This week I decided to dive into Big O notation, or algorithmic efficiency. I know it can be a bit of an intimidating topic, but the only way to get more comfortable with it is to dive in and practice! This blog post will cover the basics and serve as a refresher/guide for your journey to better understanding them.
What is Big O?
Big-O complexities pertain to the limiting behaviors of a function when the argument leans towards a particular value or infinity. Basically, it's used in Computer Science to illustrate the performance or complexity of an algorithm. This is always done in the worst-case scenario of that algorithm and can be applied to both the time and space required.

As a developer its important to be aware of the worst possible outcome of your code when it's put to the test. Being aware of this helps us developers improve our efficiency and create applications with better performance.
For instance, if you build an application and only expect a few users to visit your site then there's no problem. However, if you were, say Mark Zuckerberg and designing Facebook, then you would definitely be concerned about how your application would run as millions of users worldwide interact with your site. It is important to understand the worst-case scenario of any code that you build. As someone who is self-taught in this area I admit, it can be difficult to know what each of the complexities looks like out in the "real world" so I have prepared examples below.
Let's look at the time complexities shown in the chart above, explaining the algorithms:
O(log n)
"O of log N"
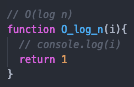
O(log n) is the best-case scenario. A good example of this is a binary search which divides the growth rate in two by every step of the code's execution. Therefore, on a graph, O(log n) will flatten out as the function progresses and outperform linear algorithms as the inputs increase.
O(1)
"O of 1"
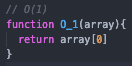
O(1) is referred to as constant time due to the fact that despite the size of our input, it will always take the same amount of time to compute things. Constant time is regarded as the best-case scenario for a function. Basically, it's a function without a loop.
O(n)
"O of N"

O(n), also known as linear time references an algorithm whose performance grows linearly, in direct correlation to the size of the input. You can think of this as one loop over a variable.
O(n log n)
"O of N log N"

O(n log n) is referred to as logarithmic time. A common example of this algorithm is the implementation of a sorting function and in this case, we'll look at Merge Sort. Just like our O(log n)'s binary search we will divide and conquer, and break the problem into smaller sub-problems, in order to recursively solve the subproblems and then combine the solutions to the smaller problems to the initial problem.
O(n2)
"O of N squared"

O(n2), also known as quadratic time, pertains to an algorithm whose performance increases exponentially to the input data size. This is commonly seen in algorithms with nested iterations or loops and the deeper you go, the higher your exponent O(n3), O(n4)..etc.
O(2n)
"Big O of two to the N"

O(2n) often referenced as exponential time, is an algorithm that doubles with each addition to the inputted data. The growth curve of this complexity is exponential, slow at first, and then skyrocketing. An example of this is the recursive solution for the Fibonacci sequence.
O(n!)
"O of n factorial"
O(N!)is bad. Really, really bad. Therefore it's hardly ever shown along with the other complexities, but it's always mentioned in the chart just to show you that it still exists.
I'll end the blog post with these useful tables from https://www.bigocheatsheet.com
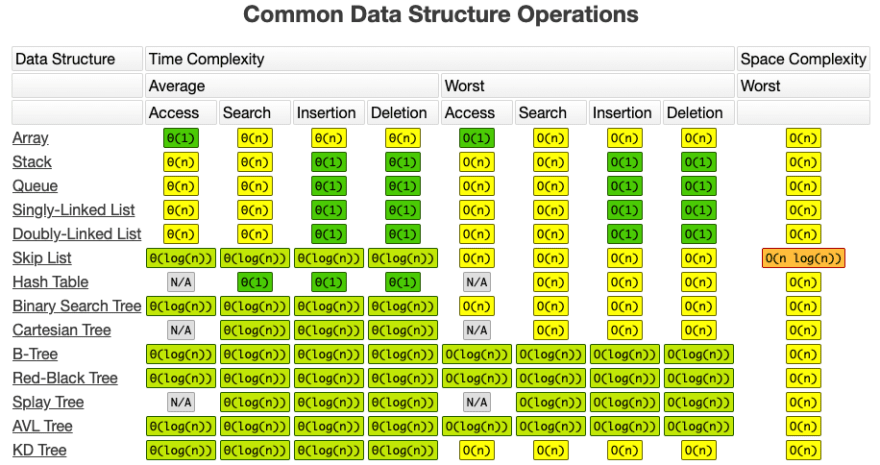
Common Data Structure Operations
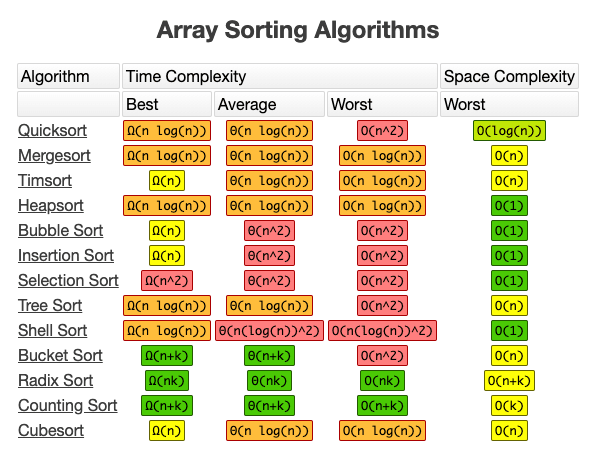
Array Sorting Algorithms
If you need a video explanation, Gayle Laakman McDowell, from Cracking the Coding Interview does a great job in this YouTube video:

Top comments (2)
This is a nice, clean, non-intimidating explainer.
Big O is one of the things a lot of people will miss out on when they're entirely self-taught, and it's quite important to keep in mind if the code you're writing is any kind of performance sensitive.
Quite a fun read! Thanks for sharing.