
What is a Hash Table?
Hash Table is a commonly used fundamental data structure. It is known for being efficient on access speed - which comes handy specially when we want to lower the Time complexity of an algorithm (making our functions execute faster).
Hash Table helps us to create a list of key & pair values. Then we can retrieve the value by using the key afterwards.
Hash Table in Javascript and other languages
Hash Table has many different names like Objects, Dictionaries, Maps, and more. Usually different programming languages have this as a built-in data structure and have different names and variations for them.
In Javascript, Object is a type of Hash Table - as well as Map and Set. Python and C# has Dictionary. C++, Java and Go has Map.
Anatomy of a Hash Table

- Visual from https://en.wikipedia.org/wiki/Hash_table -
Here is how it works:
1 - We give a key and value pair to Hash Table.
2 - To save the value in memory, first Hash Table uses a Hash Function under the hood - which takes our key name then generates an address in memory for the value that we want to save.
3 - Then Hash Table inserts the value at the memory address recieved from Hash Function.
4 - When we insert a value in Hash Table, it doesn't always save them in a sequential order in memory like an Array. Hash Functions are often optimized to distribute the values in different empty addresses as much as possible - but when we have a limited memory with a lot of data or unefficient Hash Function, we will get a Hash Collision at one point*.* Hash Collision means we have 2 or more different keys pointing to the same location in the memory - and that is something needs to be handled to be able to store the all related values in the target address.
There are many different ways to handle Hash Collision, one of the most common technique is to use Seperate Chaining with Linked Lists. See the example below:
Seperate chaining with Linked Lists:
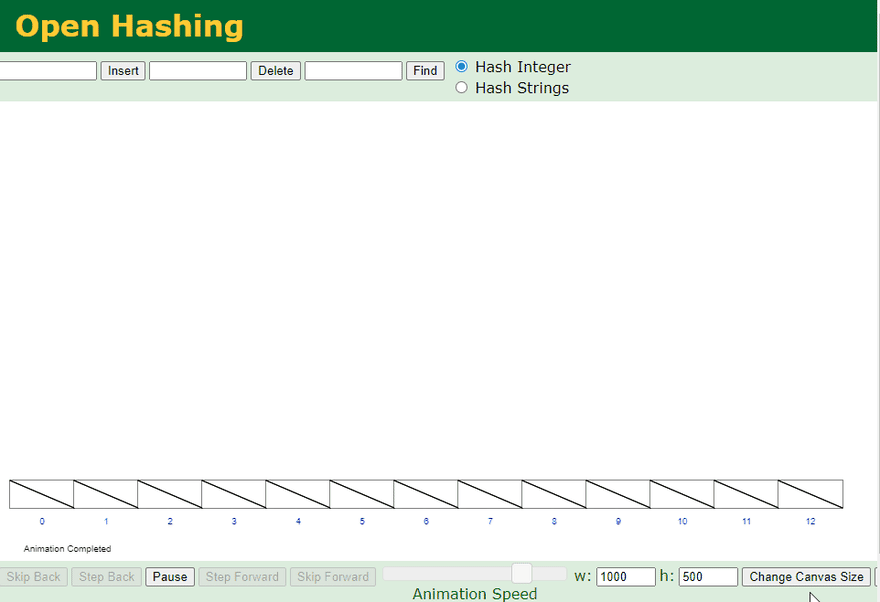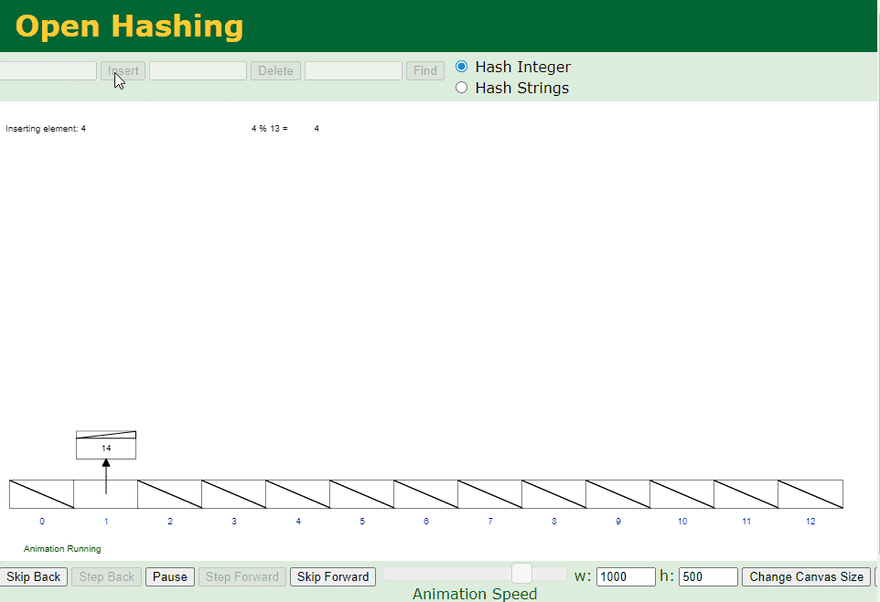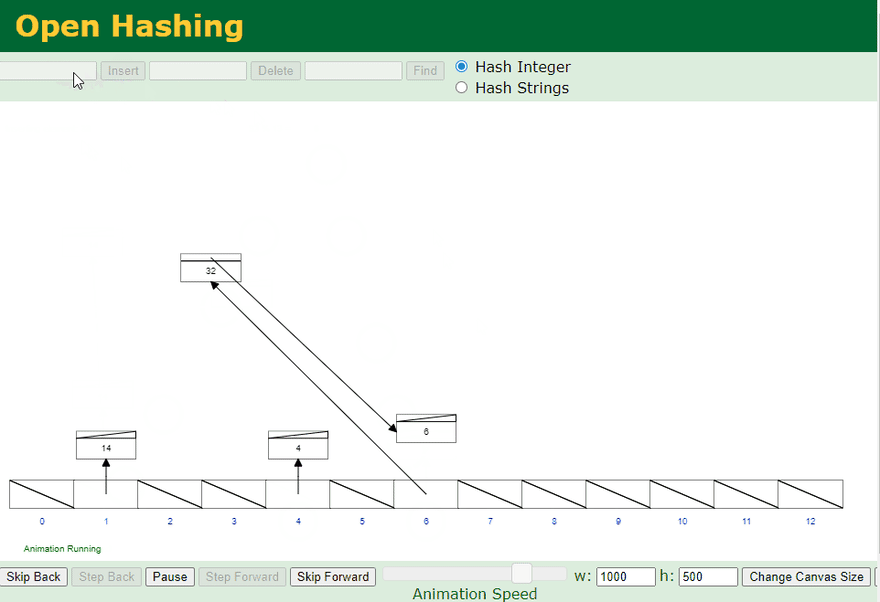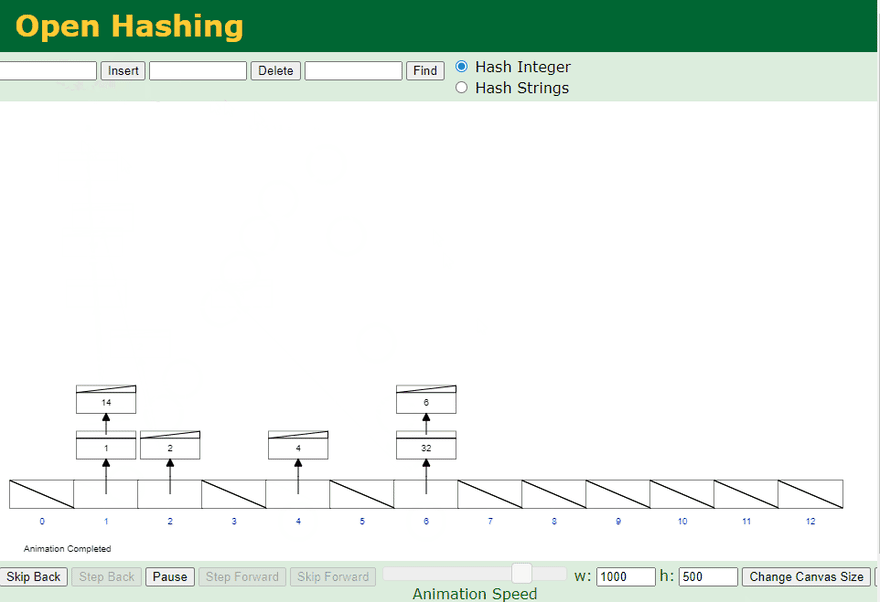
- Visual generated at: https://www.cs.usfca.edu/~galles/visualization/OpenHash.html
Structure above is actually a combination of an Array and a Linked List. Each element (Bucket) in the Hash Table (Array) is a header for a Linked List. If there is any collision (more than one value pointing to the same location) - it will be stored inside that Linked List. This way values can share the same memory address in case of a collision.
Ideally, a good Hash Function should distribute the values evenly among the buckets (indexes) until there are no empty spaces left. But usually this is not something we often write from scratch, most programming languages have their built-in Hash Tables that which also includes handling Hash Collisions.
Why do we need to even know about this? Simply because whenever we have a Hash Collision for some reason (which can be not having an efficient hashing function or when there is too little memory space), we will understand why performance of Hash Table is going to slow down. Let's take a closer look:
If Hash table has single element buckets, Time complexity for Access will be Constant time O(1) - due to getting the direct address from Hash function. When we have some buckets that has Linked lists, Access is going to change into Linear time O(n) as seen below:

- Visual generated at: https://www.cs.usfca.edu/~galles/visualization/OpenHash.html
When and When not to use Hash Table
Let's start with taking a quick look at the Big O of common operations in Hash Table:
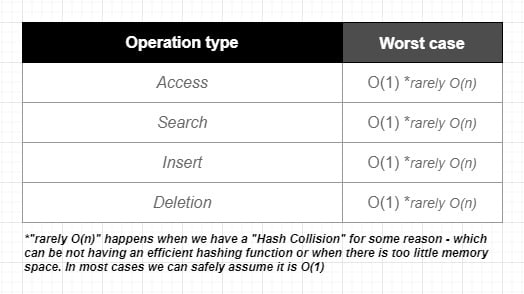
Use Hash Tables:
- If you want to structure an entity with flexible keys (property names). For example, in Arrays we don't have the same flexibility on keys, they are always named as index numbers like 0, 1, 2, .. etc. In Hash Tables we have the freedom of giving more descriptive names.
- If you want quick Access / Search / Insert / Deletion, using a Hash Table will be a great choice due to it's efficiency on these operations.
- Another common usage of Hash Tables is improving Time complexity (speed) of an algorithm. It becomes especially useful if we are dealing with nested loops. In that case we can include the Hash Table as a lookup support to get advantage of it's strength on fast insertion, retrieval or deletion.
Case study - Improving Time Complexity with help of Hash Table
Let's take a look at the classic LeetCode problem called TwoSum:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
To start with we will solve this problem by using brute force (first solution that comes to mind) - we will be using nested loops:
const unsortedNrs = [4,2,6,3,1,5,9,7,8,10]
const twoSumBrute = (list, target) => {
for (let i = 0; i < list.length; i++) {
for (let j = 0; j < list.length; j++) {
if (list[i] + list[j] === target) {
return [i, j]
}
}
}
}
twoSumBrute(unsortedNrs, 7)
// OUTPUT => [0, 3]
// Time Complexity: O(n ^ 2) - Quadratic time
// Space Complexity: O(1) - Constant space
Having O(n ^ 2) - Quadratic time is definetely not efficient in terms of Time Complexity here. Let's see what happens when we combine a Hash Table to solve this problem:
const unsortedNrs = [4,2,6,3,1,5,9,7,8,10]
const twoSumHashmap = (list, target) => {
const lookupTable = {}
// build a lookup table
for (let i = 0; i < list.length; i++) {
lookupTable[list[i]] = i;
}
// iterate
for (let j = 0; j < list.length; j++) {
let diff = target - list[j]
if (lookupTable[diff] && lookupTable[diff] !== j) {
return [j, lookupTable[diff]]
}
}
}
twoSumHashmap(unsortedNrs, 7)
// OUTPUT => [0, 3]
// Time Complexity: O(n) - Linear time
// Space Complexity: O(n) - Linear space
As you can see, by using a Hash Table we have reduced our Time Complexity from Quadratic to Linear. A simpler comparison would be assuming if the array input had 1000 elements:
- First solution with nested loop would take 1 million iterations on worst case (nested loop: 1000 x 1000)
- Second solution with Hash Table lookup support would take 2000 iterations on worst case (seperate loops coming one after another: 1000 + 1000).
But as a thumb of rule with data structures and algorithms, there is no perfect world - we just use tradeoffs depending on the situation. On first solution our Space Complexity was excellent (Constant Space). On second solution we wanted to speed up our algorithm by sacrificing some space (memory) - and that is the part where we build a lookup table. With that our Space Complexity increased from Constant Space to Linear Space.
Whenever you are using a Hash Table to improve Time Complexity - just remember it comes with a cost and make sure that Space Complexity is not an issue for the solution you want to apply.
Do not use Hash Tables:
Even though Hash Tables has great efficiency on fundamental operations, there are some situations where you would not want to use a Hash Table:
- If you want to do any type of iteration like visiting each element, sorting, finding a value by iterating each item, finding minimum or maximum value - Hash Tables are not efficient. This is because as we seen above in the Anatomy of a Hash Table section, they don't save values to the memory in ordered fashion like Arrays - it is unordered. Therefore whenever we want to do any type of iteration, it won't be as fast as an ordered list.
What is the difference between Object vs Map vs Set in Javascript?
In Javascript we have 3 type of Hash Tables that comes out of the box: Object, Map and Set. While they are very similar, there are a couple key differences:
Object:
- Keys can be only named with simple types: String, Integer or Symbol.
- Insertion order of elements is not preserved. In other words, it is not directly iterable. For example if you need to get the number of properties, you will need to use Object.keys() method: Object.keys(obj).length
- Has native support when working with JSON.
- No duplicate keys, but a value can be duplicate.
Map:
- Keys can be named with any data type.
- Does not have native support when working with JSON.
- Insertion order of elements is preserved. In other words, it has better optimization for iteration compared to an Object. For example, if you need to get the number of properties, you can use the method (similar to getting an arrays length): map.size
- No duplicate keys, but a value can be duplicate.
Set:
- Set is very similar to Map - main difference is Set does not store values with key & value pairs, it only stores keys.
- No duplicate keys.
- If you need to store a list of unique values, it is a great alternative to arrays: just because arrays can have duplicate values.
I'd also like to encourage you to check out the Objects vs Maps section on MDN docs:
Thanks for reading!

Top comments (0)