Increasing Apache ShardingSphere adoption across various industries, has allowed our community to receive valuable feedback for our latest release.
Our team has made numerous performance optimizations to the ShardingSphere Kernel, interface and etc. since the release of Version 5.0.0. This article introduces some of the performance optimizations at the code level, and showcases the optimized results of ShardingSphere-Proxy TPC-C benchmark tests.
Optimizations
Correct the Use of Optional
java.util.Optional, introduced by Java 8, it makes the code cleaner. For example, it can avoid methods returningnull values. Optionalis commonly used in two situations:
public T orElse(T other) {
return value != null ? value : other;
}
public T orElseGet(Supplier<? extends T> other) {
return value != null ? value : other.get();
}
In ShardingSphere item org.apache.shardingsphere.infra.binder.segment.select.orderby.engine.OrderByContextEngine, an Optional code is used as:
Optional<OrderByContext> result = // Omit codes...
return result.orElse(getDefaultOrderByContextWithoutOrderBy(groupByContext));
In the orElse statement above, the orElse methods will be called even if the result isn’t null. If the orElse method involves modification operations, accidents might occur. In the case of method calls, the statement should be adjusted accordingly:
Optional<OrderByContext> result = // Omit codes...
return result.orElseGet(() -> getDefaultOrderByContextWithoutOrderBy(groupByContext));
Lambda is used to provide a Supplier to orElseGet. This way, theorElseGet method will only be called when the result is null.
Relevant PR:https://github.com/apache/shardingsphere/pull/11459/files
Avoid Frequent Concurrent calls for Java 8 ConcurrentHashMap’s computeIfAbsent
java.util.concurrent.ConcurrentHashMap is commonly used in concurrent situations. Compared to java.util.Hashtable, which modifies all operations with synchronized, ConcurrentHashMap can provide better performance while ensuring thread security.
However, in the Java 8 implementation even if the key exists, the method computeIfAbsent of ConcurrentHashMap still retrieves the value in the synchronized code snippet. Frequent calls of computeIfAbsent by the same key will greatly compromise concurrent performance.
This problem has been solved in Java 9. However, to avoid this problem and ensure concurrent performance in Java 8, we have adjusted the syntax in ShardingSphere’s code.
Taking a frequently called ShardingSphere class org.apache.shardingsphere.infra.executor.sql.prepare.driver.DriverExecutionPrepareEngine as an example:
// Omit some codes...
private static final Map<String, SQLExecutionUnitBuilder> TYPE_TO_BUILDER_MAP = new ConcurrentHashMap<>(8, 1);
// Omit some codes...
public DriverExecutionPrepareEngine(final String type, final int maxConnectionsSizePerQuery, final ExecutorDriverManager<C, ?, ?> executorDriverManager,
final StorageResourceOption option, final Collection<ShardingSphereRule> rules) {
super(maxConnectionsSizePerQuery, rules);
this.executorDriverManager = executorDriverManager;
this.option = option;
sqlExecutionUnitBuilder = TYPE_TO_BUILDER_MAP.computeIfAbsent(type,
key -> TypedSPIRegistry.getRegisteredService(SQLExecutionUnitBuilder.class, key, new Properties()));
}
In the code above, only two type will be passed into computeIfAbsent, and most SQL execution must adopt this code. As a result, there will be frequent concurrent calls of computeIfAbsent by the same key, hindering concurrent performance. The following method is adopted to avoid this problem:
SQLExecutionUnitBuilder result;
if (null == (result = TYPE_TO_BUILDER_MAP.get(type))) {
result = TYPE_TO_BUILDER_MAP.computeIfAbsent(type, key -> TypedSPIRegistry.getRegisteredService(SQLExecutionUnitBuilder.class, key, new Properties()));
}
return result;
Relevant PR:https://github.com/apache/shardingsphere/pull/13275/files
Avoid Frequent Calls of java.util.Properties
java.util.Properties is one of the commonly used ShardingSphere configuration classes. Properties inherites java.util.Hashtable and it's therefore necessary to avoid frequent calls of Properties under concurrent situations.
We found that there is a logic frequently calling getProperty in org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm, a ShardingSphere data sharding class, resulting in limited concurrent performance. To solve this problem, we put the logic that calls Properties under the init of InlineShardingAlgorithm, which avoids the calculation of concurrent performance in the sharding algorithm.
Relevant PR:https://github.com/apache/shardingsphere/pull/13282/files
Avoid the Use of Collections.synchronizedMap
While examining the ShardingSphere’s Monitor Blocked, we found a frequently called Map in org.apache.shardingsphere.infra.metadata.schema.model.TableMetaData, which is modified by Collections.synchronizedMap.
This affects concurrent performance. Modification operations only exist at the initial phase of the modified Map, and the rest are all reading operations, therefore, Collections.synchronizedMap modification method can directly be removed.
Relevant PR: https://github.com/apache/shardingsphere/pull/13264/files
Replace unnecessary String.format with string concatenation
There ShardingSphere item org.apache.shardingsphere.sql.parser.sql.common.constant.QuoteCharacter has the following logic:
public String wrap(final String value) {
return String.format("%s%s%s", startDelimiter, value, endDelimiter);
}
The logic above is obviously a string concatenation, but the use of String.format means it costs more than direct string concatenation. It's adjusted as follows:
public String wrap(final String value) {
return startDelimiter + value + endDelimiter;
}
We use JMH to do a simple test. Here are the testing results:
# JMH version: 1.33
# VM version: JDK 17.0.1, Java HotSpot(TM) 64-Bit Server VM, 17.0.1+12-LTS-39
# Blackhole mode: full + dont-inline hint (default, use -Djmh.blackhole.autoDetect=true to auto-detect)
# Warmup: 3 iterations, 5 s each
# Measurement: 3 iterations, 5 s each
# Timeout: 10 min per iteration
# Threads: 16 threads, will synchronize iterations
# Benchmark mode: Throughput, ops/time
Benchmark Mode Cnt Score Error Units
StringConcatBenchmark.benchFormat thrpt 9 28490416.644 ± 1377409.528 ops/s
StringConcatBenchmark.benchPlus thrpt 9 163475708.153 ± 1748461.858 ops/s
It’s obvious that String.format costs more than + string concatenation, and direct string concatenation's performance has been optimized since Java 9. This shows the importance of choosing the right string concatenation method.
Relevant PR:https://github.com/apache/shardingsphere/pull/11291/files
Replace Frequent Stream with For-each
java.util.stream.Streamfrequently appears in ShardingSphere 5. X's code.
In a previous BenchmarkSQL (TPC-C test for Java implementation) press testing — ShardingSphere-JDBC + openGauss performance test, we found significant performance improvements in ShardingSphere-JDBC when all the frequent streams were replaced by for-each.
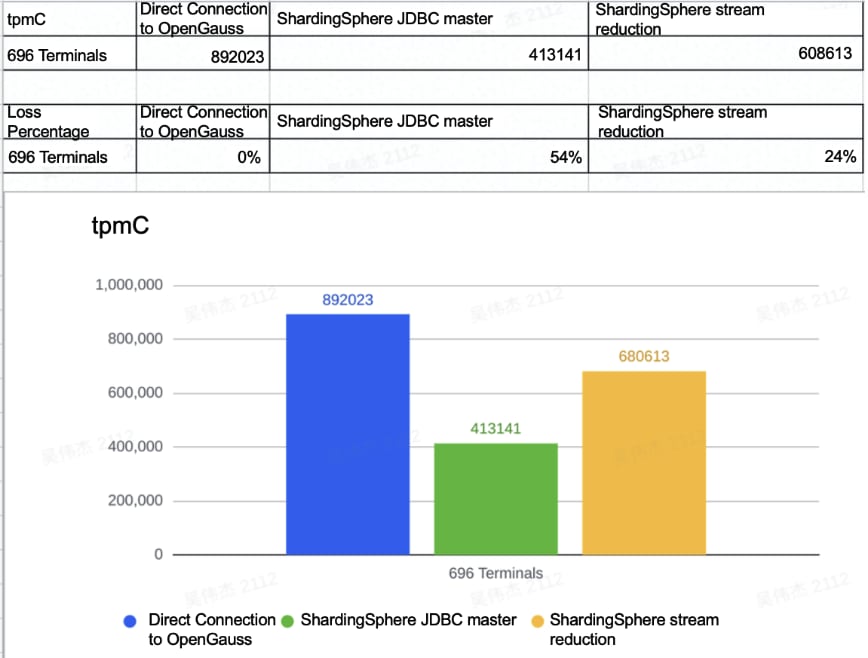
NOTE:ShardingSphere-JDBC and openGauss are on two separate 128-core aarch64 machines, using Bisheng JDK 8.
The testing results above may be related to aarch64 and JDK, but the stream itself does carry some overheads, and the performance varies greatly under different scenarios. We recommend for-each for logics that are frequently called and uncertain if their performances can be optimized through steam.
Relevant PR:https://github.com/apache/shardingsphere/pull/13845/files
Avoid Unnecessary Logic (Repetitive) calls
There are many cases of avoiding unnecessary logic repetitive calls:
- hashCode calculation
The ShardingSphere class
org.apache.shardingsphere.sharding.route.engine.condition.Columnimplements theequalsandhashCodemethods:
@RequiredArgsConstructor
@Getter
@ToString
public final class Column {
private final String name;
private final String tableName;
@Override
public boolean equals(final Object obj) {...}
@Override
public int hashCode() {
return Objects.hashCode(name.toUpperCase(), tableName.toUpperCase());
}
}
Obviously, the class above is unchangeable, but it calculates hashCode every time in hashCode implementation. If the instance is frequently put into or withdrawn from Map or Set, it will cause a lot of unnecessary calculation expenses.
After adjustment:
@Getter
@ToString
public final class Column {
private final String name;
private final String tableName;
private final int hashCode;
public Column(final String name, final String tableName) {
this.name = name;
this.tableName = tableName;
hashCode = Objects.hash(name.toUpperCase(), tableName.toUpperCase());
}
@Override
public boolean equals(final Object obj) {...}
@Override
public int hashCode() {
return hashCode;
}
}
Relevant PR:https://github.com/apache/shardingsphere/pull/11760/files
Replace Reflection Calls with Lambda
In ShardingSphere’s source code, the following scenarios require you to log methods and parameters calls, and replay method calls to the targets when needed.
- Send
beginand other syntaxes to ShardingSphere-Proxy. - Use
ShardingSpherePreparedStatementto set placeholder parameters for specific positions.
Take the following code as an example. Before reconstruction, it uses reflection to log method calls and replay. The reflection calls approach requires some overheads, and the code lacks readability.
@Override
public void begin() {
recordMethodInvocation(Connection.class, "setAutoCommit", new Class[]{boolean.class}, new Object[]{false});
}
After reconstruction, the overheads of the reflection calls method are avoided:
@Override
public void begin() {
connection.getConnectionPostProcessors().add(target -> {
try {
target.setAutoCommit(false);
} catch (final SQLException ex) {
throw new RuntimeException(ex);
}
});
}
Relevant PR:
https://github.com/apache/shardingsphere/pull/10466/files
https://github.com/apache/shardingsphere/pull/11415/files
Netty Epoll’s Support to aarch64
Since 4.1.50.Final, Netty’s Epoll has been available in Linux environments with aarch64 architecture. Under an aarch64 Linux environment, compared to Netty NIO API, performance can be greatly enhanced with the use of Netty Epoll API.
ShardingSphere-Proxy TPC-C Performance Test Comparison between 5.1.0 and 5.0.0 versions
We use TPC-C to conduct the ShardingSphere-Proxy benchmark test, to verify the performance optimization results. Due to limited support for PostgreSQL in earlier versions of ShardingSphere-Proxy, TPC-C testing could not be performed, so the comparison is made between Versions 5.0.0 and 5.0.1.
To highlight the performance loss of ShardingSphere-Proxy itself, this test will use ShardingSphere-Proxy with sharding data (1 shard) against PostgreSQL 14.2.
The test is conducted following the official file BenchmarkSQL Performance Test, and the configuration is reduced from 4 shards to 1 shard.
Testing Environment

Testing Parameters
BenchmarkSQL Parameters
- warehouses=192 (Data volume)
- terminals=192 (Concurrent numbers)
- terminalWarehouseFixed=false
- Operation time 30 mins
PostgreSQL JDBC Parameters
- defaultRowFetchSize=50
- reWriteBatchedInserts=true
ShardingSphere-Proxy JVM Partial Parameters
- -Xmx16g
- -Xms16g
- -Xmn12g
- -XX:AutoBoxCacheMax=4096
- -XX:+UseNUMA
- -XX:+DisableExplicitGC
- -XX:LargePageSizeInBytes=128m
- -XX:+SegmentedCodeCache
- -XX:+AggressiveHeap
Testing Results

The results drawn from the context and environment of this article are:
- With ShardingSphere-Proxy 5.0.0 + PostgreSQL as the benchmark, the performance of Apache ShardingSphere Version 5.1.0 is improved by 26.8%.
- Based on the direct connection to PostgreSQL, ShardingSphere-Proxy 5.1.0 reduces 15% loss compared to Version 5.0.0, from 42.7% to 27.4%.
The testing results above do not cover all optimization points since detailed code optimizations have been made throughout ShardingSphere modules.
How to Look at the Performance Issue
From time to time, people may ask, “How is ShardingSphere’s performance? How much is the loss?”
I believe that performance is good as long as it meets the demands. Performance is a complex issue, affected by numerous factors. There is no silver bullet for all situations. Depending on different environments and scenarios, ShardingSphere’s performance loss can be less than 1% or as high as 50%.
Moreover, ShardingSphere as an infrastructure, its performance is one of the key considerations in the R&D process. Teams and individuals in the ShardingSphere community will double down on pushing ShardingSphere performance to its limits.
Apache ShardingSphere Open Source Project Links:
ShardingSphere Github
ShardingSphere Twitter
ShardingSphere Slack Channel
Contributor Guide
Author
Wu Weijie
SphereEx Infrastructure R&D Engineer & Apache ShardingSphere Committer
Wu now focuses on the research and development of Apache ShardingSphere and its sub-project ElasticJob.


Top comments (0)