
Índice
Si quieres ir directamente al grano, pasa al apartado de Espacios de memoria en Java.
- 1. Una nueva era
- 2. El reto
- 3. El síntoma
- 4. Conceptos sobre memoria
- 5. Espacios de memoria en Java
- 6. Espacios pequeños
- 7. Native Memory Tracking
- 8. Conclusiones intermedias. Y seguimos
- 9. Malloc y fragmentación
- 10. Buffers y Direct Memory Allocation
- 11. Threads, Buffers y Arenas
- 12. Soluciones
- 13. Soluciones "alternativas"
- 14. La fórmula para calcular la memoria
- 14. Conclusiones finales
- 15. Referencias y herramientas
1. Una nueva era (y Java sobrevive)
En la era de los contenedores y ascenso de soluciones cloud, no fueron pocos los que dieron por hecho la caída de Java como lenguaje predilecto de backend (dejo al margen Cobol o Natural, los lenguajes de mainframe, eso es otro universo paralelo). Incluso predijeron su final, una muerte lenta como una estrella de neutrones en la fase final de su vida.
En general, podemos afirmar que se equivocaron. Si bien es cierto que perdió su hegemonía, más de la una década después, Java sigue siempre en los puestos altos de cualquier ranking. Y en el podio, muchas veces en la primera posición, si hablamos de soluciones empresariales a gran escala y con grandes cargas transaccionales.
Sin duda, hay al menos dos factores que contribuyen a su posicionamiento en el universo cloud. En primer lugar, está la existencia de frameworks de desarrollo como Spring, o su hermano pequeño Quarkus (cada vez menos pequeño). Estos permiten la implementación de soluciones empresariales complejas, con un alto nivel de madurez, capacidades de integración con todo tipo de middlewares, interoperabilidad, y una enorme y solvente comunidad detrás de ellos. En segundo lugar, tenemos el auge de las arquitecturas de microservicios, impulsado con fuerza por la aparición de los orquestadores de contenedores. La adaptación de Spring como Spring Boot, y el propio crecimiento de Quarkus y Micronaut como frameworks de microservicios (y el declive del pionero y divertido framework de Netflix) sostuvieron la comunidad Java en este bosque oscuro, hostil y despiadado, del nuevo universo cloud recién descubierto.
Parece lógico después de todo. Las arquitecturas empresariales requieren soluciones sólidas, seguras, escalables y eficientes. Las arquitecturas de microservicios aún más, ya que introducen varios grados adicionales de complejidad y nuevos retos: resiliencia, eventos, orquestación/coreografía, fault tolerance, amén de la explosión de patrones CQRS y CDC, entre muchos otros. Sólo frameworks maduros, sólidos y muy ricos en funcionalidad pueden aguantar este envite.
Pero dejemos ya la evolución de los lenguajes en el mundo cloud, eso sin duda da para otro post, o una saga completa sobre el tema. Java sobrevivió, y los javeros tenemos un nuevo e importante reto, que es meter nuestras soluciones Java en contenedores. Vamos a ello.
2. Java en contenedores, un auténtico reto
Ejecutar cargas basadas en la máquina virtual Java (JVM a partir de ahora), corriendo en contenedores, no es una tarea sencilla. ¿Cuántos contenedores han caído, caen y seguirán cayendo en entornos productivos con códigos de error por OOMKilled (Out of Memory Killed) en entornos Kubernetes? Siguiendo las metáforas sobre el universo, incontables como las estrellas. Bueno, vale, no tantos, pero muchos. Seguro que más de lo deseado.
En los siguientes apartados vamos a explorar este reto en profundidad, y vamos a dar soluciones al mismo... ¡al menos eso espero!
Las entrañas de la máquina virtual Java y su Java Memory Model (JMM) son poco conocidas, incluso entre la comunidad javera, o entre los operadores de sistemas al cargo de los sistemas productivos. En parte esto era "lógico" antes de la era de los contenedores, ya que la ejecución de JVMs en máquinas virtuales o hosts, donde había un amplio margen para el alojamiento de memoria off-heap, hacía que los developers no tuvieran que preocuparse demasiado por estos problemas. Porque sí, es cierto: la JVM aloja grandes cantidades de memoria off-heap, más grandes que el heap en la mayoría de las ocasiones, de las que no somos conscientes. Estos hosts tienen a su disposición grandes cantidades de memoria (reservadas para el sistema operativo, jeje). Los grandes clústeres de servidores de aplicaciones JEE como WebSphere o JBoss son un claro ejemplo. Cada nodo de esos clústers son máquinas virtuales o hosts (bare metal) donde menos de la mitad de la memoria era para los servidores de aplicaciones, y el resto para el sistema operativo. O eso creían. La observación del consumo de memoria de estos sistemas, sin embargo, ofrecía que los consumos de los procesos de las JVM eran siempre más altos de los esperado. Primer síntoma de la memoria oscura... Las soluciones entonces eran simples: pongo más memoria a los hosts y listo. O un reinicio programado de los diferentes nodos del clúster un par de veces por semana, lo que mágicamente liberaba memoria que teóricamente no debería ser tan alta.
Cuando pasamos de una máquina virtual o host, a un universo mucho más limitado en recursos como son los contenedores, los problemas crecen. En un contenedor, el host es el propio contenedor, y está restringido por los límites del mismo. Los límites de memoria de un contenedor son importantes, y tienden a ser mínimos. Es decir, la talla de memoria de mi contenedor debe ser la mínima posible para ejecutar el proceso Java, para dejar recursos a los otros contenedores del ecosistema. No podemos levantar contenedores tan grandes, hablando de memoria, como los antiguos hosts, sería un desperdicio enorme de recursos. Así que levantamos contenedores pequeños. Y ahí es donde se hacen evidentes las necesidades de ajuste fino de los procesos Java. Los contenedores se caen por falta de memoria, pero no por el conocido heap, sino por el desconocido y difícil de observar off-heap.
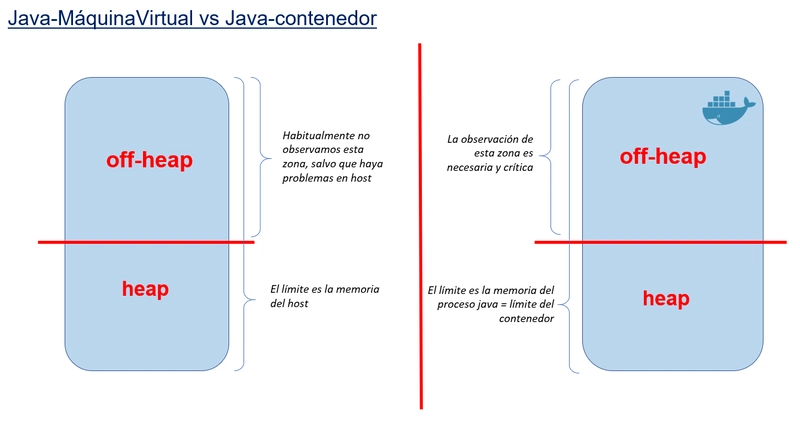
Vamos a llamar a esta memoria, la memoria oscura, que da título a este post. Como la materia oscura del universo, está ahí, interactúa con la materia visible y en conjunto explican el funcionamiento del universo, es decir, de nuestros contenedores.
Vamos a adentrarnos en la zona oscura...
3. El síntoma de la memoria oscura
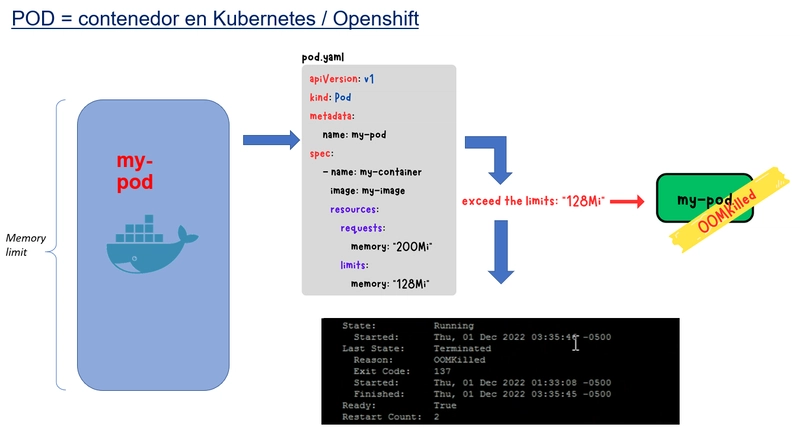
Vamos a suponer que nuestros contenedores se ejecutan en algún orquestador de contenedores. Este será el caso de cualquier sistema productivo "serio" basado en contenedores. A día de hoy ese orquestador será Kubernetes en algunos de sus sabores y colores (Openshift, EKS, AKS, GKS...). Dejamos para otro día la batalla de los orquestadores, que sin duda nos daría para otro post (me lo apunto, ya van dos...). Nuestros contenedores en kubernetes, se incluyen en otro tipo de contenedor que son los PODs, que pueden tener uno o varios contenedores. Para simplificar, durante el resto del post vamos asumir que nuestro contenedor con JVM, es el único contenedor de un POD.
Cuando la memoria oscura de la JVM desborda los límites establecidos para el contenedor/POD, obtendremos el archiconocido error OOMKilled, con código de salida 137. Os suena ¿verdad? Para ilustrarlo de forma sencilla En la imagen de arriba, he forzado un contenedor cuyo limit está por debajo del request, lo que hace que el contenedor muera nada más arrancar. El request es la memoria mínima que declaramos para arrancar, y el limit es la memoria máxima hasta la que permitimos expandirse nuestro contenedor.
El orquestador intentará levantar varias veces el contenedor, no lo conseguirá y se rendirá después de cinco o seis intentos.
Divertido de observar... e ilustrativo. En un espacio de tiempo mucho más reducido, esto es lo que pasa con nuestros contenedores expuestos a la memoria oscura. En la vida real tardaremos mucho más tiempo en notar los efectos OOMKilled, quizá minutos, horas, o días en el mejor de los casos, pero seguro que aparecerán.
4. Conceptos básicos: memoria virtual, residente y nativa
Empieza un poco de clase teórica, es inevitable... pero lo haremos rápido.
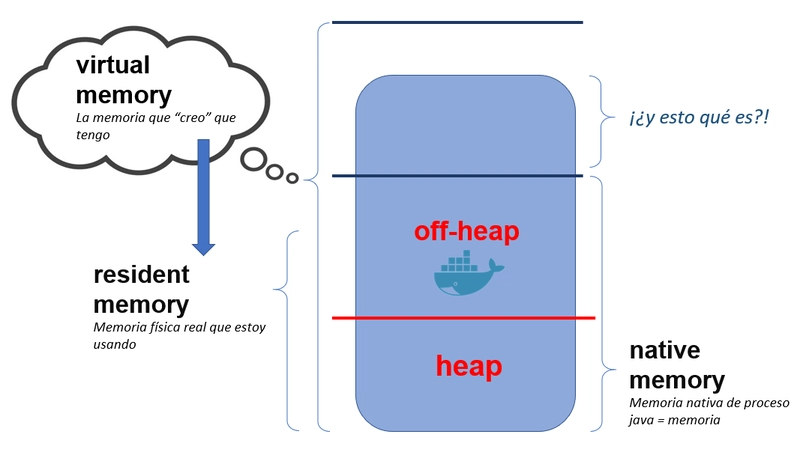
Todo contenedor en ejecución es un proceso Linux. Ok, sí, es cierto: existen los contenedores windows, pero vamos a obviarlos (ese post lo dejo para otro valiente).
Bien, pues todo proceso Linux, hablando de su memoria, tiene la misma pinta. Repasemos algunos conceptos que utilizaremos como referencia durante el post:
La memoria virtual, es la cantidad de memoria que un proceso "piensa" que tiene a su disposición. Y no está limitado por el mundo real. Es decir, que el tamaño de la memoria física real, ya sea la del host o la del contenedor (limit) no influye en la reserva de este espacio cuando un proceso arranca. En el mundo de los contenedores y Java, la memoria virtual puede (y suele) ser mayor que el límite del propio contenedor.
La memoria residente (RSS en muchas métricas como las de Prometheus), es la memoria física real que un proceso se reserva. Puede estar siendo utilizada, o no. Aquí aparece el concepto de memoria comiteada, que es la memoria física real utilizada.
La memoria nativa, es la memoria utilizada por mi proceso. Simplificando, es igual a la RSS (con algunos matices importantes). Introducimos aquí este concepto porque suele causar controversia. Muchos llaman memoria nativa a todo los que no es heap. Otros usan este término para referirse a la memoria residente que no es ni heap ni off-heap, pervirtiendo así la definición de off-heap. En la imagen, sería ese espacio encima del off-heap. De todo esto hablaremos en profundidad enseguida.
Por ahora, para tratar de mantener un lenguaje ubicuo y simple, nos referiremos a los términos de arriba. Virtual, y residente=nativa. Y dentro de la nativa, heap y off-heap en un proceso Java. Mis disculpas por adelantado si yo mismo me salto estas reglas más adelante, intentaré no hacerlo....
De estas definiciones, seguro que surgen rápidamente varias preguntas para el lector. Vamos a dar las respuestas rápidas, y los detalles vendrán después en las siguientes secciones.
- ¿Puedo tener más memoria virtual que física? Sí
- ¿Puedo tener más memoria virtual que residente? Sí
- ¿Puedo limitar las memorias virtuales y físicas? Sí
- ¿Puedo medir las memorias virtuales y físicas? Sí
5. Espacios de memoria Java
La memoria de nuestro proceso Java, es decir de la JVM que ejecuta nuestra aplicación Java, según la especificación JMM (Java Memory Model), se divide en "espacios". Casi toda, porque hay otras zonas de memoria que no siguen esta regla, y que abordaremos más adelante. Por ahora nos quedamos con este concepto de espacio de memoria.
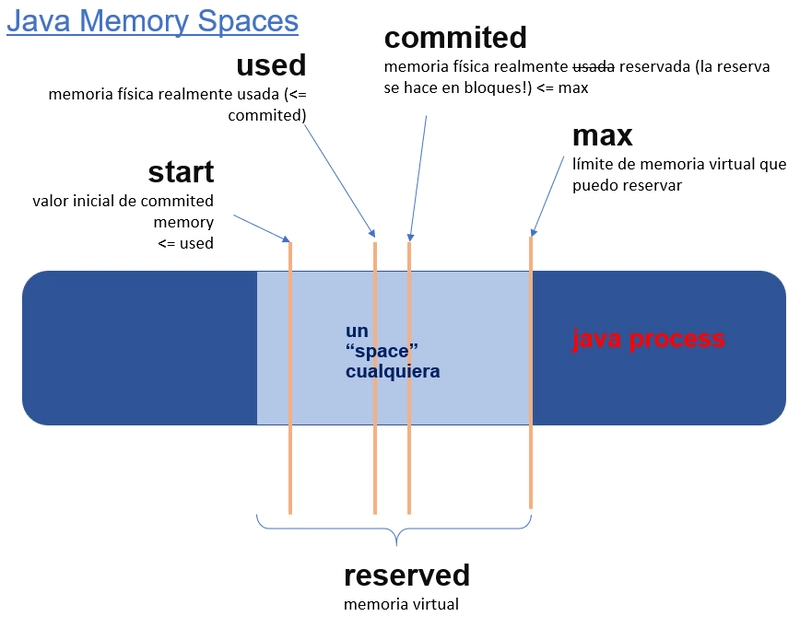
Hay muchos espacios en la JVM, pero todos siguen las mismas reglas respecto a su dimensionamiento y uso:
Existe un límite máximo de tamaño de espacio, llamado max. Este valor indica el tamaño de la memoria virtual reservada en ese espacio.
El proceso en ejecución irá "llenando" ese espacio virtual con memoria física, esto es, comiteando páginas físicas de memoria. Este valor es la memoria física real usada por el espacio, es decir, la memoria residente (RSS).
La memoria comiteada se reserva por bloques. Esto quiere decir que si mi proceso necesita 1MB "real" de memoria física, y el espacio no tiene el tamaño suficiente para alojarlo, el proceso reservará un bloque que será mayor, pongamos 20MB. Estos 20MB se comitean como bloque, aunque de esos 20MB, sólo está usando 1MG. Si inmediatamente después el proceso necesita alojar otro MB, este ya cabe en el bloque comiteado anteriormente y no habrá necesidad de comitear más espacio. Esta es la diferencia entre lo que las métricas nos muestran como commited y used dentro de un espacio. Commited es la memoria física comiteada en grandes bloques. Used es la memoria realmente usada dentro de esos bloques comiteados. Por lo tanto used será siempre menor que commited, y a su vez commited menor que max.
Por último, es posible, aunque no obligatorio, que un espacio tenga un valor min o start. Este valor indica el valor mínimo de memoria comiteada (residente) con el que se crea un espacio. Podríamos decir que es equivalente en concepto al request de un POD/contenedor.
De nuevo, seguro que se disparan muchas preguntas en la mente del lector... Respondemos brevemente, y en la siguiente sección vamos con los detalles.
- Vale pero... ¿Cuántos espacios hay? Muchos... y no son siempre iguales entre diferentes implementaciones de la JVM. Actualmente hay decenas de implementaciones, y cada una de ellas interpreta la especificación JMM a su manera, completando las definiciones ambiguas o incompletas de la especificación a su discreción. La mayoría de las implementaciones coinciden en los espacios más grandes y conocidos, pero suelen diferir en muchos otros espacios "pequeños". De media podemos decir que existen entre 15 y 20.
- ¿Y si la suma de los max (virtual) supera el límite del contenedor, ¿qué pasa? No pasa nada hasta que no se comitean.
- Y si un espacio se va llenando de manera que commited (RSS) llega hasta max, ¿qué pasa? Se producirá un desbordamiento en ese espacio. Y tendremos una excepción de OutOfMemoryError en runtime. Este caso es "benigno", porque de forma clara sabremos que uno de los espacios lo tenemos que redimensionar, pero sabemos qué espacio es exactamente. El proceso Java a partir de ese momento ya no es fiable, no puede operar con normalidad y probablemente se auto terminará como el bueno de Arnold, con un exit code 3.
- Y si la suma de los commited de todos los espacios (RSS) es mayor el límite del contenedor, ¿qué pasa? OOMKilled, exit code 137. Es el síntoma de la memoria oscura...
- ¿Y puedo establecer start y max para todos estos espacios, de forma que no se produzca nunca el OOMKilled? Pues por desgracia, no para todos. Sí para muchos de ellos, los más grandes e importantes, que incluso toman valores por defecto "válidos" en muchas ocasiones, pero no para todos. Y aunque se pudiera, que no se puede, aún hay zonas de memoria no que siguen la lógica de los espacios...
Se empieza a adivinar la dimensión del problema, ¿verdad?
6. Los espacios "pequeños"
Para no empeorar nuestra salud mental, y no abordar el problema individualmente en cada uno de estos 10 o 20 espacios, vamos a crear un grupo de espacios con este nombre, y meteremos allí aquellos que cumplen los siguientes requisitos:
- Son de tamaño "pequeño". En comparación con los espacios grandes claro, como Heap o Metaspace.
- No tienen “max”.
- Reservan espacio virtual en base a la necesidad que tengan, y la ergonomía de la JVM. Dicha ergonomía (Java Ergonomics) son un conjunto de decisiones heurísticas que de forma automática toma un proceso Java en ejecución, en base la "visibilidad" del contexto de ejecución: memoria visible, CPU visible, cantidad de memoria disponible, etc.
- Su crecimiento no es lineal respecto a la carga transaccional del proceso, suelen alcanzar un límite y no aumentan más allá.
- Su tamaño es previsible y con poco riesgo de desbordamiento.
- Todos ellos sumados ocupan un espacio que ya no es “pequeño” y debe computarse para dimensionar correctamente los límites del contenedor/proceso.
- Pueden “solaparse” con otros espacios, dependiendo de la implementación de la JVM.
Vemos algunos ejemplos.

En la imagen de arriba, podemos ver una lista (incompleta) de espacios documentados por Oracle en JDK (OpenJDK).
Aquellos que tienen un número rojo, son estos espacios pequeños de los que estamos hablando, y el valor del número indica el tamaño en MB medido para ese espacio, en un microservicio desarrollado con Spring Boot y ejecutado como contenedor.
No vamos a entrar en la definición y uso de cada uno de ellos. Sólo algunas consideraciones importantes.
El tamaño puede variar bastante en función del uso que hagamos de ellos, indirectamente, a través de nuestro programa Java. Por ejemplo, es espacio Symbol almacena información como nombres de campos de clases, signaturas de métodos o Strings. Así que su tamaño dependerá de mi programación.
El tamaño también puede variar bastante debido a la configuración o ergonomía del proceso. Por ejemplo, el espacio de GC (espacio interno utilizado por el Garbage Collector para su correcto funcionamiento), puede ser relativamente "pequeño" si usamos collector de tipo Serial (el más simple), y puede requerir mucha más memoria si usamos un collector concurrente de tipo G1, por ejemplo. Y además el tamaño siempre será proporcional al tamaño que hayamos dispuesto para el heap. En el ejemplo, esos 15MB corresponden a Serial. Si lo cambiamos a G1, podría ocupar 80 o 100Mb perfectamente.
Para no alargar demasiado al artículo, no vamos a hablar aquí en profundidad de los otros grandes espacios conocidos: heap, metaspace, code y thread.
En su lugar os dejo links a otros artículos que forman parte de esta serie, donde podréis encontrar el detalle. Podéis leerlos, o no. Haremos referencia a ellos más adelante, ya que hay relaciones entre estos espacios y la problemática general. Siempre podéis parar, ir al otro artículo de la serie y volver una vez revisada la referencia.
- Java Dark Memory: Heap Space
- Java Dark Memory: Code Space
- Java Dark Memory: Class Space
- Java Dark Memory: Thread Space
7. Native Memory Tracking, luz en la oscuridad
Afortunadamente, disponemos de una poderosa herramienta para aportar luz en el uso y tamaño de los espacios de memoria, es NMT.
- NMT (Native Memory Tracking) es una característica de Java Hotspot VM que rastrea el uso de la memoria interna para una HotSpot JVM.
- Se puede acceder a los datos NMT utilizando el comando jcmd.
- NMT no realiza un seguimiento de las asignaciones de memoria de código nativo de terceros ni de las bibliotecas nativas de la propia JDK.
NMT no está habilitada por defecto, así tenemos que añadir un parámetro de arranque a nuestros procesos Java:
-XX:NativeMemoryTracking=[off | summary | detail]
Donde:
- off: valor por defecto, deshabilitado
- summary: este modo nos ofrece información global sobre los espacios
- detail: mucha más información sobre los espacios, quizá demasiada en la mayoría de los casos. Sólo usar en casos extremos.
Una vez habilitada podemos acceder a la información con jcmd:
jcmd <pid> VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale= KB | MB | GB]
Donde:
pid: número del proceso Java. Si estamos ejecutando la JVM en un contenedor, este pid es habitualmente el proceso 1.
summary|detail: si hemos habilitado NMT en modo summary, podemos pedir el resultado en modo resumen, el summary, pero no el detail. Si hemos habilitado NMT en modo detail, podemos pedir el resumen, el summary y/o el detail.
baseline: podemos pedir a NMT que guarde una instantánea o snapshot del estado de mis espacios de memoria, para ver su evolución en el tiempo.
summary.diff|detail.diff: si tenemos guardada una instantánea (baseline) podemos pedir un informe de como han evolucionado los espacios desde la última foto.
scale: para pedir los informes en diferentes unidades de medida: Kbyes, Mbytes o Gbytes
Veamos un ejemplo. Vamos lanzar NMT sobre un contenedor Java en el que se está ejecutando una aplicación Spring Boot, con NMT habilitada. La versión de la JVM es la implementación de Red Hat para HotSpot 17. Entraremos a nuestro POD/contenedor por ssh (en este caso desplegado en Openshift), y en el terminal ejecutamos el siguiente comando
jcmd 1 VM.native_memory summary scale=MB
Lo que nos dará la siguiente información, vamos a interpretarla:
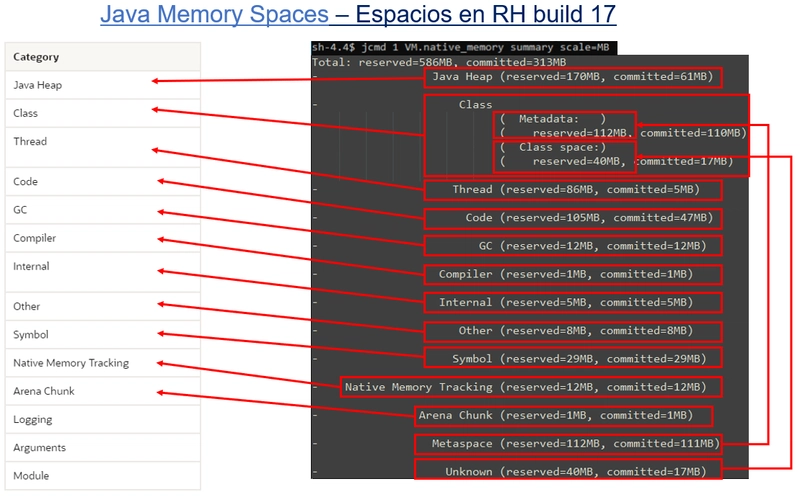
En primer lugar, veremos la línea de Total. En ella vemos los valores para reserved y committed, ya sabemos lo que significa:
- reserved: la memoria virtual, el max del espacio
- commited: la memoria residente RSS que ha sido comiteada, es decir, la realmente usada
Justo debajo vemos la misma información, pero relativa a cada uno de los espacios. Comentemos algunos aspectos interesantes:
- El propio NMT una vez habilitado requiere su propio espacio para funcionar. En la imagen vemos que se reserva 12MB, y los ha usado todos.
- Los espacios con una reserva (memoria virtual) menores de 1MB no aparecen en el informe. En la imagen podemos comprobar que los espacios "pequeños" de Logging, Arguments y Module no se muestran al no llegar a este mínimo.
- Aparecen algunos espacios duplicados o solapados. En la imagen podemos ver que Metaspace aparece dos veces. Ya hemos visto en Java Dark Memory: Class Space que Metaspace es un sub-espacio dentro de Class, que contiene Metaspace y CompressedClass-space. Aquí, Metaspace aparece dos veces, una dentro de Class, y otra como si fuera otro espacio independiente. Esta información puede resultar difícil de interpretar las primeras veces, pero hay que acostumbrarse a estos pequeños defectos que existen en prácticamente todas las implementaciones de la JVM y que además pueden variar no sólo entre implementaciones de diferentes vendors (IBM, Red Hat, Oracle, Azure, etc.), sino también entre versiones del mismo vendor (11, 17, 21, etc.). Debemos adquirir experiencia con la JVM que utilicemos, para saber interpretarla. Podemos observar otra anomalía: CompressedClass-space también aparece dos veces, en Unknown y dentro de Class. Lo dicho, hay que convivir con ello. ¡Al menos el Total está bien sumado!
- Todo lo que no sea Heap, es Off-Heap (o non-heap). En la imagen podemos ver que de los 586MB de memoria virtual o reservada, 170MB corresponden a Heap y 416MB a Off-Heap, un ratio de 30%-70% aproximadamente. Si hablamos de memoria comiteada o residente, tenemos 313MB totales, de los cuales 61MB corresponden a Heap y 252 a Off-Heap, un ratio de 20%-80% aprox.
8. Conclusiones (intermedias)
Con lo visto hasta aquí vamos a hacer un pequeño resumen, a modo de preguntas y respuestas con dudas que seguro han ido surgiendo con la lectura. Vamos allá.
- Me sorprende el ratio de uso heap vs off-heap del ejemplo. ¿Eso es normal? Pues sí. Evidentemente todo depende del tipo de aplicación. En el marco de microservicios, es decir, aplicaciones state-less que no guardan datos de sesiones de usuario, el uso del heap tiende a ser ese 20 o 25%. Aplicaciones con estado, o si metemos cachés embebidas en memoria tenderán a usar mucho más heap, quizá un 50% o más. Pero ojo: subir el tamaño del heap no quiere decir que quitemos tamaño del off-heap. Si mi aplicación necesita un heap "grande", el off-heap no se va a reducir. Al contrario, cuanto más grande sea el heap, espacios indirectamente relacionados como el de NMT o GC, necesitarán más memoria off-heap para hacer su trabajo, que es precisamente operar sobre el heap. Así que si subimos el heap, debemos subir el limit del contenedor/POD para que puede dar cabida al aumento de heap, sin disminuir el off-heap.
- En los datos de los informes de NMT, puedo ver memoria virtual/reservada, committed/RSS, pero no used. Es correcto. Para ver memoria used, es decir, la memoria usada por el proceso dentro de un espacio, que será siempre menor a commited, debemos tirar de métricas como Prometheus o JMX como hemos visto en Java Dark Memory: Heap Space. Pero este dato no es relevante, ya que los desbordamientos se producirán cuando el proceso intenta alojar un nuevo bloque para commited/RSS, y no pueda por exceder los límites del contenedor, ese el dato interesante.
- NMT está disponible en JVMs de tipo hostspot, ¿pero y si uso una JVM de tipo OpenJ9 como temurin, semeru, o AdoptJDK? Pues por desgracia NMT no está disponible JVMs de tipo OpenJ9. En este artículo nos centramos en las de tipo hotspot, pero sería interesante otro artículo sobre cómo obtener métricas de memoria nativa en OpenJ9, y en general las diferencias entre ambas. Me lo apunto... ¿cuántos van ya?
- Hemos visto el modo summary, ¿pero que ofrece adicionalmente el modo detail? Lo mismo que summary, pero añade el detalle de todas y cada una de las memory allocations que se han producido en cada espacio, su motivo, y el identificador del thread que ha generado el alojamiento. Es una cantidad ingente de información, y en mi opinión, sólo es útil en casos desesperados.
- Entonces, ¿puedo configurar todos los espacios, con un mínimo y un máximo? No todos. Los espacios "grandes" como heap, class y code, sí los puedo configurar como hemos detallado en Java Dark Memory: Heap Space, Java Dark Memory: Class Space, Java Dark Memory: Code Space. El espacio de threads, como hemos visto en Java Dark Memory: Thread Space, depende del tamaño de los pools de threads que use en mi contenedor. Si conozco los pools que utilizo y su tamaño máximo, puedo estimar con bastante precisión el tamaño máximo al que llegará este espacio. Los espacios pequeños no, la JVM toma decisiones en runtime sobre el tamaño de estos espacios. Pero lo que sí puedo y debo hacer es medirlos con NMT con una carga sostenida en mi contenedor, de manera que puedo saber cuánto ocupan realmente, y así ajustar el límite y el ratio heap/off-heap.
- Vale entendido, entonces si tengo claros los tamaños de los espacios grandes y pequeños, los he medido y ajustado con una carga sostenida, he sumado su tamaño máximo de memoria residente de todos ellos y por lo tanto tengo claro el límite de mi contenedor, puedo estar seguro de que la memoria residente nunca producirá desbordamiento, ¡¡y evitaré todos los OOMKilled!! ¿¿verdad?? Buena pregunta. Pero por desgracia no es así. Hemos mencionado antes que aparte de los espacios de memoria grandes y pequeños, hay otros tipos de alojamientos, de los que vamos a hablar en los siguientes apartados. Y esta memoria es oscura de verdad, porque ni con NMT podemos verlos...
Vamos a adentrarnos en la zona oscura de verdad....
9. Malloc. Sí, malloc.
La máquina virtual Java JVM está implementada en lenguaje C.
Y como recordamos de nuestros tiempos en la universidad, la memoria en C se reserva con la función malloc(), (memory-allocation). Que recuerdos ¿verdad?
Tranquilos javeros, no vamos a entrar en código C, ni en teoría de gestión de memoria de sistemas operativos, sólo los conceptos básicos para entender el problema subyacente.
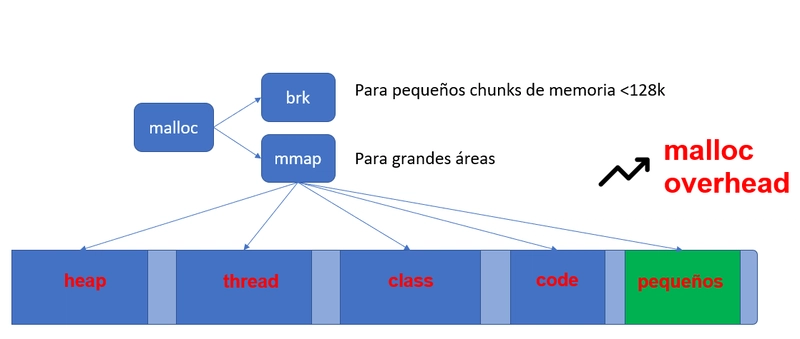
La JVM reserva memoria llamando a malloc, parte de la librería nativa glibc, que aporta el system memory allocator para cualquier proceso linux, que es el allocator por defecto (hay otros...).
Malloc a su vez llamará a diferentes funciones:
- mmap(): para reservar grandes espacios de memoria
- brk() o sbrk() para fragmentos pequeños, normalmente menores a 128KB.
Lo importante para nosotros es saber que la reserva de espacios de memoria Java se realiza con mmap (quizá brk para espacios muy pequeños, no nos importa).
Esto quiere decir que cuando la JVM reserva espacio para Metaspace, por ejemplo, se realiza un mmap() con un tamaño inicial, el valor start del del espacio.
Cuando más adelante se realice un commit de memoria, siguiendo con el ejemplo sobre el Metaspace, para alojar mis definiciones de classes, una parte de esa memoria virtual reservada será comiteada, es decir pasa a ser memoria residente RSS. Como los sistemas operativos modernos comitean siempre en bloques mínimos de 4KB, es inevitable que se produzca fragmentación interna. Es decir que tenemos que asumir que la memoria residente RSS "real" puede ser mayor que la esperada, incluso mayor que el valor max que tenga configurado para el espacio.
Pero hay más. mmap() reserva inicialmente, pongamos 20MB, si ese es el valor start del espacio. Si durante la ejecución del proceso, necesitamos más de esos 20MB, se ampliará es espacio con otro mmap(). Y esta nueva zona de memoria puede que no sea contigua a la anterior, de hecho, es bastante probable. El system allocator hará su máximo esfuerzo por obtener memoria contigua, pero en muchas ocasiones no lo conseguirá, porque no hay bloques contiguos libres lo suficientemente grandes. Esto implica que vamos a tener otro tipo de fragmentación, llamada fragmentación externa, que igual que la interna hace la memoria residente sea mayor a la esperada. En conjunto este efecto es llamado malloc overhead.
Vamos con las preguntas que seguro os han surgido ahora....
- ¿En que afecta esta fragmentación al dimensionamiento de mi contenedor? Debo tenerlo en cuenta. Según mis observaciones, esta fragmentación puede oscilar entre un 10% y un 30%, pero hay que medirla empíricamente, y aplicar el factor de corrección al límite del contenedor.
- ¿La fragmentación afecta a todos los espacios? Sí. Pero el caso del heap es algo diferente. Como hemos visto en el artículo Java Dark Memory: Heap Space, los GCs modernos son capaces de compactar esta zona, manteniendo al mínimo la fragmentación interna. Si además hacemos un PreTouch del heap e igualamos el start al max, nos aseguramos que el mmap() utilizado para el heap va a ser una gran zona de memoria contigua, eliminando la fragmentación externa de este espacio. Es decir, que el factor de corrección lo podemos aplicar sólo a la suma de los espacios off-heap.
- Esto es todo, o hay más... Si miras la barra de scroll, verás que el artículo continúa... sí, hay más memoria oscura a tener en cuenta...
10. Tenemos que hablar de buffers. Direct Memory Allocation
En Java, NIO (non-blocking) es una colección de APIs alrededor de la clase java.nio.Buffer, que en su conjunto permiten el tratamiento de arrays de datos, y su transmisión por canales de entrada/salida de todo tipo (package java.nio.channels), como peticiones web o manejo de ficheros. En general, es utilizada para enviar un array (buffer) que reside en memoria a un socket de salida, o al revés para leer un canal de entrada a memoria.
Este API es de suma importancia ya que aporta una abstracción de alto rendimiento en operaciones I/O (entrada-salida). Y es masivamente utilizada en Java, por ejemplo en:
- La propia JDK de forma interna. Y el API está disponible para developers, claro.
- Frameworks como Spring Boot y Quarkus.
- Kafka usa masivamente NIO en productores y consumidores
- Netty, que es un framework que permite la gestión asíncrona de operaciones I/O, utilizando NIO en su core. Netty suele ser utilizado a su vez por otros frameworks o librerías, aunque un developer también puede hacer uso directo de él, pero esto es menos habitual.
- Y muchos más. Prácticamente cualquier librería o framework que realice operaciones I/O, usará NIO directa o indirectamente.
No vamos a profundizar en las entrañas de este API. Lo importante para nuestro problema es que está relacionado con la memoria oscura. Vamos a tener Buffers en nuestras aplicaciones, muchos, aunque no los creemos nosotros directamente. Y debemos entender cómo afectan al uso de la memoria. Como adelanto, diremos que muchos de estos buffers, se alojan en la zona off-heap, pero no en ninguno de los espacios conocidos y descritos hasta aquí. Vamos paso a paso.
Primero veremos los tipos de buffers principales de NIO, son tres:
-
Direct Buffers (
class DirectByteBuffer): áreas de memoria nativa off-heap reservadas con malloc. Son un gran aliado ya que permiten a los threads realizar operaciones I/O directamente de la memoria a los canales/sockets, pero ocupan su propio espacio de memoria en la Arenas de glibc, de las que hablaremos a continuación. De momento sólo diremos que la memoria física de estos buffers, una vez comiteada, nunca es devuelta al sistema operativo. -
Non-Direct Buffers (
class ByteBuffer): son arrays de bytes que están en heap. Cualquier array que creemos directa o indirectamente a través de algún helper (new byte[]) es un buffer on-heap. El problema es que no se pueden utilizar directamente en operaciones I/O. Si nuestro array lo queremos escribir en un canal de salida, un fichero, un socket, una response de una request http, etc. lo que hace la JVM es primero "copiarlo" a un DirectBuffer en off-heap para poder realizar la operación de lectura o escritura del canal. -
Memory Mapped Buffers (
class MappedByteBuffer): similares a los direct buffers, pero alojados con mmap, no con malloc en Arenas. Son regiones de memoria para manejo de ficheros, directamente mapeadas en memoria. Es un API realmente eficiente. No suponen un problema de memoria oscura, ya que una vez finalizado su uso, toda la región mmap() es devuelta al sistema operativo.
Seguro que os asaltan mil dudas ahora mismo, todas relacionadas en cómo afectan estos buffers realmente al dimensionamiento de la memoria. En el siguiente apartado vamos a ver en conjunto el problema, el uso de espacios y arenas, y después vamos a tratar de solucionarlo.
11. Threads, Buffers y Arenas
Vamos a ver una secuencia de un proceso Java en ejecución.
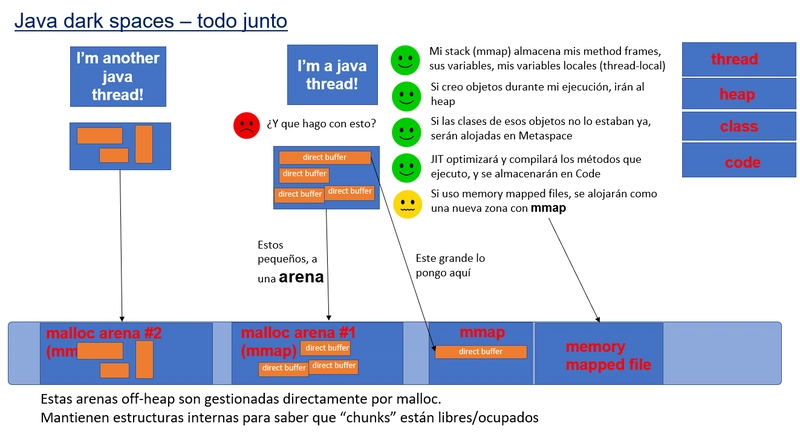
Supongamos que a nuestra aplicación que expone un endpoint REST/HTTP, llega una petición. Pasarán muchas cosas dentro de los espacios grandes:
- Se creará mi thread y el stack correspondiente en el espacio de threads.
- Los objetos que cree durante la ejecución irán naturalmente al espacio heap.
- Si las classes de esos objetos no estaban cargadas ya, se crearán en el Metaspace.
- El JIT compiler compilará y optimizará los métodos utilizados durante la ejecución, por lo que se usará el espacio Code.
Y más:
- En los espacios pequeños se comiteará memoria utilizada por GC, NMT, los String irán a Symbol, etc.
- Y si además manejo algún fichero con mapped files, en off-heap se creará una reserva con mmap(), fuera de los espacios visibles con NMT.

Vale, hasta aquí todo más o menos controlado, pero ¿y los direct buffers?
Ahora mi thread empezará a necesitar usar Direct Buffers. Y no necesariamente porque estén en mi código. La propia JDK, y los frameworks y librerías los crearán por mí:
- Para leer del socket de entrada la request HTTP a memoria.
- Para escribir la response HTTP de memoria al canal de salida del socket.
- Si he generado algún evento a un topic Kafka como parte del procesamiento.
- Si escribo o leo de algún fichero.
- Si llamo de forma síncrona a otro servicio HTTP durante mi ejecución, esa request-response debe ser copiada del socket a memoria.
- Y muchos más...
¿Y dónde se alojan esos buffers? Veamos la secuencia:
- Cada vez que se crea un buffer, la JVM utilizará el system allocator del sistema operativo, glibc.
- Este, tomará decisiones. Si es el primer buffer creado en todo el proceso, con una llamada a malloc()->mmap() va a crear una reserva virtual de un área llamada Arena. Dicha arena tiene una reserva de 64MB. Una vez creada, dentro de la Arena hay una estructura interna de punteros enlazados para comitear "pequeños" bloques con llamadas brk() y mprotect(). Ahí vivirán nuestros buffers. En Arenas, en listas enlazadas que saben donde empieza, donde termina y hasta donde está ocupado un buffer (offset)
- Si la arena ya existe, glibc utilizará de nuevo malloc()->brk()-mprotect() para buscar un "hueco libre" para alojar el buffer.
- Si el buffer es grande (decisión tomada por glibc), podría tomar la decisión de no alojarlo en una Arena, sino crear un nuevo mmap para gestionar sólo ese buffer.
Una vez terminada la ejecución:
- Tendremos una Arena, un nuevo espacio off-heap que habrá comiteado (memoria residente) la cantidad necesaria para los buffers.
- Esta memoria ocupada nunca es devuelta al sistema operativo. Los "bloques" dentro de la arena se marcarán como "libres" para ser reutilizados, pero la memoria comiteada, aunque no sea usada, nunca se libera.
Pero claro, nuestro servicio va a recibir más peticiones, no sólo una...
- En una carga concurrente, glibc, para favorecer el procesamiento en paralelo y el rendimiento, puede decidir abrir más arenas. Dos threads concurrentes pueden trabajar con dos Arenas diferentes. Y si hay más threads, pues más Arenas.
- Cada Arena maneja los "bloques" libres u ocupados como una lista enlazada. Si necesito un bloque de 4KB para un buffer, pero todos los "bloques libres" son más pequeños, abriré otro bloque (commit RSS). Expuesto a larga duración, pasarán lo siguiente: habrá mucha fragmentación interna, es decir, aunque realmente solo necesite, pongamos por ejemplo, 4MB de direct buffers, probablemente glibc haya comiteado el doble o el triple a la Arena, en ese juego de búsqueda de bloques libres por tamaño. Y por último, la Arena terminará expandiéndose hasta ese límite de 64MB altamente fragmentado. Y en ese momento, glibc abrirá otra arena, otra reserva de 64MB, que expuesta a larga duración, acabará llenándose... ¿se ve el problema verdad?
Atentos ahora:
- El número total de Arenas por defecto es de 8 x número visible de CPU cores. Si a mi contenedor le he dado 3 cores, tendré potencialmente 24 Arenas, cada una de ellas con un tamaño máximo de 64MB. Y tarde o temprano, esas arenas se llenarán, se expandirán hasta su límite. Así que... necesito 24 x 64MB = 1536MB!!!!! Un giga y medio. Sí, es cierto.
Así que, si nuestro servicio está expuesto a carga sostenida en el tiempo, vamos a tener una línea ascendente de memoria residente/comiteada, con un claro patrón de memory leak.
Una breve búsqueda en internet nos permite ver la dimensión del problema, y también sentir que no estamos solos. Hay cientos, miles de issues, post, blogs hablando del tema:
¿¡Y que puedo hacer!?
Vamos con las soluciones.
12. Soluciones. Taming the beast
Para empezar, os dejo una ficha resumen, y después hablamos de cada ajuste o solución:

- Activa NMT para poder ver lo que pasa con los espacios de memoria.
- En primer lugar, especifica un valor máximo para todos los espacios grandes: heap, code, class y threads. Mide en carga sostenida como se van llenando con NMT y encuentra en el valor máximo. Puedes ver en los artículos Java Dark Memory: Heap Space, Java Dark Memory: Class Space, Java Dark Memory: Code Space, Java Dark Memory: Thread Space como hacerlo con precisión. El que más te costará es el espacio de threads, porque tendrás que jugar con properties específicas de los frameworks que utilices: Undertow, Jetty, Netty...
- Para los espacios pequeños, mide como se expanden con NMT. Anota la suma total de todas ellas.
- Y para todos los espacios, grandes y pequeños, aplica un factor para la fragmentación externa e interna de los mismos. Podrá oscilar entre el 10 y el 30% aproximadamente.
- Establece límites a la CPU. Como hemos visto en Java Dark Memory: Code Space, el hecho de tener muchos cores disponibles hará que JIT tienda a abrir muchos más threads que consumen grandes cantidades de memoria para la compilación y optimización de código. Otros frameworks que seguro que utilizas, también toman decisiones en base a los cores visibles, que tienden a aumentar el consumo de memoria. Un valor de 2 ó 3 como máximo debería ser suficiente.
- No te fíes del flag
UseContainerSupporten contenedores. Aunque su nombre parece indicar que es una ayuda para ajustar precisamente valores de arranque y flags (java ergonomics), su utilidad es prácticamente nula. De hecho, dependiendo de la implementación, suele ajustar tamaños de heap en base al límite de memoria del contenedor, muchas veces el 50%, lo que como ya hemos visto es excesivo en aplicaciones stateless y microservicios. Por defecto está activada. Puedes desactivarla con-XX:-UseContainerSupport. - Para el heap utiliza
AlwaysPreTouche iguala el start al max (Xms=Xms), para conseguir mínima fragmentación en el heap. -
Usa
ExplicitGCInvokesConcurrent. En muchos artículos sobre buenas prácticas se recomienda desactivarlo, para evitar llamadas directas de un developer aSystem.gc(). Esto permite, por código, disparar el full GC. Si está desactivado, esto tiene consecuencias. Si mi proceso necesita alojar un direct buffer, y este excede el tamaño máximo establecido para estos direct buffers conMaxDirectMemorySize, aunque haya espacio disponible en las arenas, no podrá realizarse la reserva de memoria. Entonces el GC, va a llamar explícitamente a Symtem.gc() para buscar en el heap referencias no utilizadas a objetos DirectBuffer, y recolectarlos. Una vez hecho, se hace unThread.sleep(), y se vuelve a intentar la reserva de memoria para el buffer. Si desactivamos esta opción, podemos tener errores de runtime al no poder alojar memoria (aunque haya memoria física disponible por debajo del límite). La probabilidad del error es proporcional al tamaño del heap. Así que nunca lo desactives con-XX:+DisableExplicitGC, y actívalo explícitamente con-XX:+ExplicitGCInvokesConcurrent. -
Limita los threads de JIT compiler con
-XX:CICompilerCount. Una valor de 2 es recomendable. -
Limita el tamaño máximo de Direct Buffers con
MaxDirectMemorySize. Con esta opción, podemos poner un límite a la cantidad de memoria reservada para todos los direct buffers. Pero ojo, este límite no va a impedir que se produzca la expansión de las arenas. Lo que pasa cuando se supera este límite, es que el GC va a intentar liberar referencias no usadas, lo que va a hacer que en las Arenas, los "bloques" se marquen como "libres", pero no se devuelve la memoria física residente al sistema operativo. Este flag ayudará a que la fragmentación de las arenas sea menor, y que la expansión de la Arena hasta su máximo de 64MB sea más lenta, lo que es una ayuda. Pero no implica que si pongo 20MB de límite, la arena no se vaya a expandir más allá de esos 20MB. La fragmentación siempre ocurrirá. El valor por tanto de este flag debe ser menor a la suma de todas la arenas. Si es mayor, se producirán errores. Mi recomendación es que sea del 50% de estas. Por ejemplo, si tengo 2 Arenas, es decir 128MB, pon un límite de 64MB para MaxDirectMemorySize. De esta forma "favorecemos" la expansión lenta de la arenas reduciendo la fragmentación, y contenemos posibles OOMKilled. Puedes establecer este límite con-XX:MaxDirectMemorySize. - La propiedad del sistema
jdk.nio.maxCachedBufferSizepermite para limitar la memoria utilizada por la caché temporal de direct buffers. Esta caché es una caché por thread de memoria directa utilizada por la implementación de NIO para soportar aplicaciones que realizan I/O con buffers creados por arrays en el heap de Java. El valor de esta propiedad indica la capacidad máxima de un buffer directo que se puede almacenar en caché. Si no se establece la propiedad, no se limita el tamaño de los búferes almacenados en caché. No es estrictamente necesario poner este límite si usamos MaxDirectMemorySize, ya que esta última ya establece un límite global. Pero es muy recomendable, ya que si no lo ponemos, la caché de buffers en cada thread se puede "comer" todo el espacio de direct buffers y producir memory leaks, ya que necesitamos espacio para otros buffers utilizados por mi aplicación. Nuestra recomendación es que poner un valor de 256KB, y observar el comportamiento. Un valor muy pequeño puede tener impacto negativo en el rendimiento de la aplicación. Un valor grande o ilimitado, puede producir OOMKilled. Puedes establecer el valor con-Djdk.nio.maxCachedBufferSize(es una system property, no un flag de tipoXX). -
Establece la propiedad
io.netty.maxDirectMemorydel framework Netty (utilizado habitualmente como dependencia de otros frameworks) a valor 0 (cero). De esta manera, se "fuerza" a Netty a utilizar el espacio de buffers directos propio de la JDK, y respetar sus límites (MaxDirectMemorySize). Un valor negativo, en la práctica significa que Netty se reserva un espacio de buffers que es dos veces mayor a MaxDirectMemorySize. Un valor positivo fija el espacio de buffers utilizado por Netty. Es una system property, así que la puedes establecer con-Dio.netty.maxDirectMemory -
Utiliza la variable de entorno
MALLOC_ARENA_MAXpara limitar el número de Arenas. Recomendamos utilizar 2 ó 4. Ten en cuenta que cada arena supone 64MB off-heap. -
Utiliza la variable de entorno
MALLOC_MMAP_THRESHOLD_(sí, con el guion bajo al final). Antes hemos mencionado que para reservar memoria para un buffer, malloc puede decidir si hace un mprotect() dentro de una arena (más eficiente en rendimiento, pero favorece la fragmentación) o un mmap (menor rendimiento, es más costoso en CPU y tiempo, pero produce menos fragmentación). Precisamente este valor MALLOC_MMAP_THRESHOLD_ es el usado por glibc para decidir cuando hacer una cosa o la otra. Si no se establece, este valor es por defecto 128KB, pero ojo, no es un valor fijo, glibc puede decidir subir o bajar el threshold según sus algoritmos internos. Si fijamos un valor, este ya no será cambiado por glibc. No recomendamos valores "grandes" ya que producirán mucha fragmentación interna. Los valores bajos mantienen a raya la fragmentación, pero con un coste (más mmap). Mide y prueba en tu aplicación lo que sea más óptimo.
13. Soluciones alternativas
Llevamos un buen rato hablando del problema de la fragmentación (malloc overhead) inherente a glibc. Existen alternativas, que permiten sustituir el system allocator por defecto que es glibc, vamos a destacar dos de ellas:
jemalloc: es una implementación de malloc centrada en evitar la fragmentación y maximizar la concurrencia. Se dice que garantiza que la fragmentación no supera el 20%, aunque es un dato difícil de probar. Muy conocido y utilizado por la comunidad. Requiere un esfuerzo extra, que es compilarlo y meterlo en la imagen base de nuestros contenedores. Una vez compilado, con la variable de entorno LD_PRELOAD=/usr/local/lib/libjemalloc.so, sustituimos el malloc por defecto de glibc.
tcmalloc: otra alternativa a la implementación por defecto malloc, esta vez de Google, que se centra en maximizar el rendimiento de los alojamientos de memoria, y también en prevenir la fragmentación.
async-profiler: no es una alternativa a malloc como las anteriores. Es un profiler creado entre otros por mi admirado Andrei Pangin. Es el único profiler existente que permite rastrear allocations nativas (off-heap) y detección de leaks.
Cabe mencionar que jemalloc, la alternativa a malloc mencionada arriba tiene también su propio profiler.
13. La fórmula para calcular la memoria
¡Vamos con la fórmula final!
Pero antes, un último espacio de memoria. El último, de verdad.
Java Native Interface permite a los programadores escribir métodos nativos en lenguaje C para manejar situaciones en las que una aplicación no puede escribirse completamente en el lenguaje de programación Java.
Por ejemplo, si tenemos una biblioteca escrita en C o C++, podemos generar binarios .os y llamarlo desde Java.
La JVM en sí, está escrita en C y utiliza librerías nativas.
- No se puede monitorizar o medir, salvo con el profiler de jemalloc.
- No se puede limitar.
- Debemos tenerla en cuenta para ajustar el tamaño de nuestros contenedores
Y ahora sí, la fórmula final. Vale su peso en oro:
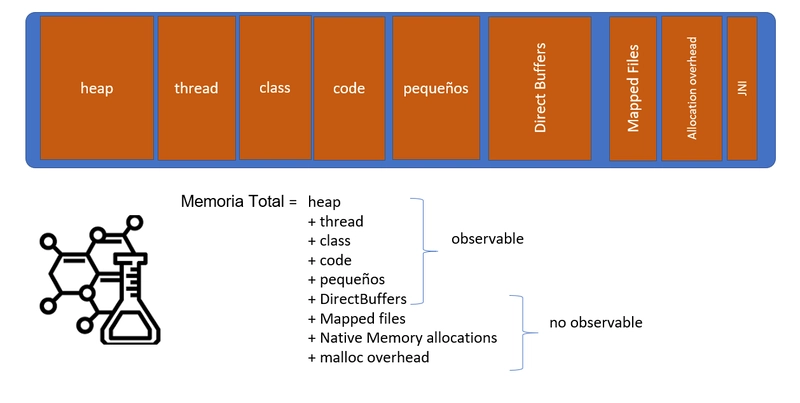
Si, ya sé. Esta fórmula tiene un problema de base. Hay cosas que no podemos medir con métricas exactas ni siquiera con NMT, por lo que la fórmula no nos vale directamente:
- malloc overhead
- arenas
- mapped files
- JNI
¿Y entonces cómo lo hacemos? Pues le damos la vuelta a la fórmula.
Lo más práctico es utilizar métricas que nos permitan medir la memoria residente de nuestro proceso, incluidas todas las zonas oscuras.
Para ello, en un entorno Kubernetes, disponemos de dos métricas prometheus:
-
container_memory_rss= CMRSS -
container_memory_working_set_bytes= CMWSB
Hay sutiles diferencias entre ellas y el tipo de memoria que miden, pero no entraremos en ese debate. En la práctica su valor es idéntico el 99% del tiempo, así que las podemos considerar iguales en términos de nuestros cálculos. Y en nuestro cálculo estas métricas nos dan el valor total de la memoria residente (RSS), en decir la memoria total utilizada.
Y lo importante de estas dos métricas, es que si su valor supera el límite del contenedor, ¡tendremos un OOM Killed!.
Así que podemos "despejar" en nuestra fórmula la variable de la memoria oscura:

Conociendo este valor, podemos fijar con bastante precisión los límites de nuestro contenedor para evitar OOM Killers, y desbordamientos en cada uno de los espacios.
14. Conclusiones finales
En nuestras aplicaciones Java en contenedores:
Ajustar los límites de los procesos Java en contenedores no es un trabajo trivial y hay que dedicarle el tiempo suficiente.
Es necesario medir y observar, sacar conclusiones, ajustar y volver a medir y observar, hasta que las pruebas de carga ofrezcan valores estables para todos los espacios, incluida la memoria oscura.
En algunos casos será necesario investigar en profundidad para encontrar las causas de un leak o un comportamiento no esperado.
Con paciencia, perseverancia y algo de suerte, podremos crear tallas de contenedores predeterminadas para nuestros servicios Java.
Espero que este artículo os haya servido de ayuda, ese es el principal objetivo de recopilar por escrito la experiencia aculada estos años. Muchas gracias por llegar hasta aquí, le hemos dedicado mucho tiempo y cariño. Sé que el artículo ha quedado un poco largo, aunque a veces pienso que ha quedado corto en muchos aspectos en los que se puede profundizar aún mucho más. Seguramente continuaremos la serie con algún artículo extra...
Si te ha servido de ayuda (o no), o simplemente quieres preguntar o abrir debate sobre algún punto, por favor deja tus comentarios a continuación. ¡Gracias y hasta la próxima!
15. Referencias y herramientas
- https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/tooldescr007.html
- https://docs.oracle.com/en/java/javase/22/core/java-nio.html
- https://en.wikipedia.org/wiki/Java_memory_model#:~:text=The%20Java%20Memory%20Model%20(JMM,consistent%20and%20reliable%20Java%20applications.
- https://jcp.org/en/jsr/detail?id=133
- https://netty.io/
- https://learn.microsoft.com/en-us/azure/spring-apps/basic-standard/concepts-for-java-memory-management
- https://www.alibabacloud.com/blog/598081
- https://technology.blog.gov.uk/2015/12/11/using-jemalloc-to-get-to-the-bottom-of-a-memory-leak/
- https://developers.redhat.com/articles/2021/09/09/how-jvm-uses-and-allocates-memory#
- https://github.com/jeffgriffith/native-jvm-leaks
- https://blog.arkey.fr/2020/11/30/off-heap-reconnaissance/
- https://www.gnu.org/software/libc/manual/html_node/Malloc-Tunable-Parameters.html
- https://github.com/bric3/java-pmap-inspector
- https://medium.com/@daniyal.hass/how-glibc-memory-handling-affects-java-applications-the-hidden-cost-of-fragmentation-8e666ee6e000
- https://youtu.be/c755fFv1Rnk
- https://github.com/async-profiler/async-profiler
- https://jemalloc.net/
- https://github.com/google/tcmalloc

Top comments (4)
Gran artículo 👏🏻. Más que recomendable para cualquiera que se enfrente a un problema de memoria en Java. Contado de manera muy amena y con un nivel de profundidad tremendo.
¡Enhorabuena!
¡Deseando ver la charla en la Commit Conf el día 05 de Abril!
Impresionante artículo 🙏🏼 información detallada , exposición de los problemas y de sus soluciones 👍🏼 muy buena idea añadir el apartado de referencias.
Enhorabuena por el trabajo y por el articulo !! Gracias.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.