
What is RAG?
Retrieval-augmented generation (RAG) is a framework that enhances a large language model with an external data fetching or retrieving mechanism. When you ask a question, the RAG system first searches a knowledge base (database, internal documents, etc.) for relevant information. It then adds this retrieved information to your original question and feeds both to the LLM. This provides the LLM with context – the question and supporting documents – allowing it to generate more accurate, factually correct answers grounded in the provided information.
Breaking the concepts down:
- Retrieval: A tool or system searches a specific knowledge source (like your documents stored in Google Drive) for information relevant to your query before the LLM generates an answer.
- Augment: This retrieved information (context) is added to your original query, creating an 'augmented' or expanded prompt.
- Generation: The LLM then uses this augmented prompt (original query + retrieved context) to generate an answer grounded in the provided information, making it more accurate and relevant.
Why do we Need Retrieval Augmented Generation?
RAG addresses several limitations of standalone LLMs. Traditional LLMs are trained on large but static datasets and thus have a fixed knowledge cutoff. They can also “hallucinate” – producing plausible-sounding but incorrect or fabricated information – especially when asked about details they were never trained on, like private company data or new product specifics. Furthermore, verifying why a standard LLM gave a particular answer is complex. RAG helps overcome these issues by grounding the LLM's responses in specific, retrieved documents, which can also allow for traceability and verification of the generated information.
Let’s understand this visually.
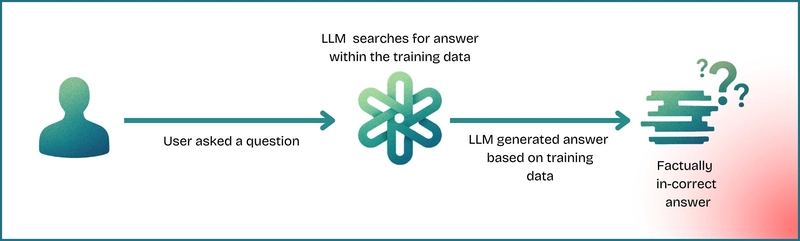
Let’s suppose an LLM is installed inside a company, ACME Corp., and an employee asks the LLM, “What are the features of the Saturn Analytics product?” This product is new, developed internally by ACME, and the details aren’t public yet. The LLM, which doesn’t know the actual information about this specific product (as it wasn't in its training data), might go on and fabricate some plausible-sounding features based on its general knowledge of analytics products or even unrelated information. This leads to factually incorrect information being produced. This is called hallucination.
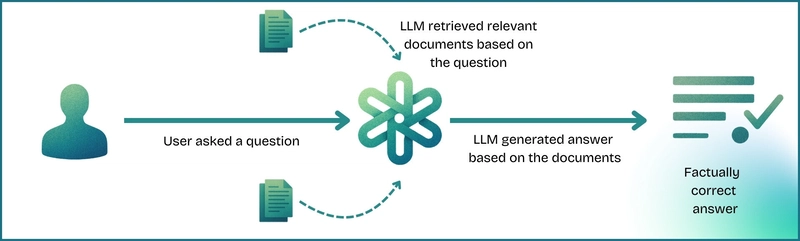
If the LLM has a tool to retrieve documents based on the user's query, the AI system can first search for relevant documents from a knowledge base. It then attaches this retrieved information to the original prompt (creating an 'augmented' prompt). Finally, the LLM generates an answer based on the context of these documents, producing factually correct information.
Now that we understand the need for RAG, let’s explore its benefits.
What are the benefits of RAG?
So, we saw how a standard LLM can struggle with specific or new information, sometimes leading to hallucinations. Retrieval-Augmented Generation (RAG) directly tackles these issues. Here are the main advantages:
- Access to Current and Specific Information: A RAG system retrieves information from an external source before answering. It can access up-to-the-minute data, private company documents, or any specific knowledge base you provide. This overcomes the static nature and knowledge cutoff of traditional LLMs.
- Improved Accuracy and Reduced Hallucinations: By grounding the LLM's answer in actual retrieved documents, RAG significantly cuts down on the model making things up. The LLM isn't just guessing based on its generalized training; it's constructing an answer based on the specific facts provided to it alongside the user's question.
- Trust and Verifiability: When a RAG system provides an answer, it's easy to see which documents it used for the retrieval step. This means you can potentially verify the information or understand the source of the answer, building trust in the answer that’s been generated.
- Cost-Effective Knowledge Updates: Instead of constantly undertaking expensive and complex retraining or fine-tuning of the entire LLM every time new information needs to be incorporated, you can simply update the external knowledge base that RAG retrieves from. Adding new product documents or updated information sheets is much cheaper and faster.
RAG transforms LLMs into reliable tools, making them more secure, knowledgeable, and practically useful for tasks that require specific, current, or proprietary information. This bridges the gap between the LLM's general capabilities and real-world information needs, giving you more confidence in your AI projects.
Next, consider the important tools we need to know for a RAG pipeline to work and start providing context before AI generates an answer.
How Can You Provide Information to an LLM for RAG?
We've established that giving an LLM access to external information is crucial for accurate, up-to-date answers. But how do we connect the LLM to this knowledge? Here are some standard techniques to build your RAG system:
Using Vector Databases for Semantic Search: In this method, we take your information (like product manuals, company policies, and articles) and then use an embedding model to convert each document into a numerical representation called a "vector." All these vectors are stored in a specialized vector database. When a user asks a question, the system searches the vector database for the text with the closest meaning (the closest vectors). This allows the LLM to find relevant information even if the user doesn't use the exact keywords in the documents.
Using APIs and External Tools (LLM Agents, Tool Calling, MCP): The LLM can also access "tools," including calling external APIs. This allows it to fetch real-time information (e.g., checking current stock prices, getting a weather forecast, querying a specific company microservice) that isn't stored in any static document collection. This approach often moves into the territory of "LLM Agents," where the LLM can interact more dynamically with external systems. You can read about this approach in detail here.
Querying Structured Databases (SQL): Sometimes, the crucial information isn't in unstructured documents but neatly organized in structured databases (like SQL databases). For these cases, you can implement techniques often called "Text-to-SQL." The system takes the user's natural language question, translates it into a formal SQL query, runs that query against the database, and retrieves the specific data rows needed. This retrieved data is then provided to the LLM as context.
Building an effective RAG system involves a thoughtful process, not just plugging in an LLM. We'll soon dive into the specifics and utilize powerful Semantic Search with vector databases to retrieve the relevant information. We'll also discuss how frameworks like LangChain can significantly simplify orchestrating these components.
In point 2, MCPs are mentioned, which you can read more about here. However, many people confuse the difference between MCPs and RAG. And make baseless claims such as “RAG is dead because of MCPs.” In this section, we share different approaches to RAG. As we discussed, the core idea is to give data to the LLM, which can happen in various ways. Let’s explore the differences between MCP and RAG to provide you with a clear understanding of how they’re different and the same.
RAG and MCP: Is RAG Dead?
Many people often confuse the main concept or philosophy with the tools. RAG becomes synonymous with vector databases, LangChain, embeddings, search engines, data pipelines, and so on. However, this is not the case. As we discussed, RAG is a method to fetch data and provide context by augmenting the prompt before AI generates an answer, making it more accurate and factually correct.
We should also discuss MCPs, which stands for Model Context Protocol, developed by Anthropic for its Claude AI. It is a way to access different databases, tools, functions, etc., and perform actions like scraping web pages, fetching relevant documentation, and reading the latest queries from the database.
This connectivity allows the AI model to perform various actions, execute specific functions, and retrieve necessary data from diverse sources. MCPs (or the tools/servers operating via this protocol) can effectively function as the Retriever within the RAG architecture. This method of gathering information might differ from, or even bypass, other standard retrieval tools (like simple vector search). However, it's crucial to understand that even when retrieval is managed through an MCP, the fundamental process still constitutes RAG, as external knowledge is actively retrieved to augment the prompt before the AI generates its final response.
So, MCP doesn’t mean that RAG is dead. It means we have found a way to fetch data that is easier to set up, but the usage depends on the person or company’s needs.
Long Context AI models and RAG: Once again, is RAG dead?

Meta AI has released the Llama 4 series of AI models, featuring a massive 10 million token context window. To put that in perspective, it can hold the entire Harry Potter, Lord of the Rings, and Game of Thrones book series—with room to spare. This expanded context allows the model to process and reason across much larger text spans, enabling deeper, more coherent outputs.
The idea behind RAG (Retrieval-Augmented Generation) is simple: It's not just about what the LLM knows but how we can provide it with the right context. In many real-world applications, the LLM either needs to retrieve relevant data or be provided with it on the fly to generate informed, accurate responses.
Conclusion: Giving LLMs Context with RAG
In short, while standard LLMs are impressive, their fixed knowledge and tendency to hallucinate limit their practical use with specific or current data. Retrieval-Augmented Generation (RAG) offers a powerful fix by enabling LLMs to first retrieve relevant information from your chosen sources, augment their prompts with this context, and then generate factually grounded answers. RAG is key to transforming LLMs from general conversationalists into reliable, knowledgeable tools for specific, real-world applications, and we explored this idea in this article.
This is a 3-part article. In the next one, we will dive deep into how to code a RAG solution using the tools and frameworks mentioned. This will give you a more hands-on approach and confidence in building a retrieval-augmented generation pipeline for your project.
Extra Resources for the Brave
Thank you for reading. If you seek in-depth research papers and articles to increase your understanding. You can follow the links below:

Top comments (22)
There has been some real questions around Llama 4 and it's benchmark results. But the 10 Mn context window is very big. That's an achievement.
The benchmarks vs. Real world usage is something else.
This is from reddit.
If you'd like to read about that, then here's a resource for you: arxiv.org/abs/2310.01889
The concept is Ring-Attention :)
This is useful
💖✨
Hey! 👋 I’ve been exploring different ways to turn ideas into functional UI faster, and recently came across (and started using) SketchFlow — a tool that helps convert rough sketches or wireframes into clean HTML/Tailwind code. It's super handy when you want to focus on flow and layout before diving deep into styling or logic.
Still early days, but it’s been a neat productivity boost for me. Would love to know if anyone else has tried something similar — always curious about tools that speed up the dev-design loop! 💡
Great work if that's your tool. How it's useful to RAG?
Thank you bro
You're welcome bro 😎
Thank you for sharing this. Really helpful.
I'm glad you liked it!
useful
thanks :)
Awesome Read
Really helpful dude!
Thank you
Thanks!
💖✨
I've tried my best to break down the concepts of Retrieval Augmented Generation and some questions people keep asking around "Is RAG dead?"
I hope people will like it!
😂 Rag is dead, long live rag. I've seen many posts like that.
Great work though
Thanks!
Some comments may only be visible to logged-in visitors. Sign in to view all comments.