 I was recently fussing with a CSV file that had an inconsistent number of columns. UGH. There was a bunch of historical data that had 4 columns, and then more recent data had a new attribute added with 5 columns. I spent a few minutes cursing whoever was responsible, then moved on.
I was recently fussing with a CSV file that had an inconsistent number of columns. UGH. There was a bunch of historical data that had 4 columns, and then more recent data had a new attribute added with 5 columns. I spent a few minutes cursing whoever was responsible, then moved on.
First off, here’s a simplified version of what the data looked like. Notice that the first rows really should have a dangling comma at the end, to signify the 5th value is null:
ColumnName1,ColumnName2,ColumnName3,ColumnName4,ColumnName5
ValueA1,ValueA2,ValueA3,ValueA4
ValueB1,ValueB2,ValueB3,ValueB4
ValueC1,ValueC2,ValueC3,ValueC4
<1000s more rows>
ValueX1,ValueX2,ValueX3,ValueX4
ValueY1,ValueY2,ValueY3,ValueY4,ValueY5
<1000s more rows>
ValueZ1,ValueZ2,ValueZ3,ValueZ4,ValueZ5
Gross, right?
The SSMS Flat File Import Wizard agrees. It uses the first 50 rows to determine the file format for import. Since the first 50 rows only had 4 columns, it tries to do the import with that file format, and then errors out when it tries to insert the data that has 5 columns.
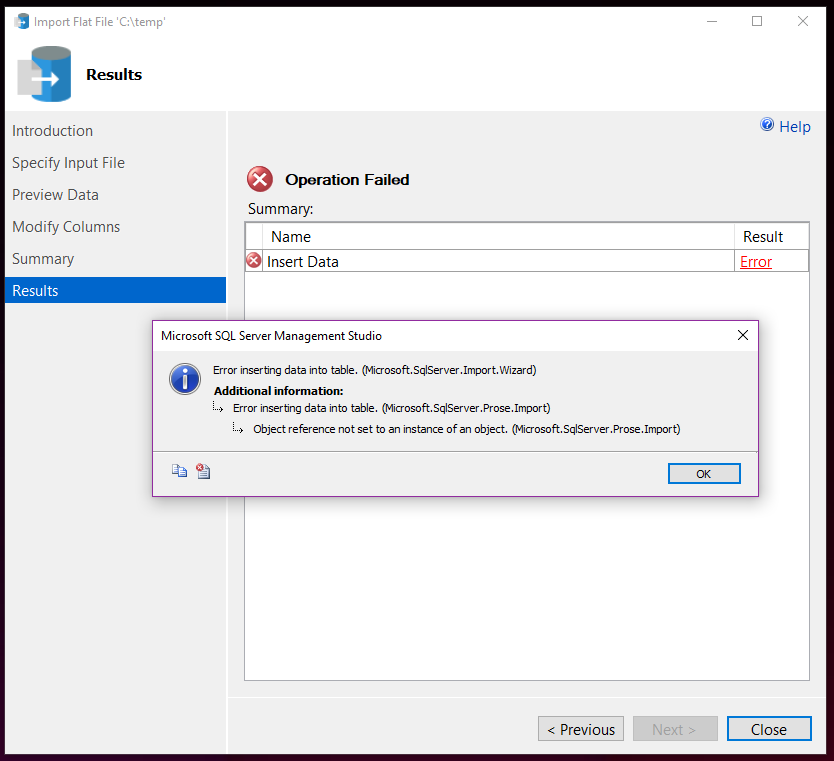
I wanted to fix it.
I was just goofing around with the data, so I didn’t really need anything perfect…but I did want something that was good enough to be repeatable, in case I wanted to do it again.
Fixing thousands of rows by hand sounded like torture. Heck. No.
The data was from a publicly available data set, so getting the file format fixed seemed like it would probably be neither quick nor easy. Depending on others could be a dead end, and while this would be the “rightest” solution to ensure a stable future fix, it was overkill for my casual playtime.
What about PowerShell?
I’ve used Import-Csv a whole bunch. I wondered if it would handle the wonky file layout. Quickest way to know is to try it. Let’s try to pull the CSV file into a PowerShell object and see what happens:
$MaybeThisWillWork = Import-Csv C:\temp\csv\ugly.csv
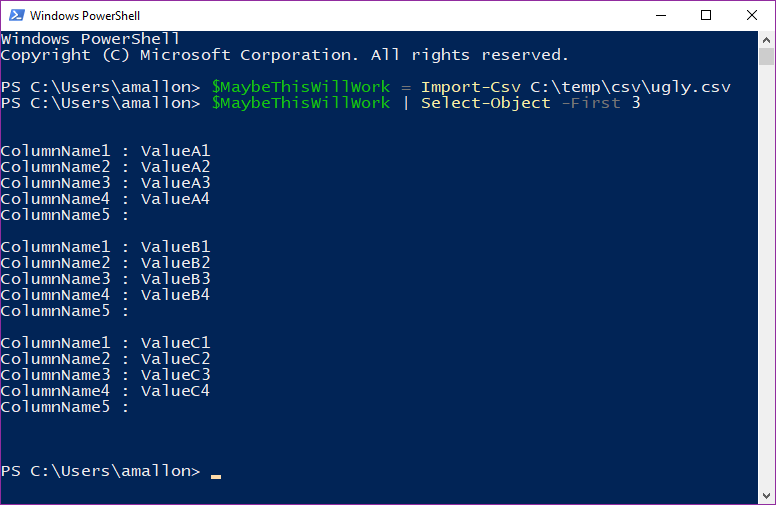
It worked?! Just like that? No errors? Color me pleasantly (but skeptically) surprised! Just to be sure, let’s check what the data looks like:
$MaybeThisWillWork | Select-Object -First 3
That looks right! It has the fifth column, with NULL values:
So now I can just export that PowerShell object to file using Export-Csv and I’m done:
$MaybeThisWillWork | Export-Csv C:\temp\csv\pretty.csv -NoTypeInformation
Sure enough, the text file now has an extra comma at the end. It’s also quoted, which I don’t mind at all. In fact, I wish more people consistently quotes their CSVs to avoid problems later.
"ColumnName1","ColumnName2","ColumnName3","ColumnName4","ColumnName5"
"ValueA1","ValueA2","ValueA3","ValueA4",
"ValueB1","ValueB2","ValueB3","ValueB4",
"ValueC1","ValueC2","ValueC3","ValueC4",
<1000s more rows>
"ValueX1","ValueX2","ValueX3","ValueX4",
"ValueY1","ValueY2","ValueY3","ValueY4","ValueY5"
<1000s more rows>
"ValueZ1","ValueZ2","ValueZ3","ValueZ4","ValueZ5"
If that worked, I should be able to import my pretty.csv file using the Flat File Import Wizard, now:
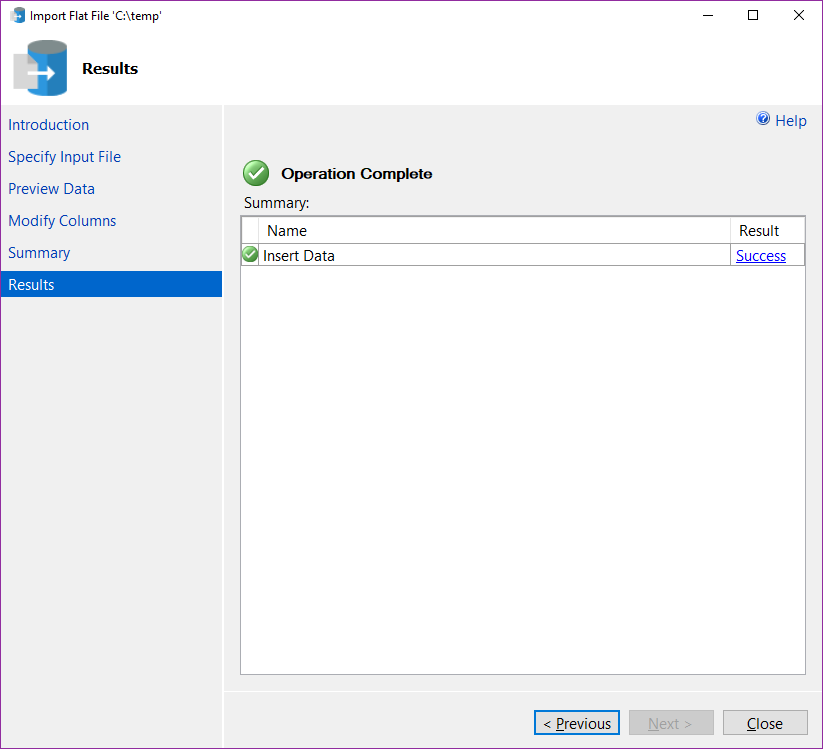
It worked! Awesome!
Now, if I need to do the same thing again, I know I can do it all in one step:
Import-Csv C:\temp\csv\ugly.csv | Export-Csv C:\temp\csv\pretty.csv -NoTypeInformation
If this were a mission-critical process, I’d much rather have the source CSV file fixed properly. Playing with random data for fun isn’t mission-critical. Though, maybe I should play with some better-formatted data, like these UFO sightings, or Amazon product reviews.
What about Azure Data Studio?
UPDATE: After posting this, Vicky Harp nudged me to try this in Azure Data Studio to see if there was the same problem there. Turns out, Azure Data Studio uses the same libraries, and has the same issue. I’ve logged an issue on GitHub to have that fixed. You can upvote that issue to help raise visibility to have it fixed!
The post Using PowerShell to tidy up CSV files appeared first on Andy M Mallon - AM².





Top comments (0)