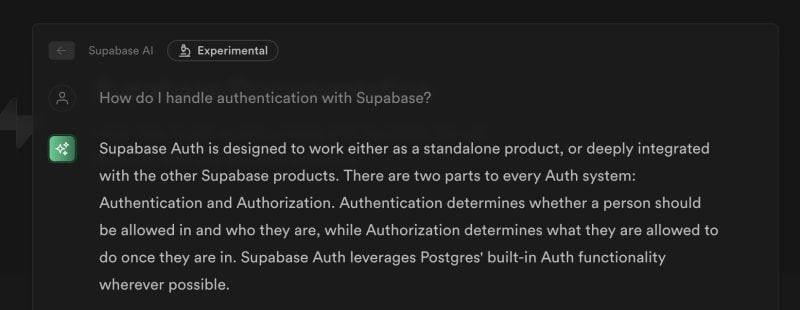
Since then, a long list of companies have built such interfaces for their documentation. Similarly, companies providing documentation platforms have added such features to their offering. Not only that, there are companies whose whole business is building chat interfaces over whatever content you can throw at them: be it technical documentation, CRM content, or sales meeting transcripts.
How do they work?
These chat interfaces are quite straightforward to build these days. In fact, OpenAI has a guide on how to build them in their documentation.
- Split your content into topical sections
- Create embeddings with OpenAI for your sections
- Index your embeddings in a database (Postgres works great, but this use case among others has caused an explosion in vector database startups).
- Create an embedding for your user's question through OpenAI
- Run a query against your embeddings to find the ones that are the closest matches with the question's embedding. (Embeddings are arrays of numbers, so it is possible to compute a "distance" between different embeddings).
- Include the closest matches as "context" for your final OpenAI completion call, followed by your user's query
What is the experience like?
Having tried out a number of the customised documentation chat interfaces so far, the experience has been slightly underwhelming. Especially considering the incredible success of ChatGPT, it was surprising to find that these chat interfaces for documentation seemed to be less helpful than traditional search.
We think there are two main issues with these documentation chat interfaces:
- Speed of answering
- Accuracy and helpfulness
Both of these issues seem to be preventing chat interfaces from being the 10x improvement we can imagine them being at the moment.
Call me when you're done
If you have not done so yet, I encourage you to try using a chat interface for a documentation site. What you will find is that it is painfully slow.
While the GPT-3.5 model can be incredibly fast today, for documentation you likely want to use the most powerful GPT-4 based model, which is just plain slow. You can end up waiting for even up to a minute for the AI to complete its response.
We have decades of experience building search engines that understand spelling mistakes, synonyms, and work in milliseconds. Going to a system that takes 10s of seconds to surface more or less the same information seems like a step backwards.
But, this is absolutely a short-term problem.
We have no doubt that OpenAI (and competitors?) will improve their algorithms, computational power will increase, and these models will become faster over time. But for now, we only have painfully slow assistants that make you think "forget it, I'll do it myself".
Trust issues
Speed would not be a problem if the answers these systems produced were stellar. But the responses have not reached the helpfulness expected of ChatGPT.
At the heart of this, we believe, are hallucinations. Hallucinations have been a well-known problem from the day ChatGPT was launched. In short: AIs will make things up.
Luckily, hallucinations have not been a huge issue with documentation chat AIs. Likely because they tend to set their temperature to, or close to 0. Temperature, in OpenAI's terminology, means how "random" the answer will be. From their documentation:
Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
With a low temperature the answers seem to stick to the truth and be quick to say "I don't know" if it cannot find an answer in its provided context. Documentation is an area where incorrect answers can cause a lot of frustration. Since there isn't a human in the loop verifying the answers of these chat interfaces, companies tend to be conservative in the responses they want their AI to give.
Still, in our testing we have seen documentation AIs produce bogus information. Supabase for this reason has the following disclaimer:

The unfortunate net effect is that the answers are...bland. Low temperatures mean the model is unable to fill gaps in your documentation and reason about how your product works.
To give an example, asking one of these documentation assistants if the tool they describe has a Ruby client, when it doesn't, will most of the time cause it to respond with "I don't know", instead of the more helpful "We don't have a Ruby client, but we do have official API wrappers in X, Y and Z languages".
If the context the AI is provided does not verbatim have the information it needs to respond, it will not be able to give an answer. At which point, is this really better than search yet?
Unlike with the speed issue, hallucinations and accuracy are problems that we have zero solutions for. We have no idea how to stop Large Language Models (LLMs) from lying, which does not bode well for AI alignment overall. It remains to be seen if we can thread the line between a system that can only repeat almost verbatim what is found in your content, and a more helpful assistant that is able to correctly infer more information from your documentation.
Obvious potential
It is easy to imagine how having a GPT-4 level chat assistant trained on your documentation could be incredibly useful. It could personalise examples on demand, write customised tutorials, and infer how to use your product from e.g. your OpenAPI specifications and documentation.
Imagine being new to a library or product, telling an LLM you are familiar with XYZ technologies, and creating a customised learning path for you to get started based on techniques and technologies you already understand.
Currently we have not seen this become a reality.
In our experience, it is faster and more convenient to use traditional search and skim through documentation yourself to find the answers you are looking for.
Interestingly, it is not possible for anyone but OpenAI (or its competitors) to fix these issues. All those startups built around making chat interfaces for your content will have to wait until the state of the art moves forward.
That being said, we look forward to revisiting this opinion in 3 days months!
Generating documentation
Ok, we started with the reading part. What about writing documentation? Here we see AI being much more helpful today and already making the lives of developers and technical writers easier.
(We will focus mostly on long-form technical writing here, instead of e.g. generating docstrings for your functions, which also works great.)
We have seen companies like Jasper pop up to help with AI-powered content generation (built on OpenAI, naturally), but Notion was one of the first companies to integrate OpenAI's models into their own product. In Notion, the AI is an assistant: summarising, rewording, and improving your content on demand.
AI-assisted technical writing
All writing jobs were changed the moment ChatGPT was released. Documentation is no different. Assuming AI models don't take over technical writing completely (we'd likely have bigger disruptions at that point), how can we use AIs effectively in technical writing?
There are some obvious cases that you can achieve even with just using the Chat GPT interface today:
- Summarising or expanding text
- Simplify or clarify your writing
- Maintaining a consistent tone of voice
- Generating guides from API references
- Format Markdown tables for us...
But can we do better? What could the future have in store?
Customised learning paths
We often come back to this diagram (source) when thinking about structuring documentation:

The idea is that your documentation should try to cover all 4 aspects:
- Tutorials: for new users to learn the basics of your product
- How-to guides: for users trying to solve specific problems
- Explanations: to help users better understand the concepts behind your product
- References: for describing low level details of the system
Where we see a lot of opportunities for LLMs to help are with the first 3 sections.
LLMs could help produce more specialised how-to guides and tutorials than human writers can. Not only that, you could create multiple versions of the same guide that match the background of the reader.
You have a Ruby background? Here is a Rust tutorial tailored for a Ruby programmer. Familiar with MySQL? Here is a MongoDB tutorial that explains its usage in terms you already understand.
The reference is also an interesting case. You may have OpenAPI specifications or type signatures that describe the low level workings of your system. Well annotated references can be a great starting point for an LLM to start understanding how your product works in order for it to produce accurate and helpful content.
How does the AI know?
All of the above implies that the LLM understands how your product/tool/library works. How does it gain that knowledge?
Currently, the only way is through, wait for it... documentation!
Ironically, it is the quality of your documentation that will determine if an LLM can be a useful assistant for your product or not. Current techniques, as described above, require you to ship your documentation to the LLM in order for it to generate its response. If your prompt is poor quality, the LLM is going to do a poor job.
This feels like a chicken-or-egg problem, but ultimately means that you cannot escape writing documentation. What is more likely is writers providing LLMs the context they need to assist in the generation of documentation: through annotated API specifications like OpenAPI or GraphQL, or longer written guides.
This is of course another area of great uncertainty. Perhaps someone will create a system that lets LLMs interact with your tool to learn how it works? Or, could the model eventually understand your product by simply reading its source code? There are movements in both these directions, but it is too early to say if these experiments pan out.
Making your documentation "AI Ready"
Anyone who claims they can see how the world will pan out is likely incredibly naive. But that never stopped anyone from speculating!
It remains to be seen if chat interfaces will be useful, or simply a fad in the beginning of the AI revolution. Or if they do remain, where will the chatting happen?
OpenAI announced ChatGPT Plugins in March 2023, which let ChatGPT fetch information from external live data sources. Now you have one powerful LLM that is able to integrate with other tools and services.
Will people be using multiple AI chat assistants, e.g. one per service, or just a single main assistant that knows how to talk to various data sources?
Perhaps it will make more sense for your documentation to be "AI-ready", instead of you building your own chat interface. The task of the technical writer would be to ensure both humans and AIs are able to interact with the documentation in an effective way.
Regardless, what is quite probable is best practices emerging around how to make your documentation easily digestible by LLMs.
What to look out for in the future
This is all incredibly speculative, and we live in a strange time. Depending on who you ask, we should be worried, or incredibly excited for a beautiful future where AIs make our world a better place. Documentation is a tiny part of this broader discussion, but it is interesting because it sits in the nexus of people playing with AI and written content. Things are moving fast.
There are a few things to keep an eye on going forward:
- When will GPT-4 or equivalent models become significantly faster?
- Will we get better at limiting hallucinations allowing for more creative but accurate AI assistants?
- Will we end up using one or more AI assistants?
One thing seems clear for now: you still need to write the docs.

Top comments (0)