
One of the most promising features of the HTML5 API are Web Workers. JavaScript is of course single-threaded and thus will block its event loop while waiting on any long-running, synchronous operation. On the browser this could mean a frozen interface or worse. But when using Web Workers, this doesn't apply since they're entirely isolated browser threads running in the background, in an entirely different context from the web page and therefore have no access to the DOM, the window or document object.
Service Workers are simply special kinds of Web Workers that are installed by an origin server, run in the background and allow requests made to that server to be intercepted. So they kind of sit in between the browser and the server. Service Workers are a core part of modern Progressive Web Apps (PWAs).
Now, say, your internet is down. Since there's a running process that can intercept requests made to your site, we can write that process to display a custom, previously cached page rather than a miserable, grey page of death. It's cosmetic. Sure. But trust me, your end-users will notice. Don't believe me? Turn off your Wifi and reload this page. Looks pretty cool.
Admittedly, this article is meant more to be a leisurely excursion into two relatively advanced topics than a perfect solution to a critical problem (which it isn't). And the reason is...well why not.
Adding Our Service Worker To The Browser
On the Rails side I'll follow this directory structure to store the service worker script and the offline assets:
app/
...
public/
...
service-worker.js
offline/
offline.html
offline.css
offline.jpg
Thus the relevant URIs would be /service-worker.js, /offline/offline.html and so on.
The following script will register a given service worker in your browser. On Rails, just dumping it inside the manifest application.js (or a custom manifest file at another location) will work. Albeit it'd be much better to use a separate file:
// app/assets/javascripts/application.js
navigator.serviceWorker.register('/service-worker.js')
.then(function(reg) {
console.log('Service worker registration succeeded!');
}).catch(function(error) {
console.log('Service worker registration failed: ' + error);
});
After which you can see the following in the Chrome DevTools:
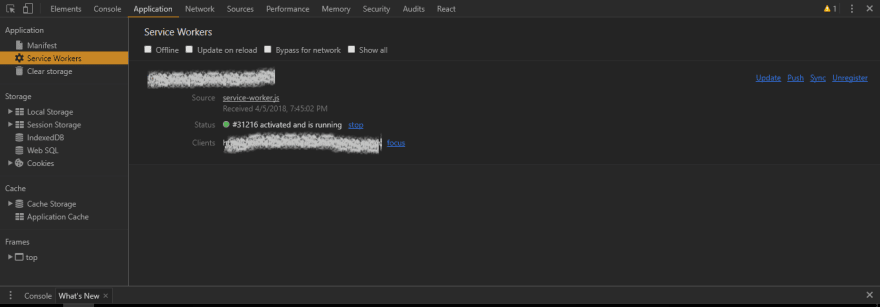
Registration might fail for the following reasons:
- Your site is not running on HTTPS (security concern).
localhostworks as well since it's considered secure but if you're developing locally on something other thanlocalhost, say, a Vagrant-provisioned VM, just forward traffic onlocalhostto the VM IP. Here's how to create that proxy on Windows if our site in dev is running on192.168.99.100:3000:
netsh interface portproxy add v4tov4 listenport=80 listenaddress=localhost connectport=3000 connectaddress=192.168.99.100
The service worker file is on a different origin to that of your app (security concern, can't have a service worker mess with requests made to other sites!).
The path to your service worker file is not right. It has to be relative to the origin.
Some out-dated browsers don't support Service Workers and since I'll be employing ES6 as well as the Cache API (for storing the offline page), let's check for their availability first:
// application.js
// Use feature-detection to check for ES6 support.
function browserSupportsES6() {
try { eval("var foo = (x)=>x+1"); }
catch (e) { return false; }
return true;
}
// Use service workers only if the browser supports ES6,
// the Cache API and of course Service Workers themselves.
if (browserSupportsES6() && ('caches' in window) && ('serviceWorker' in navigator)) {
navigator.serviceWorker.register('/service-worker.js')
.then(function(reg) {
console.log('Service worker registration succeeded!');
}).catch(function(error) {
console.log('Service worker registration failed: ' + error);
});
}
Alright, let's get to the meat of the story: the service worker itself.
After registration, the browser will attempt to install and then activate the service worker. The difference between these two will become clear shortly. For now, it's enough to know that the install event only happens once (for the same service worker script) and is a great place to hook into and fetch & cache our offline page.
As I mentioned earlier, the service worker can intercept requests made to the server. This is achieved by hooking into the fetch event.
// service-worker.js
// Path is relative to the origin.
const OFFLINE_PAGE_URL = 'offline/offline.html';
// We'll add more URIs to this array later.
const ASSETS_TO_BE_CACHED = [OFFLINE_PAGE_URL];
self.addEventListener('install', event => {
event.waitUntil(
// The Cache API is domain specific and allows an app to create & name
// various caches it'll use. This allows for better data organization.
// Under each named cache, we'll add our key-value pairs.
caches.open('my-service-worker-cache-name').then((cache) => {
// addAll() hits (GET request) all the URIs in the array and caches
// the results, with the URIs as the keys.
cache.addAll(ASSETS_TO_BE_CACHED)
.then(() => console.log('Assets added to cache.'))
.catch(err => console.log('Error while fetching assets', err));
})
);
});
self.addEventListener('fetch', (e) => {
// All requests made to the server will pass through here.
let response = fetch(e.request)
.then((response) => response)
// If one fails, return the offline page from the cache.
// caches.match doesn't require the name of the specific
// cache in which the key is located. It just traverses all created
// by the current domain and fetches the first one.
.catch(() => caches.match(OFFLINE_PAGE_URL));
e.respondWith(response);
});
The promise passed to event.waitUntil() lets the browser know when your install completes, and if it was successful.
It's important to know that "failure" of a request passed through the fetch handler, using the Fetch API, doesn't mean a 4xx or 5xx response, unlike other AJAX implementations. That promise only fails in case of a network error or wrong CORS config on the server. Which is exactly what we want.
So our service worker in its current state will work. Except...
What about the assets used by our offline page (CSS, JS, images etc)? Shouldn't they be cached just like the HTML of the offline page?
What if we want to change any of the cached assets or the page itself? How would we update the cache on the browser accordingly?
What if we change our service worker script? How will the update happen on the browser?
All valid questions. Let's take'em on one by one:
Yes. Just add the asset URIs to the
ASSETS_TO_BE_CACHEDarray and they'll be cached. In thefetchhandler add a simple check for these assets, pull them from the cache and only hit the server if they're not found in the cache (ideally this will never happen).Version your cache. Whenever you change the offline page or its assets, rename the cache created by the service worker and delete all other caches that have a different name (which will include the previously stored cache).
Every time you refresh your page the browser will perform a byte-by-byte comparison with the installed service worker script and if there's a difference it'll re-install it, immediately. This comparison also occurs every 24 hours or so automatic update checks. Of course, as you may have guessed, the browser will cache any assets that your Rails app serves by way of the
Cache-Controlheader. If our service worker remains cached for a long time, well, that's bad. We want immediate updates. That's where we'll use a custom Rails middleware to skip the header for our service worker(s).
Note: The new worker won't be activated, i.e. in running state, until the previous worker is removed. This requires either a new session (new tab) or a manual update (the button for which is visible in the Chrome console picture above). We don't need to worry about this for the most part.
// service-worker.js
// Changing the cache version will cause existing cached resources to be
// deleted the next time the service worker is re-installed and re-activated.
const CACHE_VERSION = 1;
const CURRENT_CACHE = `your-app-name-cache-v-${CACHE_VERSION}`;
const OFFLINE_PAGE_URL = 'offline/offline.html';
const ASSETS_TO_BE_CACHED = ['offline/offline.css', 'offline/offline.jpg', OFFLINE_PAGE_URL];
self.addEventListener('install', event => {
event.waitUntil(
caches.open(CURRENT_CACHE).then((cache) => {
// addAll() hits all the URIs in the array and caches
// the results, with the URIs as the keys.
cache.addAll(ASSETS_TO_BE_CACHED)
.then(() => console.log('Assets added to cache'))
.catch(err => console.log('Error while fetching assets', err));
})
);
});
self.addEventListener('activate', event => {
// Delete all caches except for CURRENT_CACHE, thus deleting the previous cache
event.waitUntil(
caches.keys().then(cacheNames => {
return Promise.all(
cacheNames.map(cacheName => {
if (cacheName !== CURRENT_CACHE) {
console.log('Deleting out of date cache:', cacheName);
return caches.delete(cacheName);
}
})
);
})
);
});
self.addEventListener('fetch', (e) => {
const request = e.request;
// If it's a request for an asset of the offline page.
if (ASSETS_TO_BE_CACHED.some(uri => request.url.includes(uri))) {
return e.respondWith(
caches.match(request).then((response) => {
// Pull from cache, otherwise fetch from the server.
return response || fetch(request);
})
);
}
let response = fetch(request)
.then((response) => response)
.catch(() => caches.match(OFFLINE_PAGE_URL));
e.respondWith(response);
});
You may ask why we purged the previously cached assets in activate and not install. This is done because if we were to purge the out-dated cache in install, the currently running worker at that time, still the old one because the new one hasn't yet been activated, might crash because of any dependency on the previous cache. Now, in our case there is no such strong dependency. But it's generally a good practice so I chose to follow it.
OK, But Where Does Rails Middleware Come In? And By The Way, WTF Is Middleware?
As I mentioned in point number 3 above, ideally service workers shouldn't be cacheable because we may require the clients' browsers to update them ASAP. This is our ultimate objective and middleware is just a means to that end. There could be better ways of doing this. Say, serving assets via Nginx and configuring it to not make service workers cacheable. But let's do it this way:
Middleware is basically any piece of code that wraps HTTP requests and responses made to and received from a server. It's very similar to the concept in Express. When a request passes through the entire middleware stack, it hits the app and then bounces back up the stack as the complete HTTP response.
As far as we're concerned, it's some code that a response generated by our Rails app has to go through before being returned to the browser. Rails is a Rack-based framework and this is what allows us to use this construct. Getting into the details of Rack here would probably be an overkill though.
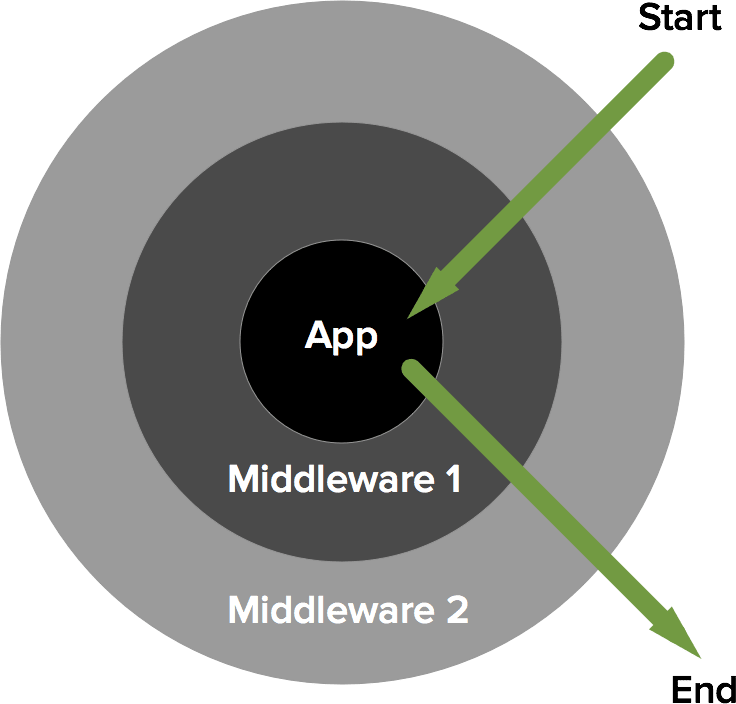
Source: https://philsturgeon.uk
Rails middleware specification is really simple: it just has to implement a call method. Let's create a new directory app/middleware and put a new class in:
# app/middleware/service_worker_manager.rb
class ServiceWorkerManager
# We'll pass 'service_workers' when we register this middleware.
def initialize(app, service_workers)
@app = app
@service_workers = service_workers
end
def call(env)
# Let the next middleware classes & app do their thing first...
status, headers, response = @app.call(env)
dont_cache = @service_workers.any? { |worker_name| env['REQUEST_PATH'].include?(worker_name) }
# ...and modify the response if a service worker was fetched.
if dont_cache
headers['Cache-Control'] = 'no-cache'
end
[status, headers, response]
end
end
We'll need to register our middleware:
# config/environments/development.rb
# ...
# Add our own middleware before the ActionDispatch::Static middleware
# and pass it an array of service worker URIs as a parameter.
config.middleware.insert_before ActionDispatch::Static, ServiceWorkerManager, ['service-worker.js']
If you run rake middleware you'll get a list of all the middleware being used by your app:
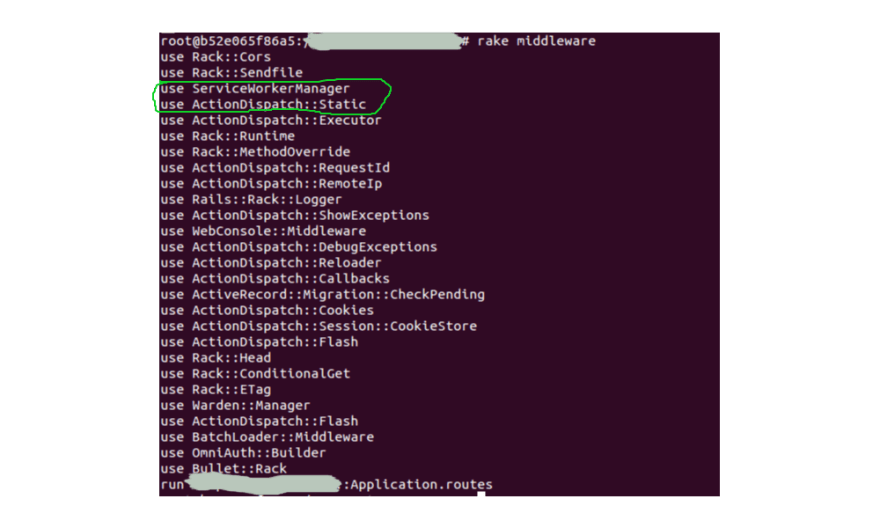
As we specified, ServiceWorkerManager has been added right before ActionDispatch::Static. The reason we added it at this particular position is because ActionDispatch::Static is used to serve static files from the public directory and automatically sets the Cache-Control header as well. In fact, static file requests don't even go through the rest of the middleware stack or the app and are returned immediately. So by placing our middleware before it, the outgoing response will have to pass through our middleware.
Here are two alternative ways to use your own middleware classes:
# Add our middleware after another one in the stack.
config.middleware.insert_after SomeOtherMiddleware, MyMiddleware, params...
# Appending our middleware to the end of the stack.
config.middleware.use MyMiddleware, params...
And we're done! Load your site, shut down your local server and try refreshing the page to see offline.html.
I've intentionally left out using the asset pipeline to transpile, minify our worker script and offline assets as that is not straightforward: fingerprinting (dynamic URIs that always change with the asset's content) & long-lived caching headers (which we just got rid of) cause problems with service workers. These are explained & solved very well here: a much better way to do all that we just did IMO :)
Offline page caching was just sort of a case study I used. Service Workers can be utilized to implement much richer features like background syncing, push notifications & others. And so can middleware: custom request logging, tracking, throttling etc. Hopefully this was a good learning experience and has motivated you to explore the two subjects further.

Top comments (1)
Nice one!
Have you used turbolinks with service workers?