
Last updated: May 14, 2025
Looking to bring OCR (Optical Character Recognition) to your C# application without the pain of configuring native Tesseract manually? You're in the right place.
💡 Note: While this article references Tesseract, all code examples use IronOCR—a powerful commercial C# OCR library that leverages and enhances the open-source Tesseract engine. IronOCR simplifies OCR development, adds advanced pre-processing, supports PDFs, and works out-of-the-box on Windows, Linux, and macOS.
Why IronOCR?
IronOCR isn't just a wrapper around Tesseract—it's a full-fledged OCR engine built for .NET developers, offering:
- Built-in image pre-processing (Deskew, Denoise, Enhance Resolution, etc.)
- Reading from PDFs, Images, TIFFs, and streams
- Outputting structured data (text, confidence, coordinates)
- Exporting results as searchable PDFs
- Multilingual support with 127+ language packs via NuGet
- Fast + accurate OCR strategies
- Cross-platform support (Windows, Linux, macOS, Docker, Azure, AWS)
📄 IronOCR Licensing: IronOCR is a commercial library with a free trial for development and testing. Licenses start at $749 USD.
Check current pricing here: IronOCR Licensing Page
Prerequisites & Compatibility
IronOCR works with almost every modern .NET plat
- ✅ .NET 9, 8, 7, 6, 5
- ✅ .NET Core 2.0+
- ✅ .NET Standard 2.0+
- ✅ .NET Framework 4.6.2+
Cross-platform? Yes! IronOCR supports:
- 🖥️ Windows
- 🍎 macOS
- 🐧 Linux
- 🐳 Docker
- ☁️ Azure & AWS environments
Installation
Install the latest version via NuGet (as of May 2025, v2025.4.13):
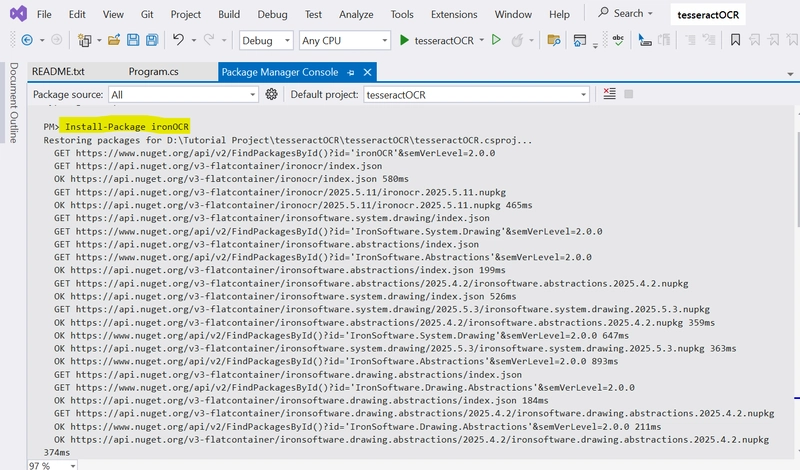
Using Package Manager Console:
Install-Package IronOcr
Or via .NET CLI:
dotnet add package IronOcr
Want another language?
IronOCR supports 127+ languages via NuGet. Example:
Install-Package IronOcr.Languages.German
💡 Tip: Install only the language packs you need to reduce app size.
Basic OCR in C# with IronOCR
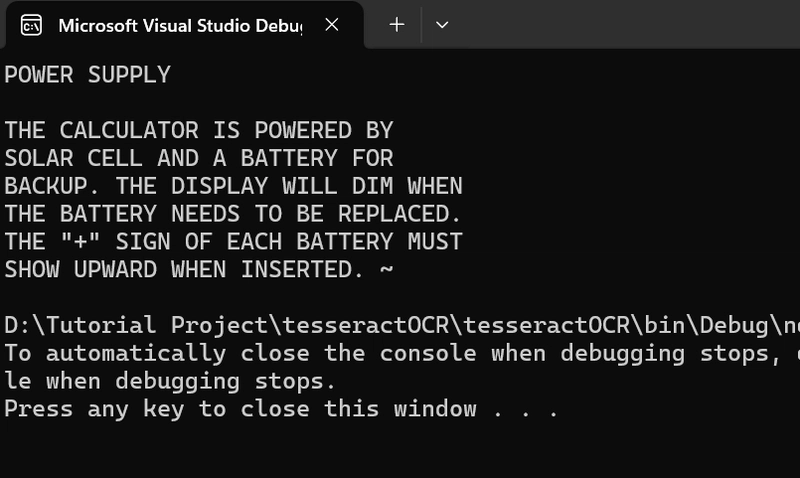
Let’s start with a simple example that reads text from an image using IronTesseract. We use LoadImage() to directly load the image from disk. You can also apply optional enhancements such as deskewing or denoising the image if needed, especially when dealing with skewed or noisy input.
using IronOcr;
var Ocr = new IronTesseract();
var ocrInput = new OcrInput();
ocrInput.LoadImage("image.jpg");
var Result = Ocr.Read(ocrInput);
Console.WriteLine(Result.Text);
This code loads the image file and performs OCR to extract the text content.
You can enhance recognition accuracy by applying pre-processing functions like Deskew() or DeNoise() or EnhanceResolution() if the input image has alignment or clarity issues.
var Ocr = new IronTesseract();
var ocrInput = new OcrInput();
ocrInput.LoadImage("image.jpg");
// Optional Pre-processing
ocrInput.Deskew(); // Fix tilted text
ocrInput.DeNoise(); // Remove background noise
ocrInput.EnhanceResolution(); // Improve blurry or low-res images
var Result = Ocr.Read(ocrInput);
Console.WriteLine(Result.Text);
Only use pre-processing methods like Deskew() and DeNoise() on images that actually need them. Using them unnecessarily may increase processing time without improving accuracy.
Customizing OCR: Languages, Speed, Filters
IronOCR allows you to fine-tune OCR behavior using a rich set of configuration options. In the following example, we customize the language, disable barcode reading, blacklist unwanted characters, enable PDF and HOCR rendering, and set specific Tesseract behaviors like page segmentation mode and thread parallelization. This flexibility helps you optimize recognition accuracy and output format based on your use case.
using IronOcr;
var Ocr = new IronTesseract();
Ocr.Language = OcrLanguage.English;
Ocr.Configuration.ReadBarCodes = false;
Ocr.Configuration.BlackListCharacters = "`ë|^";
Ocr.Configuration.RenderSearchablePdf = true;
Ocr.Configuration.RenderHocr = true;
Ocr.Configuration.PageSegmentationMode = TesseractPageSegmentationMode.AutoOsd;
Ocr.Configuration.TesseractVariables["tessedit_parallelize"] = false;
using (var Input = new OcrInput())
{
Input.LoadImage("image.png");
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}
In this setup, we explicitly choose English as the OCR language and adjust the engine's behavior to ignore unwanted characters and disable barcode detection. We also enable output in both searchable PDF and HOCR formats, and specify a more intelligent page segmentation strategy. These settings offer granular control over how IronOCR processes and interprets your input documents.
OCR from PDF Documents
IronOCR supports direct OCR on PDF files, including scanned or image-based PDFs. This makes it especially useful for automating document workflows that involve scanned reports, forms, or invoices. The following example demonstrates how to load and extract text from a PDF using LoadPdf() with IronTesseract.
using IronOcr;
var Ocr = new IronTesseract();
using (var Input = new OcrInput())
{
Input.LoadPdf("doc.pdf");
var Result = Ocr.Read(Input);
Console.WriteLine(Result.Text);
}
Here, we use LoadPdf() to import the PDF file into the OcrInput container. IronOCR then processes the file and extracts any readable text, regardless of whether the content was originally text or image-based. This is especially useful when working with scanned PDFs that do not contain selectable or searchable text natively.
Going Deeper: Structured Output
IronOCR doesn’t just return plain text — it also provides detailed structured results such as pages, paragraphs, lines, and words. You can even access confidence levels and bounding box data, which is useful for auditing, data extraction, or custom text processing. Below is an example of how to read a PDF and retrieve paragraph-level results with their confidence scores.
var Ocr = new IronTesseract();
using (var Input = new OcrInput())
{
Input.LoadPdf("sample.pdf");
var Result = Ocr.Read(Input);
foreach (var page in Result.Pages)
{
foreach (var paragraph in page.Paragraphs)
{
Console.WriteLine($"Paragraph: {paragraph.Text} (Confidence: {paragraph.Confidence}%)");
}
}
}
In this example, the OCR result is broken down by pages and then by paragraphs. Each paragraph includes both the extracted text and a confidence percentage indicating how reliable the OCR output is — higher values suggest more accurate recognition. This is particularly useful for quality control and post-processing workflows.
Key Features of IronOCR
| Feature | Description |
|---|---|
| Multi-format Input Support | Reads from images, multi-page TIFFs, PDFs, and streams. |
| Built-in Image Preprocessing | Applies deskewing, denoising, contrast enhancement, and resolution boosts. |
| 127+ Language Packs | Supports OCR in over 127 languages via NuGet language packs. |
| Structured Output | Returns structured data with pages, paragraphs, lines, words, coordinates, and confidence levels. |
| Searchable PDF Export | Can export results as searchable PDFs with text layers. |
| Cross-Platform | Runs on Windows, macOS, Linux, Docker, Azure, and AWS environments. |
Licensing
IronOCR is a commercial OCR solution, offering:
- 💼 Professional Licensing: Starting from $749 USD
- 🧪 Free 30-Day Trial: Full functionality with no limitations
- 📄 Official Licensing Page
The commercial model allows IronOCR to invest in advanced features, better support, and regular updates that go far beyond open-source Tesseract.
Conclusion
If you're building .NET apps that require reliable OCR—especially across multiple file formats, languages, or deployment platforms—IronOCR is one of the most developer-friendly and feature-rich options available. By combining the power of Tesseract with modern .NET APIs and commercial-grade support, IronOCR saves you hours (if not days) of configuration and preprocessing work.

Top comments (5)
Title is about Tesseract, article not really...
Seems like clickbait.
Dear Mehr Muhammad Hamza
Thank you for featuring IronOCR in your article. We are pleased to offer a 5% discount on base licenses to the first 25 customers.
Please use the code: IRON_2025 to avail of this offer. We encourage you to take advantage of this opportunity promptly, as it is limited.
Best regards,
The Iron Software Team
nice content <3
Thank you
How do I get the location of a word in a image using ironOcr?