
Hey peeps,
I sat down with Amy Heineike, AI engineer at Tessl.io, to discuss her work in evaluating which models excel at AI Native development.
tl;dr “Why is this important for developers?”
- Building complex AI-generated modules and packages remains a non-trivial challenge, but we are getting closer than ever to true AI Native development.
- o3-mini is a hidden gem that hasn’t gained much traction in developer circles yet. If you’re building AI-powered development tools, this model is a contender worth serious consideration.
- Tessl’s AI Engineering team’s initial findings highlight o3-mini’s superiority in building complex, multi-layered systems.
- We don’t see a single model serving all use cases. Instead, the key lies in identifying and leveraging the strengths of different models at each step of the AI Native development workflow.
The challenge of AI Native development
Building AI Native development is a challenge that demands precision. Success hinges on integrating code understanding, specification-to-code translation, intelligent code generation, and automated testing across multiple modules. Beyond OpenAI’s insights on o3-mini’s coding performance (see below), there’s a shared sentiment in the developer community about its effectiveness. For example, Simon Willison noted his surprise at o3-mini’s ability to generate programs that solve novel tasks, as well as its strength in producing documentation.
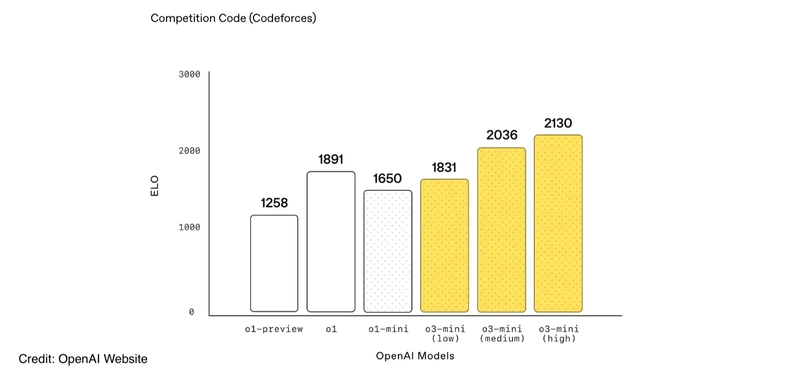
However, within AI Native development, each layer introduces new complexities, requiring models to not only generate functional code but also understand dependencies, adapt to evolving specifications, and self-correct through testing. Traditional approaches struggle with this level of integration, making it clear that AI Native development demands a fundamentally different paradigm.
Advancements in reasoning models, from the early “chain-of-thought” approach to “hybrid reasoning” in Claude 3.7, make this an exciting time for tackling these complex problems. Tessl’s AI engineering team built an evaluation framework that enables continuous testing of new models as they are released. When GPT-4.5 launched with their “last non-chain-of-thought model”, the team assessed which models best suited their use case.
Comparing o3-mini vs GPT 4.5—Tessl’s approach
Tessl, focused on AI Native development, initially had its generation process use GPT-4o for most tasks, but transitioned to o3-mini after it demonstrated stronger performance. With the release of GPT-4.5, and its claims of producing more accurate responses and less hallucination, the team conducted a comparative analysis to assess its performance against o3-mini.
The evaluation process involved testing the model’s ability to generate complete, working, multi-module packages. Each package represented a distinct coding challenge, such as implementing a calculator, performing color transformations, or creating a spreadsheet engine.
The task focused on key capabilities they were testing within AI Native Development:
- Code understanding
- Code generation
- Translating specifications into code
- Debugging and error resolution
- Test case generation
The results provided meaningful insights.
Initially, the team left GPT-4.5 and o3-mini to generate their own test cases, and o3-mini demonstrated a significantly higher pass rate. However, to ensure a fair comparison, the team standardised the evaluation by using test specifications and cases generated by o3-mini for both models. With this apples-to-apples comparison, o3-mini still proved to be significantly stronger in their internal pass rate benchmarks.
Our findings align with OpenAI’s statement that GPT-4.5 is “showing strong capabilities in […] multi-step coding workflows”. However, in this context, o3-mini ultimately proved to be a better fit for Tessl’s AI Native development use case. These findings resonate fairly well with SWE-bench (a known benchmark for evaluating models on issues collected from GitHub—see below).
Worth noting: Within Tessl’s benchmark case, the team didn’t see enough evidence to suggest that GPT-4.5. outperformed GPT-4o—an interesting signal given the much higher cost of GPT-4.5.
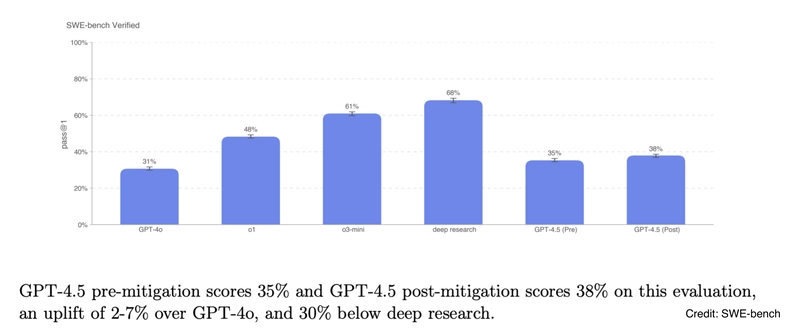
Ultimately, the most interesting insights lie between the lines.
OpenAI has found that the model performed well on some coding benchmarks, suggesting that it might do better on certain subtasks—perhaps those more aligned with the emotional intelligence they tout. Perhaps the fact that GPT-4.5 organically generated more tests hints at this. This raises compelling questions:
- Were GPT-4.5 generated tests superior?
- Could GPT-4.5 be better suited for test generation rather than code creation?
- Would it be more effective to leverage GPT-4.5 for specific aspects of AI Native development rather than applying it universally?
Implication for the Future of AI Native Development
Model advancements are reshaping development workflows, making AI-driven coding a more practical reality. These early results could push more AI-powered dev tools to integrate models like o3-mini as its model improvements are dramatically changing development workflows.
“o3-mini has really been a step change for us. It avoids many small compounding errors that have tripped up other models. It is making well-considered code that suddenly makes it feel like we’re a lot closer to the AI Native future. It’s especially exciting that this jump has come from post-training because there’s so much opportunity for further gains here.” Amy Heineike, AI Engineer at Tessl
That said, should we explore further model pairing experiments—where one model (potentially o3-mini at this stage) manages the overarching system architecture while another refines the finer details? We believe the future of AI Native development lies in leveraging multiple models, stacked on top of one another, each optimised for a specific stage of the development workflow. Just as a hammer and a screwdriver can both put a screw in place—but with different levels of effort and precision—different models excel in different roles within the development process.
For instance, GPT-4.5 is known for its human-like writing, while o3-mini excels in coding output. Could o3-mini generate the code while GPT-4.5 refines and explains it in a more natural way? What role does each model play in this complex puzzle? And which pairings create the most effective AI Native development stack?
We’re still in the early days of AI Native development, and the possibilities ahead are exciting. Let’s explore, build, and learn together. What models are you using? What evals are you running? What insights have you unearthed? We will be looking into this in more detail at the 2025 AI Native DevCon event. If you’re interested in AI Native development, emerging trends, and how to stay ahead in this fast-moving space, join us!
Plus, be part of the conversation—join our AI Native Development community on Discord.

Top comments (1)
I’d love to learn more about your use cases with o3 and which alternative models have proven successful in your attempt to build AI-native development.