
As an API-driven company, we at Anvil spend a lot of time building powerful APIs that our customers love. As a software engineer at Anvil, I work on designing and implementing these APIs for both external and internal use cases. Like most software engineers, I love to solve problems, build things, and make things work - so I love working on APIs.
One thing I don't love doing, however, is writing and maintaining documentation for the things I've built. At the same time, I understand that without documentation nobody will know how to use my creation—or that it even exists—so documentation is a necessary step in the development and release of a new feature or API. But why does it have to be so difficult? In this blog post, I'm going to outline how we at Anvil have worked to make the API documentation process as thorough and complete as possible while minimizing the pain to the developers.
TL;DR we created a new project called SpectaQL that autogenerates static GraphQL API documentation. Check it out!

SpectaQL



A nice enhancement of DociQL
SpectaQL is a Node.js library that generates static documentation for a GraphQL schema using a variety of options:
- From a live endpoint using the introspection query.
- From a file containing an introspection query result.
- From a file containing the schema definition in SDL.
The goal of SpectaQL is to help you keep your documentation complete, current and beautiful with the least amount of pain as possible.
Out of the box, SpectaQL delivers a 3-column page with a modern look and feel. However, many aspects can be customized with ease, and just about everything can be customized if you're willing to dig in.
SpectaQL also has lots of advanced features and ways to enhance your GraphQL documentation.
The Problem
Documentation of technical systems (like APIs) is challenging for a several reasons:
- It can take significant time to write the initial documentation.
- Subsequent changes to the code behavior may require updates to the documentation—which is a pain—or the documentation will become out of date or inaccurate.
- The engineer(s) who wrote the code are the most knowledgeable about the sytem, but may not be comfortable writing its documentation.
- It's hard to write accurate and complete documentation that actually matches the software behavior.
Traditionally, most of the above problems have been pretty unavoidable, but at Anvil most of our APIs are implemented in GraphQL. GraphQL requires the definition of a schema that describes all the types, fields, methods, arguments, return types, etc, and even allows for descriptions of most things to be included. In this way, GraphQL implementations are pretty self-describing, and great tools like GraphiQL or Playground already exist to leverage this attribute of the framework. Because of all this, I knew that there must be a better way to do documentation in GraphQL-land, and I sought out to find it.
Requirements
From our own trials, experience, and pain, we came up with the following set of criteria for an ideal solution to the GraphQL documentation problem:
- It should require as little extra work from the developers as possible
- The changes required by developers should take place as close to the rest of the implementation code as possible
- It should have support for:
- Descriptions of just about everything
- Types
- Fields
- Arguments
- Queries and Mutations
- Required-ness of things
- Default values
- Examples
- 1-off "undocumented" support (e.g. "don't document Foo")
- Broad "undocumented" support (e.g. "don't document any Mutations")
- Static output that does not require hitting a live server
- Embeddable and customizable look and feel to fit our branding and styles
- It should be free & open source
- It should be easy to execute (so it can be part of an automated build/release process)
The Search
While GraphiQL and Playground are absolutely awesome tools, they did not meet enough of the criteria we were looking for. Most importantly, they do not generate static output that could easily be run and extracted for use in our documentation site. They are also primarily focused on interacting with a live GraphQL server—not the documentation of one—so it felt like squeezing the other missing criteria out of one of them would have been quite a stretch. We also took a look at all of the options listed in this article as well as others we found around the web. While we saw bits and pieces of what we were looking for across all of them, nothing had exactly what we wanted.
The Decision
There was one solution we found that was the closest to what we were looking for: DociQL. It's an open-source, node.js project that describes itself like this: "DociQL generates beautiful static HTML5 documentation from a GraphQL endpoint using the introspection query." Awesome!
DociQL seemed like the best starting point for what we were looking for, but it didn't have it all. As their docs recommend, we decided to fork the project and begin customizing it to our needs. In the end, to get where we wanted to be we had to make some pretty drastic changes from the upstream repo.
Introducing SpectaQL!
We decided it was better to break it out into its own separate project, which we are now calling: SpectaQL. You can read more about the various capabilities of SpectaQL on the project page, but the rest of this blog post will discuss our overall solution to the documentation challenge, of which SpectaQL is just one—albeit major—piece.
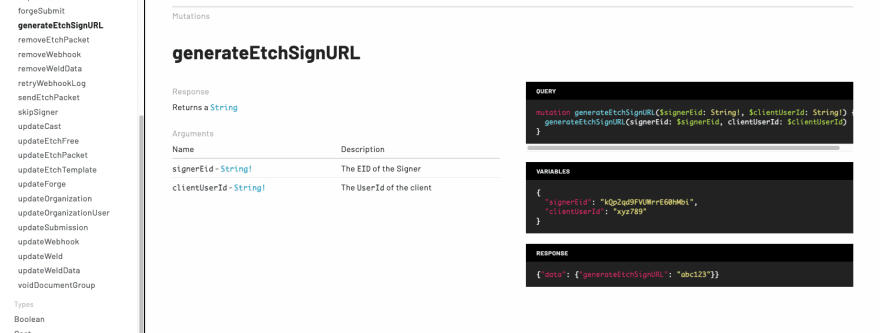
So good you could almost just Copy / Paste it!
The Implementation
A few of the most important characteristics of the solution we wanted was that any documentation-related work had to be easy for developers, and it would ideally be located in proximity to the actual implementing code. Anvil's web application is written in Node, and we chose Apollo as our GraphQL framework and use a modified version of Bookshelf as our ORM.
Luckily, we already had developed a pattern where our code was used to automagically generate the GraphQL schema SDL and resolvers that were passed to our Apollo Server. For example, our User model looks something like this:
class User {
static schema = {
id: {
type: 'Int!',
description: 'The ID of the `User`',
},
firstName: {
type: 'String!',
description: 'The first name of the `User`',
},
// Rest of Schema here
...
}
// Rest of User Class here
...
}
The above code (and all of our other Models, Queries and Mutations that follow a similar pattern) is processed during startup and converted into SDL. Our pattern supports everything that SDL supports (including arguments and defaults), but this object definition approach allows for some other advantages that will come into play soon. Here's what the relevant output looks like:

Fields are present. Default examples will be used. Markdown is also supported in text areas like the description.
While GraphQL's introspection query supports nearly everything we need to generate great documentation, it doesn't have it all. For instance, there is no support for providing examples of Types, Fields or Arguments—sure you could add it to the description, but it doesn't feel like it belongs there. Also, not everything in our GraphQL implementation is meant to be for public use. Some Fields, Types, Arguments, Queries and Mutations are meant to be private. For example, we don't want the outside world knowing about Queries that are made for Anvil administrators.
To solve these shortcomings, SpectaQL supports the inclusion of "metadata" that adds in the missing capabilities I just outlined (and more). That metadata can be provided to SpectaQL via a separate file that gets "woven" into your introspection query results, or you can "weave" it into your introspection results yourself before they reach SpectaQL.
We chose the latter approach: we modified the schema processor/generator to support detection of metadata in our code-based definitions, and to "weave" them into all of our introspection query results using a custom Apollo Server Plugin that we wrote. Now a model definition snippet that includes metadata for SpectaQL looks something like this:
class User {
static schema = {
firstName: {
type: 'String!',
description: 'The first name of the `User`',
metadata: {
// Let's use "Bobby" as the example for this Field
example: 'Bobby',
},
},
secretField: {
type: 'String!',
metadata: {
// Let's hide this field from the documentation
undocumented: true,
},
},
...
}
...
}
As a developer, I like this because I don't have to jump around to some other spot to provide this information. Everything I want to control about this Type, including how it's documented, is in one place. And from that point on, the developer has provided all that is needed with regards to documenting the User Type.
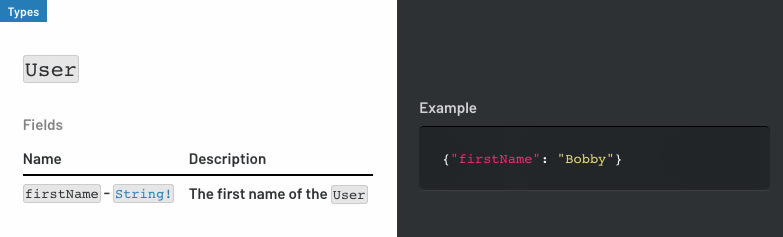
firstName gets the "Bobby" example, while secretField is now hidden
Some Additional Goodies
Adding support for static example data is great, but we thought it would be even nicer if we could dynamically generate example data when we wanted to. SpectaQL supports this as well by providing hooks that can be passed information about Fields and Arguments. Code you control can then dynamically craft the example to be used in your documentation. This way, you don't have to provide examples in your metadata for everything, yet you can still control what examples are used in your output. Want the example for any String Field whose name ends with "id"to be "<typeName>-<fieldName>"? No problem!
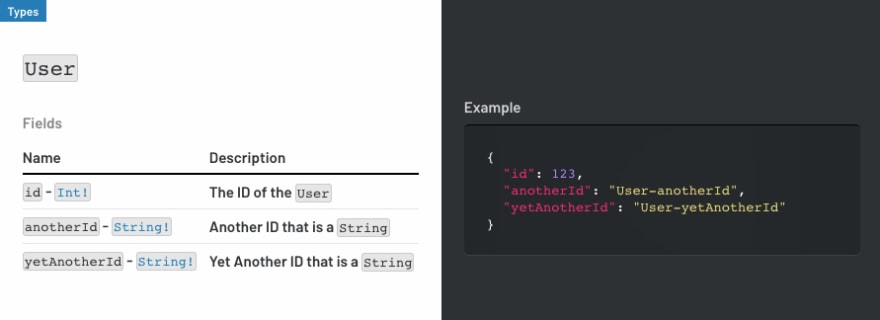
String Fields ending in "id" (case-insensitive) get affected, but not Fields of other Types
When we first started working on SpectaQL, we thought we'd want to generate a complete website that we could host on a subdomain all by itself. This is totally possible, but we later decided that we wanted to integrate the output with the rest of our marketing and documentation site, which is using Gatsby. Just like DociQL, SpectaQL allows us to generate an "embeddable" output that has no JS, CSS, or other things we didn't want, so this was not a big problem. We added in a few command-line options and we had the output we needed.
Being command-line driven, SpectaQL supports myriad options that can be tailored to just about any use case and scenario. We issue a single command, and within seconds the output we want is generated and can be used.
npx spectaql path/to/config.yml
Simple as that, and ready to be plugged into your workflows or build processes!
Summary
We now have beautiful, thorough GraphQL API documentation that's easy to keep up to date and complete, while requiring only a small, up-front additional effort by developers. Our customers and developers are happy. Our marketing team is happy. We can even shut off our introspection query on Production now, which will make our security team happy.
Even if your stack doesn't closely resemble ours, I think that the ideas discussed here combined with the robust flexibility of SpectaQL can still help you achieve a similar outcome. Please check it out!
If you have questions, please do not hesitate to contact us at:
developers@useanvil.com

Top comments (0)