Now everyone has a license to speak, it’s a question of who gets heard.
― Aaron Swartz
Recently I've found myself blogging extensively about my findings when developing simple serverless event-driven applications with the help of AWS Cloud Development Kit (CDK).
In a previous blog post for example I shared the outcomes of developing publish-to-social, a simple app that gives me a convenient and extensible way to update (almost all...) my social media feeds whenever there's a new blog post published and ready to be shared.
In that article I observed that the 100% automation goal was not met though and left the completion for the future, hinting at one possible solution like polling the RSS (actually Atom) feed of this blog using Python Feedparser library.
Filling the gap
As a start I've thrown the feedparser Python module into the bunch creating a dedicated Lambda Layer for that. In CDK is very convenient to add a Lambda Function dependency via Lambda Layers: with just a bit of configuration by convention (keeping all the Layers content under lib/layers/<layer_name>) all it takes now is a single line of code when instantiating a Lambda Function in the CDK stack:
lambda_poll = get_lambda(
# ...other_parameters,
layers=[get_layer(self, "feedparser", id)],
# ...
)
Feedparser is the main actor in the new feed_poller Lambda function: it takes care of sending the HTTP GET request to fetch the XML feed content, parse and validate it and finally provide an handy API for extracting useful information such as time sorted blog entries with title, link, timestamps and so on.
Optimizing RSS/Atom feed polling
Both RSS and Atom feeds specification provide bandwidth optimization features, such as ETag and Last-Modified HTTP headers, which remove the need to fetch the whole data set at every poll event in case there are no new entries.
Unfortunately though the current setup of this blog (statically generated by Jekyll v4 and hosted by Netlify) does not support any of those out of the box.
This blog and its feed are low traffic and currently don't require any kind of optimizations so investing effort on saving very little bandwidth would have been pure over engineering (or, more specifically, premature optimization).
Netlify provides custom HTTP headers support though so it should be possible (I'm not sure, I haven't done any research) to update the Jekyll Feed plugin to better integrate with the current setup and I don't exclude I'll have a look at this at some point just for the fun of it: it's been long since the last time I had the chance to work with Ruby and I always found it a (mostly) pleasant experience.
A stateless option
At first I thought there was the need to manage some kind of state to ensure only new posts were considered for publishing. Instead of jumping at any stateful kind of solution though I thought a bit deeper about the actual requirement and decided that I was more than happy to trade some latency for... statelessness 🥰!
As already discussed in the previous chapter, currently there's no support for bandwidth-optimization headers anyway (i.e. neither ETag nor Last-Updated data) so no need to store the last updated timestamp (not for that reason at least).
Beside that, RSS/Atom feeds are generally meant to be used in an eventually consumed kind of fashion anyway: I definitely have no need for updating my social feeds in real-time and I'm comfortable with even one day of delay between publishing something new on the blog and notifying the various socials about the new article.
These specifications help in simplifying the implementation sensibly as you can see from the current workflow summary:
- poll the blog Atom feed once per day (currently at 06:00 UTC)
- check for entries that have publishing timestamp matching any timestamp from yesterday
- for each new entry (if any), trigger the
publishLambda (with a little delay between each invocation to avoid being throttled by the destination API services)
This workflow implies there's no need to keep any state whatsoever, which helps in keeping it as simple and stupid as possible.
I also make sure in the CDK stack that feed_poller Lambda is executed only once (per day) even in case of errors to avoid double postings: the default AWS Lambda behavior is to retry execution two times in case of previous non-zero exit.
This is not meant to be a mission critical service anyway so, in the unlikely case of errors, the "Lambda errors" email report I receive daily should be more than enough to let me deal with them.
For the records, the above automation workflow has been in place for the last few weeks and it did work as expected when publishing the previous blog post too.
Python datetime module (included in the Python Standard Library) comes handy when working with timestamps and time deltas, it should also deal properly with those nasty edge cases that can surface during leap seconds/days/years (many thanks to Gregory for ridding us of Leap Months at least 😆):
from datetime import (datetime, timedelta)
def _midnightify(date: datetime) -> datetime:
"""Return midnightified datetime."""
return date.replace(hour=0, minute=0, second=0, microsecond=0)
now = datetime.utcnow()
yesterday = now - timedelta(days=1)
today_noon = _midnightify(now)
yesterday_noon = _midnightify(yesterday)
new_posts = [entry.link for entry in entries # entries: Feedparser iterable object
if yesterday_noon <= entry.published_datetime < today_noon]
The above snippet is just a redacted excerpt that's supposed to give you the general idea, please refer to the actual implementation for more details.
To close the 100% automation loop there's now a new CloudWatch Cron Event that fires every day at 06:00 UTC and triggers feed_poller Lambda, so this is the updated publish-to-social architecture diagram:
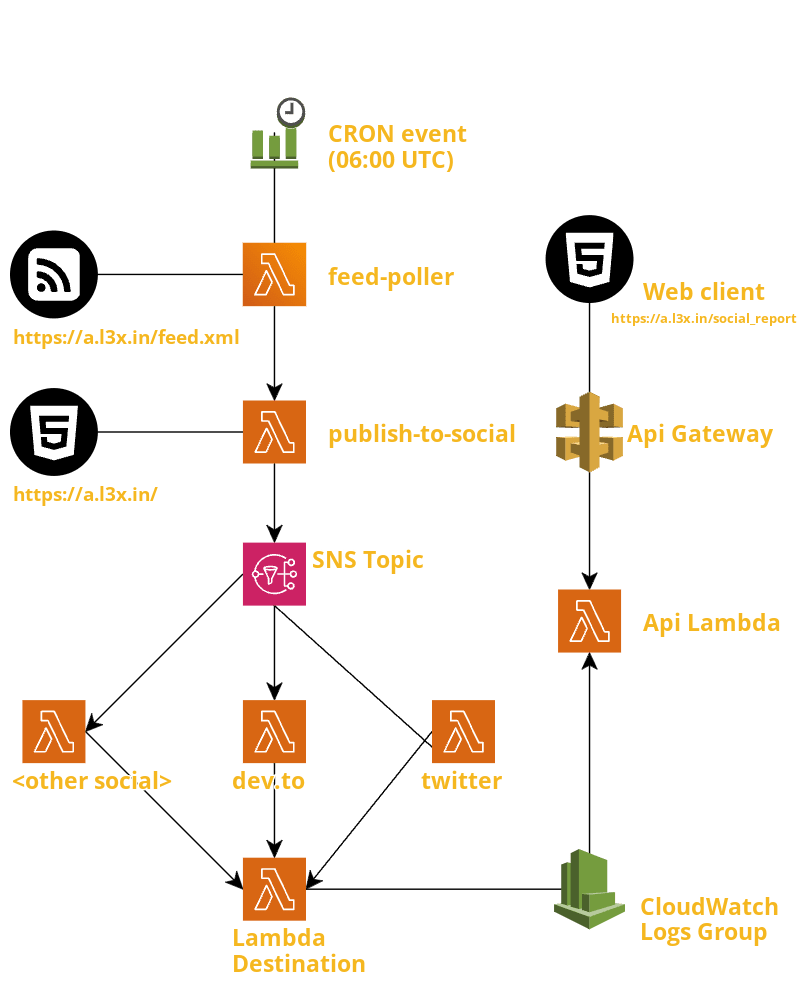
Feedback welcome
Please feel free to tell me what you think leaving a comment here or contacting me directly (various options on the Contact page). And, of course, don't forget to subscribe to this blog feed 😜
Originally published at Alexander Fortin's tech blog

Top comments (0)