
Decentralization is a wave that’s been rocking the software world recently, from the advent of Torrent, a file transfer protocol for peer-to-peer file sharing that makes it possible to distribute data all over the internet in a decentralized manner, to the coming of the already popular cryptocurrency, a decentralized ledger managing system for coin assets owned by individuals, with torrents, large file sizes can actually be fetched off the internet for little to no cost at all and with cryptocurrency, the hassles and exhausting protocols required by banks is skipped like Mr. Fantastic seriously stepping over the Empire state building in New York.
Decentralization not only reduces the workload on individual servers around, it also distributes resources across different locations and with the amount of data that may be needed to improve on existing models like GPT-3 with 175billion parameters, projected to increase by 1000s of folds. As of the time of writing this, even the most accelerated hardware resource can only train 0.15% of that future projection in realistic time, that’s why a group of intelligent individuals developed something that could help solve a growing issue in the space of Machine Learning and AI.
Ladies and Gentlemen, I give you HiveMind!
In the Machine Learning world, breakthroughs have come in from so many directions especially in the Neural Networks space from bigger Convolution Neural Networks (CNN), which are doing quite better at Computer Vision, to the way pre-trained transformers are rocking the Natural Language Processing world, and we haven’t even talked about the amazing GPT-3 that could be the one that wrote this up ;). The commonplace of all these sophisticated models is the fact that they all rely on training on a lot of parameters. Take a look at this below:
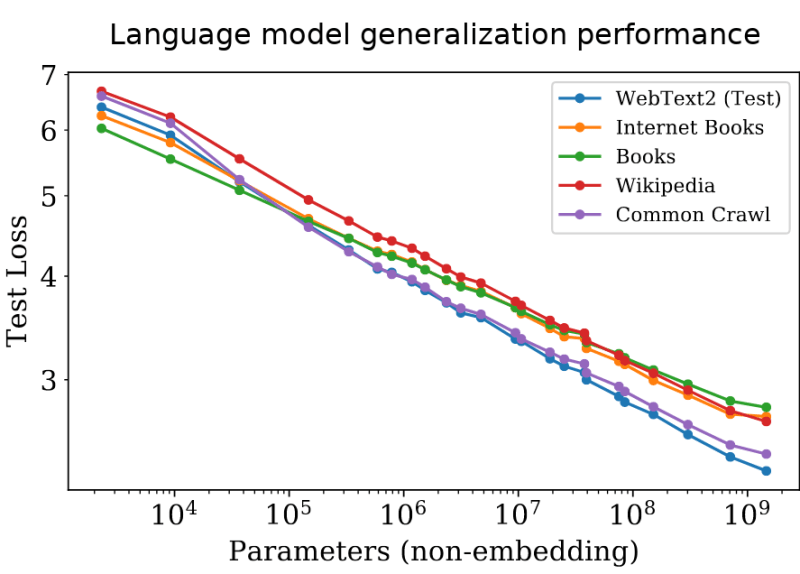
The above image shows that the Test loss declines with an increase in parameters, the more the merrier, right? But not so much in this case, training large Neural Networks is far from being cheap. It costs $25million to train the previous largest language model…That’s could get you a sizable property in the most luxurious places in Lagos, even the popular GPT-3 requires $4million for a single training with cloud GPUs and about $250million for the entire cluster, DFKM. Crazy isn’t it? It has been proven that the more parameters trained on, the better the model. But then given these costs, even if Jeff Bezos decided to train larger Neural Networks, he’d get bankrupt before the next FIFA World Cup, let alone, Researchers who are not supported by mega corporations except, of course, we want to limit the scope of AI to select individuals and this surely won’t let AI prosper. The advancements in AI is due to the growing community of enthusiastic individuals willing to take AI further and further. Although, the seeming restrictions are not caused by obscene policies or overpriced tools or the infinite tsukuyomi, but it’s the shear need for computational power which can be quite expensive.
Inspired by the overly intuitive blockchain technology and the fact that a group of highly ambitious individuals had us, the ones that are not funded by mega-rich corporations in mind, introduced the learning@home project, a crowdsourced training of Large Neural Networks using Decentralized Mixture-of-Experts.
Now, what exactly is the HiveMind? It’s not a sort of apocalyptic Artificial General Intelligence (AGI) that has interconnected neurons in the form of smaller Neural networks that combines in complexity to become one heck of a megalith intelligence, phew. According to the Learning@home documentation;
“Hivemind is a library for decentralized training of large neural networks. To meet this objective, Hivemind models use a specialized layer type: the Decentralized Mixture of Experts (DMoE)“
Sounds really cool already. Right? And then it’s open sauce, I mean, open source ;). This Decentralized Mixture of Experts (DMoE) comes with a couple of huge benefits that gets your fingers itching to get your hands on the library;
- They allow you to train models that may be too much for a single computer
- They give good and quite competitive performance even when the internet connection is poor. Think BitTorrent
They have no central coordinator so there’s no real fault trap
In Hivemind, a combination of numerous experts, termed “Mixture Of Experts” replaces a single Neural Network (NN) layer with numerous smaller “experts”. Now only few of these experts are used during the computation for a single input and they all have distinct parameters. These experts are placed on different computers in the Decentralized Mixture of Experts layer, which is responsible for discovery, distributing and managing the assignment of experts across the network by sharing their metadata using the popular Distributed Hash Table (DHT). Once the peers are discovered, the output is then computed by averaging the responses of the chosen experts for a particular input data.
In Hivemind, all peers in the network;Hosts one or more experts, depending on their hardware
Run training of models asynchronously, calling experts from other peers in the network
Discover other peers using the Distributed Hash Table
On each forward pass, a peer first determines what “speciality” of experts is needed to process the current inputs using a small “gating function” module. Then it finds the most suitable experts from other peers in the network using the DHT protocol. Finally, it sends forward pass requests to the selected experts, collects their outputs and averages them for the final prediction. Compared to traditional architectures, the Mixture-of-Experts needs much less bandwidth as every input is only sent to a small fraction of all experts.
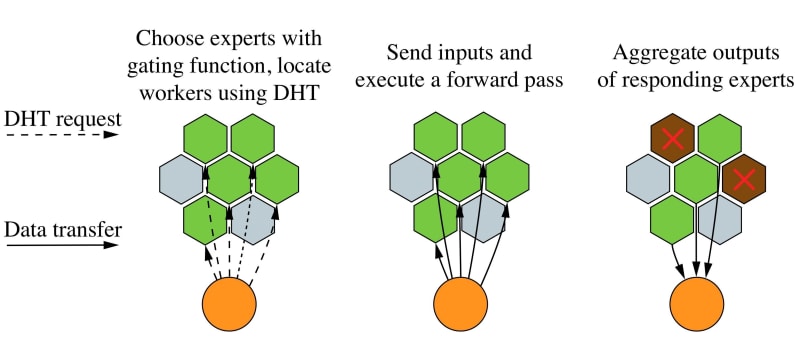
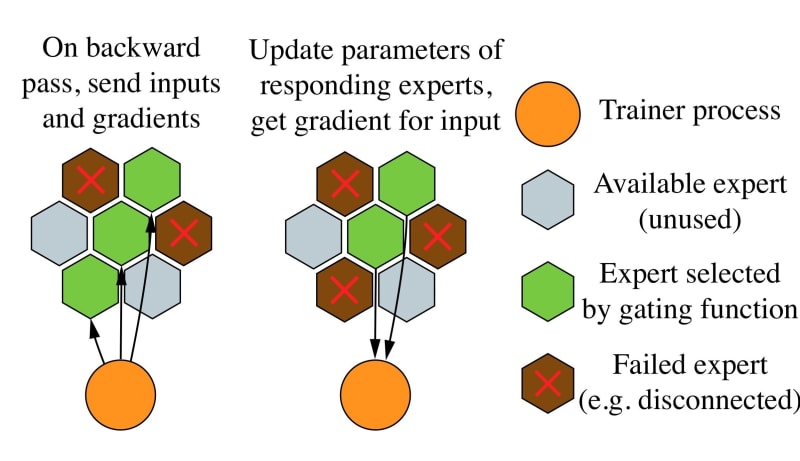
More importantly, the decentralized Mixture-of-Experts layers are inherently fault-tolerant: if some of the chosen experts fail to respond, the model will simply average the remaining ones and call that dropout. In the event that all k experts fail simultaneously, a peer will backtrack and find another k experts across the DHT. Finally, since every input is likely to be processed by different experts, hivemind peers run several asynchronous training batches to better utilize their hardware…. Pretty intuitive.
So, some people like some people I know may, all after this, be wondering “What is Hivemind really for?“
in short, Hivemind is designed for you to;
- Run crowdsourced deep learning projects using computational power from volunteers and other participants
- Train Neural Networks on multiple servers with varying compute, bandwidth and reliability
Hivemind is certainly a big leap into the future. Giving everyone a chance to explore the depth of Artificial Intelligence through deep learning is a major upgrade from the past. The creators of Hivemind are also planning a worldwide open deep learning experiment. There’s more to come ;)
Hivemind is in the early alpha stage at the time of writing: the core functionality to train decentralized models is there, but the inferface is still in active development. If you want to try Hivemind for yourself or contribute to its development, take a look at the quickstart tutorial. Feel free to contact learning@home on github with any questions, feedback and issues.

Top comments (1)
Your choice of words and style of explanation made this article worth the time. I really need to read more on Hivemind and understand experts more, they seem really intriguing.