Overview of My Submission
Wall-Eve is a web application looking to provide aggregated data for the market of the game Eve Online.
A quick presentation of Eve Online and its market
Eve Online is an MMORPG that provide an API to allow developers of third parties to fetch and work with a lot of data from the game. It offers a great opportunity to build fun applications that we can share with other players.
One of the core of the game, trading, has its own endpoints where we can get orders with their price currently running for the different objects that players are buying and selling.
Market is divided in regions (you can see this as state, or country) and each region contains a lot of place (like cities) where people will buy and sell.
Where do this lead us ?
Developers looking to build a market tool will mostly interact with the endpoints returning orders from a region.
The problem is that this endpoint does not return aggregated data by items, but all the orders. It's mean you may have to pull more than 300 pages of 10000 entries, then aggregate them to be able to work with them.
It can be a bit tedious as it often requires the use of concurrency, a language able to work with a lot of data.
Due to that, it has been a while since I am wondering if it is not possible to provide an API that will return the data already aggregated with the possibility to filter on it with some query parameters. Let see how Redis can help me on this.
Design of the application
The basic design is simple, we need to fetch regularly the data from the endpoints provided by the game, so I have data up-to-date. Then I just have to serve the data through an API, and filter its output with the value entered by the user in the request.
With this description, we already have 2 services defined:
- an API that will display the data
- an Indexer that will fetch the data for a region
Even if these 2 services can be enough, we would lack the ability to control correctly the indexation.
Let's talk about the more complex design I have in mind.
Some regions in Eve Online have a slow trading pace and are ignored by a lot of traders. That's mean that the data for these regions do not necessarily need to be updated as soon as the main marketplaces of the game. This will help reduce i/o when possible.
I want to be able to schedule indexation, so I can prioritize which regions will be pull quickly and which one will be delayed longer. With that emerge 2 new services:
- a Scheduler that will determine the time for the next indexation
- a Delayer that will keep the delayed jobs in queue until they are due to process I made 2 services here, so they can evolve independently of each other
But I still have a problem. How do I prioritize which region to index ?
I need to be able to determine which region is important, and to do that I will simply listen to the call made to the API. If a region is frequently accessed through the API, it indicates that the data need to be kept updated. Otherwise, we can delay a bit more the indexation, people won't notice it.
Here come another service:
- a Heartbeat that will listen to the call made to the API and store them, so we can use them later
However, by doing that, if someone calls the API for a region that has a slow rate of indexation, he may have too old data that may be not updated before a long time.
I need to be able to catch up the indexation if needed, so even if the first few hits contain old data, the following hits will have fresh data. This leads to the creation of our last service:
- a Refresh that will also listen to the call made to the API and determine if we need to catch up the data
I now have 6 services looking to work together.
Technical implementation
I will need to use some Redis features to be able to make this services work together. Here is a schema of the services
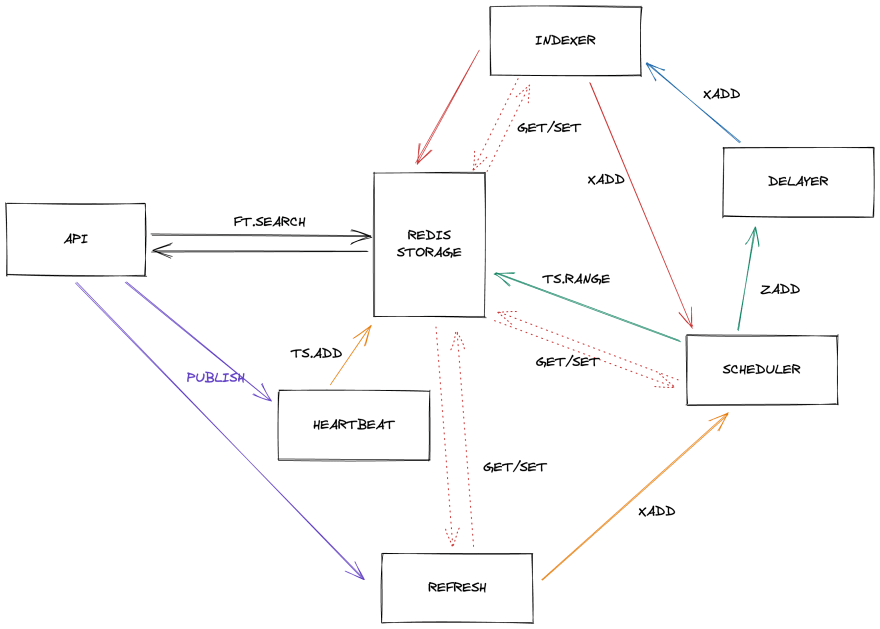
And below, a description of the workflow and the interaction between services.
1. Indexation
This service listen to a stream indexationAdd, and once a message arrive in it, will start the indexation.
The task can be a bit slow and require 1 or 2 minutes, so Indexer can work in group to consume the stream faster.
Indexing require fetching all the orders for a region, but also to get some other data like the name of the place where it is, the name of the items and few other names. We can get them thanks to the API of the game, but to reduce i/o with it, we will store them inside the Redis, so we can access them faster later.
Once done, the indexing will store the data into Redis. The data is basically aggregated by item and location, and we keep the highest buy price and the lowest sell price and all the other extra data. By doing that, we have the price of all items at theirs different locations.
To store this data, we use the JSON stack, so we can have an index and ease the search later.
We also set the TTL for these entries to be 24 hours. By doing this, we are sure that data not updated will be removed from Redis and also act as a stale cache in case there is a problem with the indexation workflow.
At the end, the service send an event with the region into the stream indexationFinished
2. Scheduling
The scheduler listen to the event send into the stream indexationFinished and once a message arrive it will determine at which time to start the new indexation for the region given.
To do so, it will read the data stored into a timeseries table related to the region to calculate when is due the new indexation.
For this demo, I kept the math simple. But the idea is, if there were calls on the API in the last 5 minutes, the indexation need to be schedule in 5 minutes. If there were calls on the API in last hour, the indexation need to be schedule in 10 minutes. Otherwise, we delay it of 1 hour.
This information is then stored in a sorted set with a score equal to the timestamp calculated earlier.
3. Delayer
We now have a task in a sorted set, and we need to determine when to really start the indexation. As the data in the set are sorted with the lowest timestamp, I can just take the first item and look if the time is correct to start the indexation.
If it is OK, the delayer will send an event with the region in the stream indexationAdd and remove the entry from the sorted set.
4. API
Now that background tasks are running, we can display the aggregated data to the user of the API.
To do that, we provide an endpoint /market, that requires as query parameter locationand accepts few other query parameters to help filter the data returned.
//List of query parameters
location #regionName, systemName, locationName, regionId, systemId, locationId
minBuyPrice
maxBuyPrice
minSellPrice
maxSellPrice
These entries will be used with the search engine of Redis against the following index
FT.CREATE denormalizedOrdersIx
ON JSON
PREFIX 1 denormalizedOrders:
SCHEMA
$.regionId AS regionId NUMERIC
$.systemId AS systemId NUMERIC
$.locationId AS locationId NUMERIC
$.typeId AS typeId NUMERIC
$.buyPrice AS buyPrice NUMERIC
$.sellPrice AS sellPrice NUMERIC
$.buyVolume AS buyVolume NUMERIC
$.sellVolume AS sellVolume NUMERIC
$.locationName AS locationName TEXT
$.systemName AS systemName TEXT
$.regionName AS regionName TEXT
$.typeName AS typeName TEXT
$.locationNameConcat AS locationNameConcat TEXT
$.locationIdTags AS locationIdTags TAG SEPARATOR ","
// Search with query parameter location that is a string
FT.SEARCH denormalizedOrdersIdx @locationNameConcat:(Dodixie IX Moon 20) @buyPrice:[5000000.00 10000000] @sellPrice:[6000000 20000000] LIMIT 0 10000
// Search with query parameter location that is a number
FT.SEARCH denormalizedOrdersIdx @locationIdsTag:{60011866} @buyPrice:[5000000.00 10000000] @sellPrice:[6000000 20000000] LIMIT 0 10000
With it, we can easily serve only the data wanted by the user.
As we can see, the query parameter location accept either a string or a number. It is like that to reduce the need for the user to have the exact id of the region, system or location where he is searching.
Each called made to the API will publish an event apiEvent with the region into a pub/sub.
5. Heartbeat
This service only listen the event published into apiEvent to save into a timeseries table related to the region, when the API has been called.
6. Refresh
As we saw earlier, data from a region without a lot of access are indexer at a slow rate.
To help reduce this issue, I look if a region need a catch-up.
To do that, I look into the sorted set indexationDelayed created by the scheduler if an entry exist for the region with a score between now (when the event is received) and the next 5 minutes.
If not, I send an event into the stream indexationCatchup with the region, so the scheduler can schedule a new indexation.
To prevent too much catch-up, I also store that a catch-up as been requested for this region during 10 minutes
7. Scheduling catch-up
This part of the workflow is also made by the scheduler. It also listens to indexationCatchup and once an event is received, we directly create an entry in the stream indexationAdd so the indexation can start as soon as possible.
Submission Category:
Microservice Mavens
Language Used
Golang
Link to Code
Wall-Eve
Wall-Eve is an API that provide aggregated data from the market of the game Eve-Online.
Eve-Online is a MMORPG where trading is an important aspect of the game. The developers provide a lot of endpoints to help the development of third parties tool but the endpoint for the market does not provide aggregated data, meaning that most of the developers creating market application have to pull the data, aggregate it and then work with it.
Wall-Eve is a possible solution to this problem. It aggregate the data and let people retrieve informations using the API exposed by this application. They even can filter using some query parameters.
The application will refresh the data regurarly to provide up-to-data informations.

Overview video (Optional)
Here's a short video that explains the project and how it uses Redis:

How it works
Check on dev.to to have a detailed post on how works the…
- Check out Redis OM, client libraries for working with Redis as a multi-model database.
- Use RedisInsight to visualize your data in Redis.
- Sign up for a free Redis database.

Top comments (0)