
The trend today is to split things and make them thinner. We witnessed the emergence of microservices, micro-frontends...
Against this trend, some companies and projects had decided to put multiple applications/libraries under the same git repository. We call this architectural concept a monorepo (or mono repository).
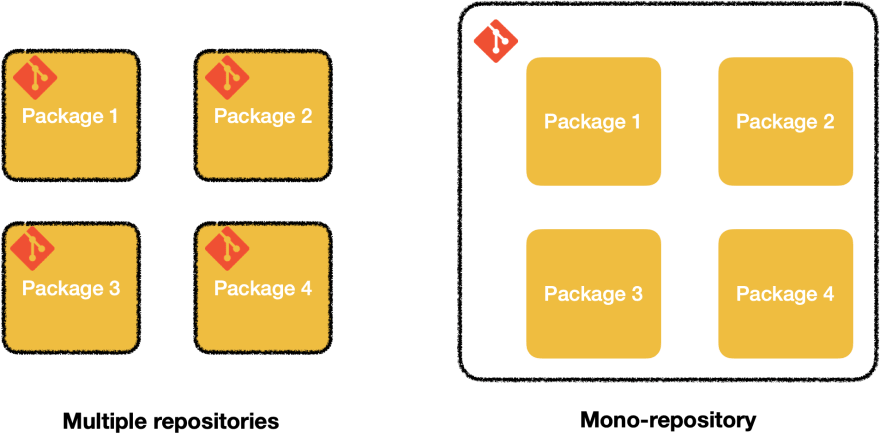
I've been using and maintaining a monorepo for 2 years now. Here are my thoughts about it.
Context: the monorepo I'm working on contains ~40 npm packages, mostly standalone vue.js apps. All those small apps are parts of a big application. We decided to split our big app into small ones because the main one had become hard to maintain. Also, we are ~15 developers working on this monorepo (not full-time).
Pros
🤝 Teamwork
Favour contribution :
When you already have the code, contributing is easier. You don't need to search for the repo, clone it and install it beforehand.
Better overview of the whole system :
You already have all the source code. So you don't need to find the repo url, clone it. A plain old ctrl + F is enough.
Favour large refactoring :
Let's say you want to change something in one package used everywhere else. You can update all the packages in one commit!
Remove unused code with confidence :
How many times you wanted to remove code but you didn't because you didn't know if code was used somewhere else? With monorepo, you don't need to go through all repo to see if this code is used or not. It's very handy.
Single source of truth :
The project I'm working on used to have a very weird name for the main branch. When we changed this name to another one, some repositories were updated, some were not (oversight). With a monorepo, you only have to find this information once.
👨👩👧 Dependencies
Less space on your hard drive :
If you're familiar with the JavaScript ecosystem, you're probably aware that the node_module folder can be insanely heavy. When we had ~30 apps/packages, it used to take 12Gb on our hard drive. Yes, 12Gb! We had dependencies like Vue.js installed 30 times. Fortunately, some tools (like yarn) symlink redundant dependencies when workspaces are enabled. Thanks to this functionality, we went from 12Gb to 1.7Gb.

Note: I know npm 7.0 now supports workspaces. However, it's still in the early stage. Important commands are not supported yet.
Cross-package hot-reload :
Some tools automatically symlink local dependencies together. Which means, if package-a is used in package-b, you can work on package-a and see the live result in package-b.
Adding a new package is simple :
For us, all our packages are under a packages folder. Adding a new package is very straightforward: no need to parameter the continuous integration/package manager credentials, set the repository permissions... everything is already there.
Cons
🛠 Git & code hosting platforms (GitLab/GitHub...)
Authorization :
When you set read/write permissions on GitLab/GitHub/etc., it's usually for the whole repo.
💡 Tip: You can also create a CODEOWNERS file to define specific ownership rule.
# .gitlab/CODEOWNERS
packages/app-1 @user1
packages/app-2 @user2
With the example above, if user2 opens a merge request to change app-1, user1 will have to approve it.
Git log may become unreadable :
If merge requests are merged "as is", with no squashing option (with 10-15 commits), the git log will quickly become unreadable, and so unusable.
💡 Tip: You can use conventional commit and put in parenthesis the name of the package. So if you want to retrieve one old commit, it becomes straightforward.
# will list all feature added in package-B
git log --all --grep="feat(package-B):"
# or:
git log --all path/to/package-b
Git log may become unusable :
If you have a lot of commits/living branches/tags, it means you will have a lot of git objects stored. git will probably have trouble getting the history of a specific file.
Forget your long-lived branches :
If the main branch is the only source of truth, you can't have a next branch. If you want to have some features only available for a specific environment, then I recommend you to use feature flags.
Repository may become oversized :
The .git folder on your monorepo root might reach a few Gb.
💡 Tip: Here are 2 different options if you want to save some space
# truncate the history
git clone --depth 1 <repo-url>
# 1. clone an empty repo with no history
# 2. pull the desired package
git clone \
--depth 1 \
--no-checkout \
--filter=blob:none \
<repo-url>
git checkout main -- packages/package-a
_Note: learn more about partial cloning._
🤖 Continuous Integration (CI)
When it's broken, everybody is!
If the main branch is marked red by your continuous integration, everybody is impacted. You cannot put this problem under the carpet. It needs to be addressed directly.
The Continuous Integration dilemma :
If codebases are mutualized, you have more code. And more code means more work for continuous integration (CI) for jobs like testing, linting, building...
When dealing with CI, time and reliability are the heart of the matter. On the one hand, you want it to be as fast as possible but, on the other hand, you want it to be reliable. I mean, when my CI gives me a green light, I'm more confident to merge my work.
It can be tempting to reduce the number of packages analysed to gain some time. But, continuous integration will lose interest because it will not be able to spot a "cross-repository" regression.
| Entire codebase | Selected package | Affected packages | |
|---|---|---|---|
| Build/lint/test Speed | 🐌 Slow | 🚀 Fast | 🚗 Medium |
| Spot cross-packages regression? | ✅ Yes | ❌ No | ✅ Yes |
| Easy to set up? | 😀 Yes | 😀 Yes | 😟 No |
The 3rd option is, in my opinion, the most viable. But, you will have to do it manually. A 4th option could use filters. "important" labelled packages use the 1st strategy and the rest use the 2nd strategy.
💡 Tips:
- If your CI pipeline is good enough and you have parallel tasks, don't forget to enable the fail-fast option.
- I recommend you to add a specific label to short-circuit the CI. Like if you change a typo in the README, you don't need to run unnecessary commands. (i.e. If the pull request have a "NO_CI" label, the build will not be triggered)
🤝 Teamwork
Hidden changes :
Some repos are sometimes more "sensitive" than others. It's easy to add a small piece of code with a big impact. It can be problematic if it's done by mistake.
Amount of code can be intimidating :
The first time I "git pulled" the source code of Gatsby.js, I pulled the full history of ~90 packages. At first glance, I felt overwhelmed. Because it took me ages to clone the full repository (with all the history). And also, because the amount of code was massive!
If you work with 10% of a codebase, you probably don't care about the 90% remaining.
Conclusion
Overall, I think a monorepo can be a good thing.
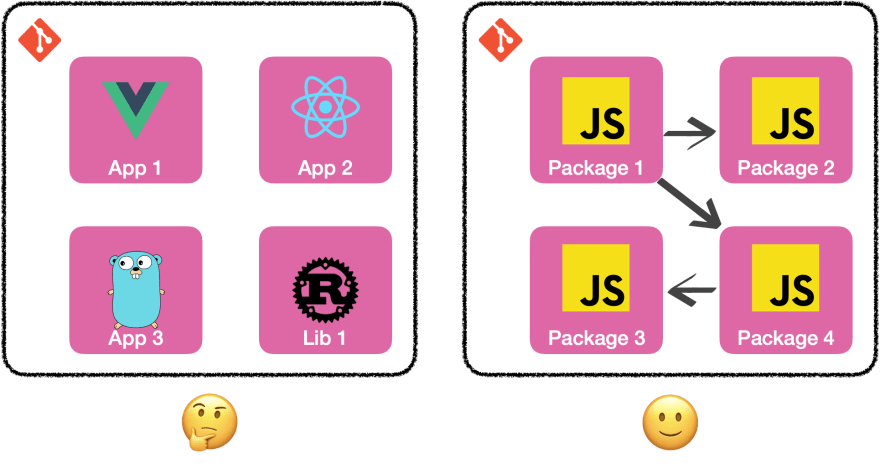
In our case, it makes our life easier. All our packages are a part of the same big application and are written in the same language. Because they're a part of the same application, they "communicate between each other". Also, we're a human-sized team working on it.
And as always, feel free to reach out to me on Twitter (@_maxpou) or in the comment below! 😊
Originally published on maxpou.fr.

Top comments (0)