Tabla de contenidos
- Modelos linguísticos
- ¿Qué es un modelo linguístico grande?
- ¿Cómo funcionan los modelos linguísticos grandes?
- Bibliografía
Modelos linguísticos
Un modelo linguístico es un modelo de aprendizaje automático cuyo objetivo es predecir y generar un lenguaje plausible. Por ejemplo, una aplicación de modelo linguístico es la funcionalidad de autocompletar 1. Estos modelos trabajan estimando la probabilidad de que un token o una secuencia de tokens ocurran dentro de una secuencia de tokens. Considera la siguiente oración:
Cuando oigo llover sobre mi tejado, Yo ______ en mi cocina.
Si asumen que un token es una frase, entonces un modelo linguístico determina la probabilidad de diferentes palabras o secuencias de palabras para reemplazar los espacios con guiones. Por ejemplo, un modelo linguístico determina las siguientes probabilidades:
cocino sopa 9.4%
caliento una tetera 5.2%
acobardo 3.6%
duermo 2.5%
relajo 2.2%
Una secuencia de tokens podría ser una frase entera o una serie de frases. Es decir, un modelo linguístico podría calcular la probabilidad de diferentes frases o bloques de texto enteros.
Estimar la probabilidad de lo que viene a continuación en una secuencia es útil para todo tipo de cosas: generar texto, traducir idiomas y responder preguntas, por nombrar algunas.
Los primeros modelos linguísticos de AI se remontan a los primeros tiempos de la IA. El modelo linguístico Eliza debutó en 1966 en el MIT y es uno de los primeros ejemplos de modelo de lenguaje de IA. Todos los modelos linguísticos se entrenan primero con un conjunto de datos y luego utilizan diversas técnicas para inferir relaciones antes de generar nuevos contenidos basados en los datos entrenados. Los modelos linguísticos suelen utilizarse en aplicaciones de procesamiento de lenguaje natural (PLN), en las que un usuario intruduce una consulta en lenguaje natural para generar un resultado 2.
¿Qué es un modelo linguístico grande?
El tamaño y la capacidad de los modelos linguísticos se han disparado en los últimos años a medida que aumentan la memoria de los ordenadores, el tamaño de los conjuntos de datos y la potencia de procesamiento, y se desarrollan técnicas más eficaces para trabajar con secuencias de texto más largas 1.
Un LLM es la evolución del concepto de modelo linguístico en IA que amplía drásticamente los datos utilizados para el entrenamiento y la inferencia. A su vez, proporciona un aumento masivo de las capacidades del modelo de IA 2.
Algunos LLM se denominan modelos fundacionales, un término acuñado por el Stanford Institute for Human-Centered Aritifial Intelligence en 2021. Un modelo fundacional es tan amplio e impactante que sirve de base para posteriores optimizaciones y casos de uso específicos, así como para resolver multitud de tareas 5.
El término IA (inteligencia artificial) generativa también está estrechamente relacionado con los LLM, que son, un tipo de IA generativa que se ha diseñado específicamente para ayudar a generar contenido basado en texto 2.
Un modelo linguístico grande es un tipo de algoritmo de inteligencia artificial que utiliza técnicas de aprendizaje profundo y conjuntos de datos masivos para comprender y generar texto como humano, además de otras formas de contenido, basándose en la gran cantidad de datos utilizados para su entrenamiento. Tienen la capacidad de inferir a partir del contexto, generar respuestas coherentes y contextualmente relevantes, traducir a idiomas distintos del inglés, resumir textos, responder a preguntas (conversación general y preguntas frecuentes) e incluso ayudar en tareas de escritura creativa o generación de código 5.
Los LLMs modernos surgieron en 2017 y utilizan modelos transformers, que son redes neuronales comúnmente denominadas transformers. Con un gran número de parámetros y el modelo transformer, los LLMs son capaces de comprender y generar repuestas precisas rapidamente, lo que hace que la tecnología de IA sea ampliamante aplicable en muchos dominios diferentes 2.
¿Cuán grande es "grande"?
Aunque no existe una cifra universalmente aceptada sobre el tamaño que debe tener el conjunto de datos para el entrenamiento, un LLM suele tener al menos mil millones de parámetros o más 2. La definición es difusa, pero "grande" se ha usado para describir a BERT (110M parámetros) así como a PaLM 2 (hasta 340B parámetros) 1.
"Grande" puede referirse al número de parámetros del modelo o, a veces, al número de palabras del conjunto de datos. Los parámetros son las ponderaciones que el modelo ha aprendido durante el entrenamiento y que se utilizan para predecir el siguiente token de la secuencia 1.

¿Cómo funcionan los modelos linguísticos grandes?
Un modelo linguístico grande se basa en un modelo transformer y funciona recibiendo una entrada, codificándola y descodificándola después para producir una predicción de salida. Pero antes de que pueda recibir una entrada de texto y generar una predicción de salida, necesita un entrenamiento, para que pueda cumplir funciones generales, y un ajuste fino, que le permita realizar tareas específicas 4.
- Entrenamiento: Los LLMs son preentrenados utilizando grandes conjuntos de datos textuales, comúnmente denomiando "corpus", que suele tener un tamaño de petabytes de información 2. La calidad de estos datos afectará al rendimiento del modelo linguístico. Durante el entrenamiento, el modelo ajusta de forma iterativa los valores de los parámetros hasta que predice correctamente el siguiente token a partir de la secuencia anterior de tokens de entrada. Esto se consigue mediante técnicas de autoaprendizaje que enseñan al modelo a ajustar los parámetros para maximizar la probabilidad de los siguientes tokens en los ejemplos de entrenamiento 3. En esta fase, el modelo linguístico grande realiza un aprendizaje no supervisado, lo que significa que procesa los conjuntos de datos que recibe sin instrucciones específicas. Durante este proceso, el algoritmo de IA del LLM puede aprender el significado de las palabras y las relaciones entre ellas. También aprende a distinguir las palabras en función del contexto. Por ejemplo, aprendería a entender si "right" significa "correcto" o lo contrario de "izquierda" 4. Una vez entrenados, los LLM pueden generar texto prediciendo de forma autónoma la siguiente palabra basándose en la información que reciben y recurriendo a los patrones y conocimientos que ha adquirido 5.
El rendimiento de los modelos también puede aumentarse mediante el ingeniería de instrucciones, el ajuste de instrucciones, el ajuste fino y otras tácticas como el aprendizaje por refuerzo con retroalimentación humana para eliminar los sesgos, el discurso odioso y las respuestas incorrectas conocidas como "alucinaciones", que a menudo son subproductos no deseados del entrenamiento con tantos datos no estructurados 5.
Ajuste fino: Para que un LLM pueda realizar una tarea específica, como la traducción, debe ajustarse a esa actividad concreta. El ajuste fino optimiza el rendimiento de tareas específicas 4.
El ajuste de instrucciones cumple una función similar al ajuste fino, ya que entrena a un modelo para realizar una tarea específica mediante instrucciones "few-shot" o "zero shot". Una "prompt" es una instrucción que se da a un LLM. Las instrucciones "few-shot" enseñan al modelo predecir salidas mediante el uso de ejemplos. Por ejemplo, en esta aplicación de análisis de sentimientos, una "prompt" "few shot" tendría este aspecto 4:
Opinión del cliente: Esta planta es preciosa.
Sentimiento del cliente: positiva
Opinión del cliente: Esta planta es horrible.
Sentimiento del cliente: negativa
El modelo linguístico entendería, a través del significado de "horrible", y porque se proporcionó un ejemplo opuesto, que el sentimiento del cliente en el segundo ejemplo es "negativo".
Por otro lado, el "prompt" "zero-shot" no utiliza ejemplos para enseñar al modelo linguístico cómo responder a las entradas. En su lugar, formula la pregunta como:
El sentimiento en 'Esta planta es tan horrible' es...
Indica claramente qué tarea debe realizar el modelo linguístico, pero no proporciona ejemplos de problemas resueltos 4.
Transformers
Un desarrollo clave en el modelado del lenguaje fue la introducción de los Transformers en 2017, una arquitectura diseñada en torno a la idea de atención. Esto hizo posible procesar secuencias largas centrándose en la parte más importante de la entrada, resolviendo problemas de memoria encontrados en modelos anteriores 1.
Anteriormente, se usaban redes neuronales recurrentes (RNN) y memorias a corto plazo (LSTM) para procesar el lenguaje secuencialemente. Antes de que se introdujeran los transformers, muchos investigadores utilizaban las RNN durante el entrenamiento de modelos linguísticos, ya que los modelos RNN pueden aprender a utilizar entradas pasadas y predecir lo que viene a continuación. Sin embargo, uno de los problemas de los modelos RNN es que, a medida que se alarga una frase, aumenta el número de entradas recibidas y se ensancha la brecha entre lo que es relevante y la capacidad del modelo para utilizarlo cuando es necesario. Cuando esto ocurre, el modelo RNN tiene menos probabilidades de predecir con éxtio lo que viene a continuación 7. Por otro lado, un modelo LSTM es un tipo de RNN que mejora el mecanismo de memoria convencional mediante celdas de estado, permitiendo al modelo LSTM recordar u olvidar selectivamente entradas anteriores en función de su importancia 10. A pesar de estas mejoras, cada etapa de ambos modelos dependia de las etapas previas, lo que prolongaba los tiempos de entrenamiento e inferencia 10.
Un transformer es una red neuronal que procesa datos secuenciales (como las palabras de una frase) toman una secuencia de texto como entrada y producen otra secuencia de texto como salida 7,8. Un transformer es un tipo de modelo de inteligencia artificial que aprende a comprender y generar texto de manera similar al humano analizando patrones en grandes cantidades de datos 9.
Los transformers son un modelo actual de NLP de última generación y se consideran la evolución de la arquitectura encoder-decoder. Sin embargo, mientras que la arquitectura encoder-decoder se basa principalmente en redes neuronales recurrentes (RNN) para extraer información secuencial, los transformers no usan esta recurrencia. En su lugar, estan diseñados específicamente para comprender el contexto y el significado analizando la relación entre distintos elementos, y para ello se basan casi por completo en una técnica matemática llamada atención 9.
A diferencia de las redes neuronales recurrentes (RNN) anteriores, que procesan las entradas secuencialmente, los transformers procesan secuencias enteras en paralelo. Esto permite utilizar GPU para entrenar LLMs basadas en transformers, lo que reduce considerablemente el tiempo de entrenamiento 3.
Arquitectura de un modelo transformer
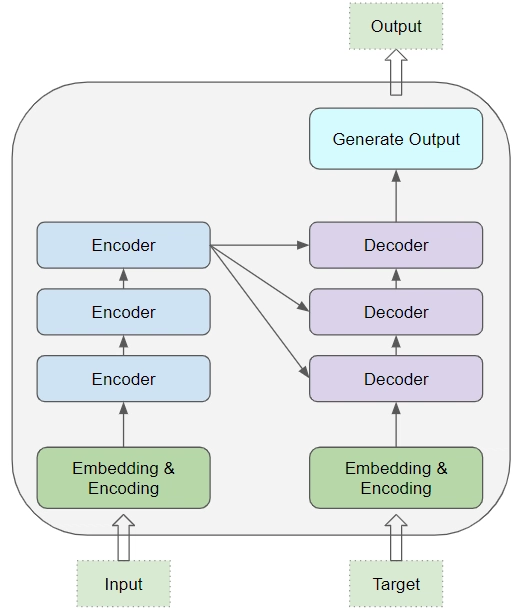
En su núcleo, un modelo transformer, consta de un grupo de encodificadores y un grupo de descodificadores. Ambos grupos tienen su capa de embeddings para sus respectivos datos de entrada. Por último hay una capa de salida para generar el resultado final 8. Todos los codificadores presentan la misma estructura y el dato de entrada llega a cada uno de ellos y se pasa al siguiente. Todos los decodificadores presentan también la misma estructura y reciben la entrada del último codificador y del descodificador anterior 9.
El codificador y el descodificador extraen significados de una secuencia de texto y comprenden las relaciones entre palabras y frases que contiene 3. Un codificador convierte el texto de entrada en una representación intermedia, y un descodificador convierte esa representación intermedia en texto útil 1.
Si la entrada es I am a good dog., un traductor basado en Transformer transforma la entrada en la salida Je suis un bon chien. que es la misma oración traducida en Francés 1.
La arquitectura de redes neuronales transformers permite utilizar modelos muy grandes, a menudo con cientos de miles de millones de parámetros. Estos modelos a gran escala pueden ingerir cantidades inmensas de datos, a menudo procedentes de Internet, pero también fuentes como Common Crawl, que comprende más de 50.000 millones de páginas web, y Wikipedia, que tiene aproximadamente 57 millones de páginas 3.
Durante el proceso de entrenamiento, estos modelos aprenden a predecir la siguiente palabra en una frase basada en el contexto proporcioando por las palabras precedentes. El modelo asigna una puntuación de probabilidad a la recurrencia de las palabras tokenizadas (divididas en pequeñas secuencias de caracteres). A continuación, estos tokens se transforman en embeddings, que son representaciones numéricas de este contexto 5.
Los transformers usando word embeddings, tambien conocidos como vectores multi dimensionales, pueden preprocesar el texto como representaciones numéricas mediante el codificador y comprender el contexto de las palabras y frases con signficados parecidos en un espacio vectorial, así como otras relaciones entre palabras, como las partes de la oración. Luego, los LLM pueden aplicar este conocimiento de la lengua a través del descodificador para producir un resultado 3.
Autoatención
Los transformers se basan en gran medida en un concepto llamado autoatención. La parte "auto" de la autoatención se refiere al enfoque "egocéntrico" de cada elemento de un corpus. En efecto, la autoatención se pregunta, en nombre de cada elemento de entrada: "¿Cuánto me importan los demás elementos de entrada?". Considera la siguiente frase 1:
El animal no cruzó la avenida porque estaba cansado.
Existen 9 palabras en la frase anterior, asi que cada una de las 9 palabras está prestando atención a las otras ocho, preguntándose cuánto les importa cada una de esas diez palabras.
Este mecanismo es capaz de asignar una puntuación, comúnmente denominada "peso", a una palabra dada, para determinar la relación con el resto 2.
La autoatención le permite al modelo "pesar" la importancia de las distintas partes de los datos de entrada. Así, los transformers pueden predecir una secuencia de lo que debería venir a continuación, como una función de autocompletado 6.

Top comments (0)