
Binary Trees
A binary tree, as the name suggests, is any tree in which each node has at the most two child nodes. A binary tree can be empty, implying zero nodes in the tree. The cool thing about binary trees is that they are recursive structures. This means a rule can be applied to the entire tree by applying it turn by turn to all of its subtrees.
To define a binary tree, we need two data structures. One would be the overall binary tree structure that keeps track of the root node. The other would be the node structure that keeps track of the left and right subtrees.
class binaryTree {
public:
node * root; //a pointer to the root
};
Now let's define the node structure, which would keep track of both left and right child nodes, and contain a piece of data, which in this case we call the key.
class node {
public:
node * left; //a pointer to the root of the left subtree
node * right; //a pointer to the root of the right subtree
int key;
};
Here, we are assuming that key data type is an integer, just to keep things simple. But it should be noted that the key type can be any data structure which allows comparison operators, i.e.., <, >, >=, <=, ==.
This lesson was originally published at https://algodaily.com, where I maintain a technical interview course and write think-pieces for ambitious developers.
Binary Search Trees
Binary search trees (or BST for short) are a special case of binary trees, which have an added constraint on the placement of key values within the tree. Very simply, a BST is defined by the following rule:
- All nodes in the left subtree have key values less than or equal to the key value of the parent
- All nodes in the right subtree have key values greater than or equal to the key value of the parent
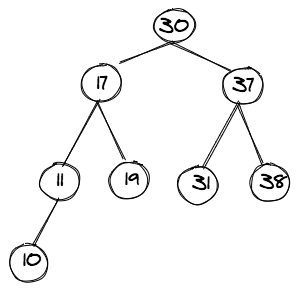
The figure below shows an example of a binary search tree:
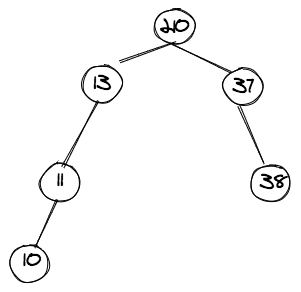
Balanced BST
A balanced BST is a BST in which the difference in heights of the left and right subtrees is not more than one (1). These example diagrams should make it clear.
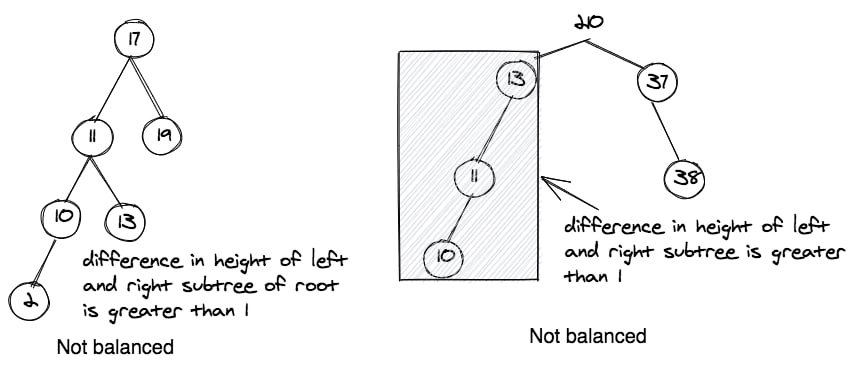
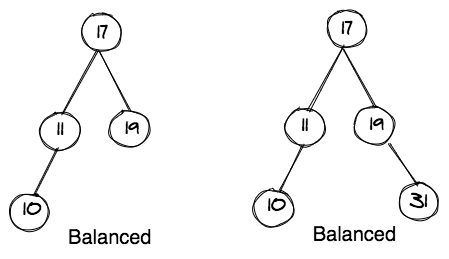
How to Balance a BST
There exist balancing algorithms for a BST, e.g., red black trees or AVL trees. In these structures, the insertion and deletion of keys within the BST takes place in such a manner that the tree remains balanced.
However, when given an unbalanced tree, how do you convert it to a balanced tree in an efficient manner? There is one very simple and efficient algorithm to do so by using arrays. There are two steps involved:
- Do an in-order traversal of the BST and store the values in an array. The array values would be sorted in ascending order.
- Create a balanced BST tree from the sorted array.
So there's two steps in our plan so far:
Step 1: In-order Traversal
Step 2: Create a balanced BST
Let's explore them. Pseudo-code to efficiently create a balanced BST is recursive, and both its base case and recursive case are given below:
Base case:
- If the array is of size zero, then return the
nullpointer and stop.
Recursive case:
- Define a
buildmethod. - Get the middle of the array and make it the root node.
- Call the recursive case
buildon the left half of the array. The root node’s left child is the pointer returned by this recursive call. - Call the recursive case
buildon the right half of the array. The root node’s right child is the pointer returned by this recursive call. - Return a pointer to the root node that was created in step 1.
The above pseudo-code's elegance stems from the fact that the tree itself is recursive. Thus, we can apply recursive procedures to it. We apply the same thing over and over again to the left and right subtrees.
You may be wondering how to get the middle of the array. The simple formula (size/2) returns the index of the middle item. This of course assumes that the index of the array starts from 0.
Let's look at some examples to see how the previous pseudo code works. We'll take a few simple scenarios and then build a more complex one.
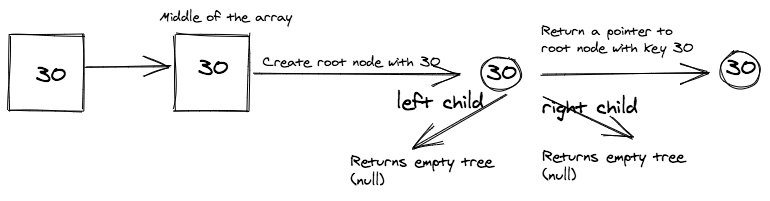
Array: [30]
First we look at the following array with just one element (i.e. 30).
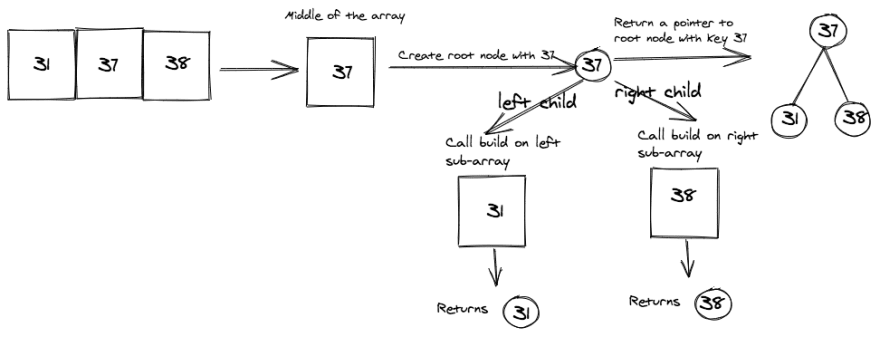
Array: [31, 37, 38]
Now let's look at an array of size 3.
Array: [10, 11]
Let us now go for an even sized array with two elements.

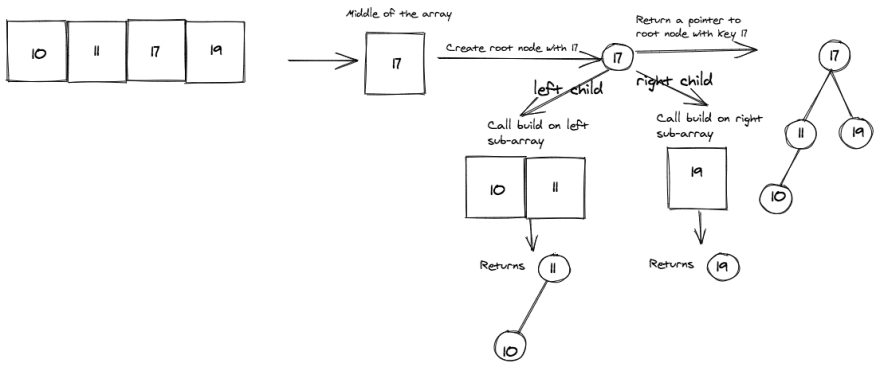
Array: [10, 11, 17, 19]
We can now extend the example to an even sized array with four elements.
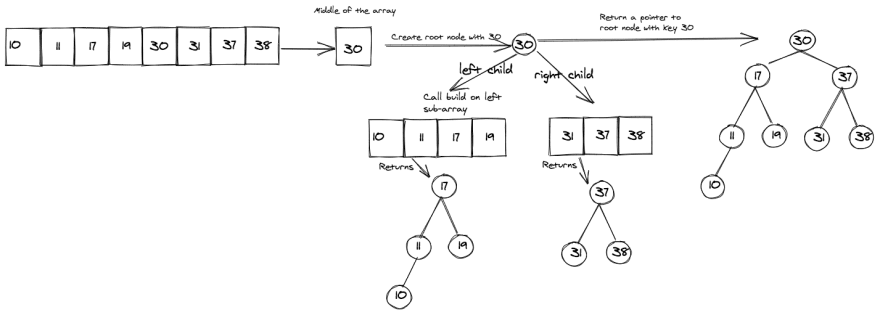
Array: [10, 11, 17, 19, 30, 31, 37, 38]
An even sized array with eight elements.
Now that we understand how balancing works, we can do the fun part, which is coding. Here is the C++ helper function, which is the recursive routine build that we had defined earlier.
The code below shows how you can call the above helper recursive function build:
void build(int *arr, int size, binaryTree &tree) {
tree.root = build(arr, 0, size-1);
}
// build returns a pointer to the root node of the sub-tree
// lower is the lower index of the array
// upper is the upper index of the array
node * build(int * arr, int lower, int upper) {
int size = upper - lower + 1;
// cout << size; //uncomment in case you want to see how it's working
// base case: array of size zero
if (size <= 0)
return NULL;
// recursive case
int middle = size / 2 + lower;
// make sure you add the offset of lower
// cout << arr[middle] << " "; //uncomment in case you want to see how it's working
node * subtreeRoot = new node;
subtreeRoot - > key = arr[middle];
subtreeRoot - > left = build(arr, lower, middle - 1);
subtreeRoot - > right = build(arr, middle + 1, upper);
return subtreeRoot;
}
Before trying out the above code, it is always best to sit down with a paper and pen, and conduct a dry run of the code a few times to see how it works. The previous code has a complexity of O(N), where N is the number of keys in the tree.
Inorder traversal requires O(N) time. As we are accessing each element of the array exactly once, the build method thus also has a time complexity of O(N).
This lesson was originally published at https://algodaily.com, where I maintain a technical interview course and write think-pieces for ambitious developers.

Top comments (1)
Why does it have to be binary?
I am currently interested in how B-tree or B+tree works, or even how filesystem works...
To my knowledge mainstream relational databases (MySQL, PostgreSQL, SQLite) all use a form of B-tree, because hashtable is not good for comparison. Abstractly you can view B-tree as a sorted set while a hashtable an unordered set. For string operations I suspect they are just implemented as regular expressions, which if you limit them to no look back can be implemented efficiently as finite state machines.