
Machine learning(ML) is everywhere, you look around, you will see some or the other application is either built using ML or powered by ML. And with the advent of technology, specially cloud, every passing day ML is getting more and more reachable to developers, irrespective of their background. We at Amazon Web Services(AWS) are committed to put machine learning in the hands of every developer, data scientist and expert practitioner. Now, what if you can create, train and deploy a machine learning model using simple SQL commands?
During re:Invent 2020 we announced Amazon Redshift ML which makes it easy for SQL users to create, train, and deploy ML models using familiar SQL commands. Amazon Redshift ML allows you to use your data in Amazon Redshift with Amazon SageMaker(a fully managed ML service), without requiring you to become experts in ML.
Now, before we dive deep into what it is, how it works, etc. here are the things we will try to cover in this first part of the tutorial:
- What is Amazon Redshift
- Introduction to Redshift ML
- How to get started and the prerequisites
- I am a Database Administrator - What's in for me ?
And in the Part-2, we will take that learning beyond and cover the following:
- I am a Data Analyst - What's about me ?
- I am a Data Scientist - How can I make use of this ?
Overall, we will try to solve different problems which will help us to understand Amazon Redshift ML from a perspective of a database administrator, data analyst and an advanced machine learning expert.
Before we get started and set the stage by reviewing what is Amazon Redshift?
Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehousing service on the AWS. Its low-cost and highly scalable service, which allows you to get started on your data warehouse use-cases at a minimal cost and scale as the demand for your data grows. It uses a variety of innovations to obtain very high query performance on datasets ranging in size from a hundred gigabytes to a petabyte or more. It uses massively parallel processing(MPP), columnar storage and data compression encoding schemes to reduce the amount of I/O needed to perform queries, which allows it in distributing the SQL operations to take advantage of all available resources underneath.
Let's quickly go over few core components of an Amazon Redshift Cluster:

Client Application
Amazon Redshift integrates with various data loading and ETL (extract, transform, and load) tools and business intelligence (BI) reporting, data mining, and analytics tools. As Amazon Redshift is based on industry-standard PostgreSQL, most of commonly used SQL client application should work, we are going to use Jetbrains DataGrip to connect to our Redshift cluster(via JDBC connection) later while we jump into the hands-on section. Having said that, you may like to use any other SQL Client tool like SQL Workbench/J, psql tool, etc.
Cluster
The core infrastructure component of an Amazon Redshift data warehouse is a cluster. A cluster is composed of one or more compute nodes. A cluster comprises of nodes, as shown in the above image, Redshift has two major node types: leader node and compute node.
Leader Node
If we create a cluster with two or more no. of compute nodes, then an additional leader node coordinates the compute nodes and handles external communication. We don't have to define a leader node, it will be automatically provisioned with every Redshift cluster. Once the cluster is created, the client application interacts directly only with the leader node. In other words, the leader node behaves as the gateway(the SQL endpoint) of your cluster for all the clients. Few of the major tasks of the leader node is to store the metadata, coordinate with all the compute nodes for parallel SQL processing and and to generate most optimized and efficient query plan.
Compute Nodes
The compute nodes is the main workhorse for the Redshift cluster, and it sits behind the leader node. The leader node compiles code for individual elements of the execution plan and assigns the code to individual compute node(s). After that, the compute node(s) execute the respective compiled code and send intermediate results back to the leader node for final aggregation. Each compute node has its own dedicated CPU, memory, and attached storage, which are determined by the node type.
The node type determines the CPU, RAM, storage capacity, and storage drive type for each node. Amazon Redshift offers different node types to accommodate different types of workloads, so you can select which suits you the best, but its is recommended to use ra3. The new ra3 nodes let you determine how much compute capacity you need to support your workload and then scale the amount of storage based on your needs.
Ok, now that we understood a bit about the Redshift Cluster let's go back to the main topic, Redshift ML :)
And don't worry if things are still dry for you, as soon as we jump into the demo and create a cluster from scratch, things will fall in place.
Introduction to Redshift ML
We have been integrating ML functionality with many other services for long time, for example in re:Invent 2019, we announced Amazon Aurora Machine Learning, which enables you to add ML-based predictions to your applications via the familiar SQL programming language. Integration with ML is very important in today's world we live in. It helps any developer to build, train, and deploy your ML models efficiently and at scale.
Following the ritual, during re:Invent 2020, we announced this new capability called Redshift ML, which enables any SQL user to train, build and deploy ML models using familiar SQL commands, without knowing much about machine learning. Having said that, if you are an intermediate machine learning practitioner or an expert Data Scientist, you still get the flexibility to define specific algorithms such as XGBoost and specify hyperparameter and preprocessor.
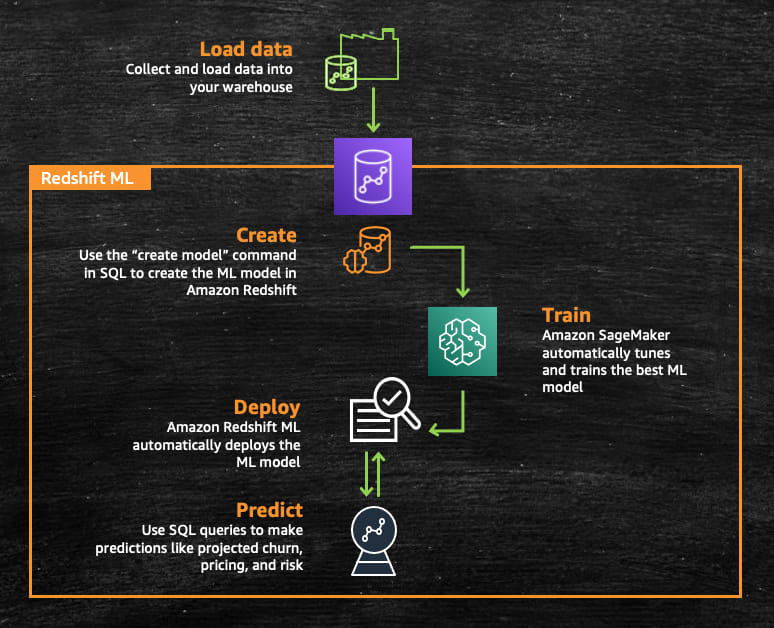
The way it works is pretty simple, you provide the data that you want to train the model and metadata associated with data inputs to Amazon Redshift and then Amazon Redshift ML creates the model that capture patterns in the input data. And once the model is trained, you can then use the models to generate predictions for new input data without incurring additional costs.
As of now, Amazon Redshift supports supervised learning, that includes the following problem types:
regression: problem of predicting continuous values, such as the total spending of customersbinary classification: problem of predicting one of two outcomes, such as predicting whether a customer churns or notmulti-class classification: problem of predicting one of many outcomes, such as predicting the item a customer might be interested
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value.
The inputs used for the ML model are often referred to as features or in ML terms, called independent variables, and the outcomes or results are called labels or dependent variables. Your training dataset is a table or a query whose attributes or columns comprise features, and targets are extracted from your data warehouse. The following diagram illustrates this architecture.

Now, we understand that data analysts and database developers are very much familiar with SQL, as they use that day-in day-out. But to build, train and deploy any ML model in Amazon SageMaker, one need to learn some programming language(like Python) and study different types of machine learning algorithms and build an understanding of which algorithm to use for a particular problem. Or else you may rely on some ML expert to do your job on your behalf.
Not just that, even if someone helped you to build, train and deployed your ML model, when you actually need to use the model to make some prediction on your new data, you need to repeatedly move the data back and forth between Amazon Redshift and Amazon Sagemaker through a series of manual and complicated steps:
- Export training data to Amazon Simple Storage Service (Amazon S3).
- Train the model in Amazon SageMaker.
- Export prediction input data to Amazon S3.
- Use prediction in Amazon SageMaker.
- Import predicted columns back into the database.
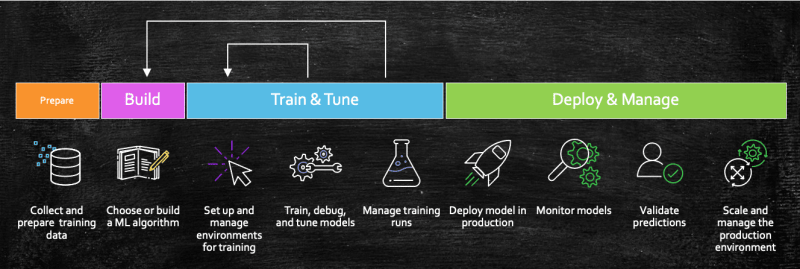
All this is daunting, isn't it?
But now, with Amazon Redshift ML, we don't have to do any of these, you can train model with one single SQL CREATE MODEL command. So, you don't have to expertise in machine learning, tools, languages, algorithms, and APIs.
Once you run the SQL command to create the model, Amazon Redshift ML securely exports the specified data from Amazon Redshift to Amazon S3 and calls SageMaker Autopilot to automatically prepare the data, select the appropriate pre-built algorithm, and apply the algorithm for model training. Amazon Redshift ML handles all the interactions between Amazon Redshift, Amazon S3, and SageMaker, abstracting the steps involved in training and compilation.
And once the model is trained, Amazon Redshift ML makes model available as a SQL function in your Amazon Redshift data warehouse.
Ok, let's see all in action now...
Create Redshift Cluster
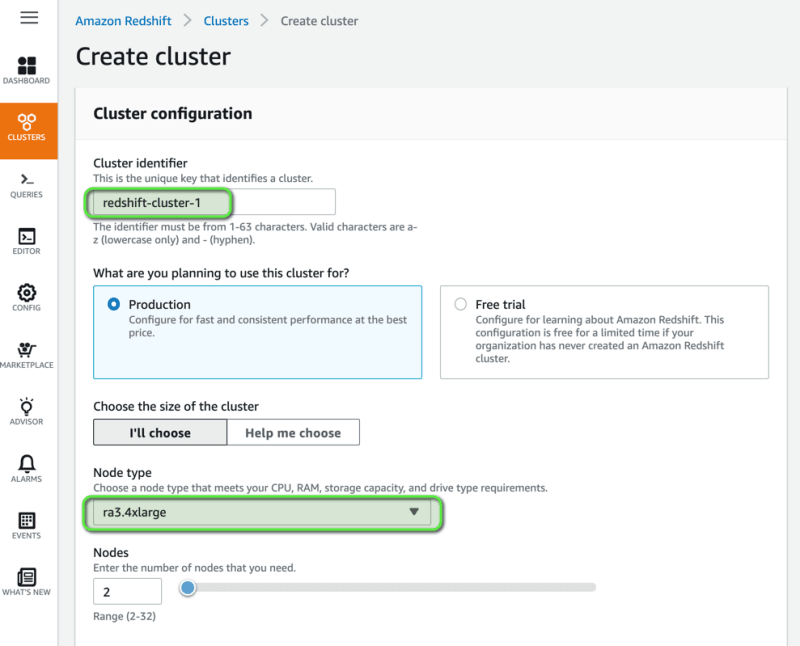
Let's create a Redshift Cluster now, first we need to login to our AWS Console and search for Redshift and click on Create cluster.

Next, in the Cluster configuration section, we need to provide some cluster identifier, let's say redshift-cluster-1 and select the appropriate node type and number of nodes you would like to have in the cluster. As mentioned before, we recommend to choose RA3 node types, like ra3.xplus, ra3.4xlarge and ra3.16xlarge which offers the best in class performance with scalable managed storage. For our demo we will select ra3.4xlarge node type and we will create the cluster with 2 such nodes.
After than under Database configuration, we need to provide our database name, port number(where the database will accept the inbound connections), master user name and password.

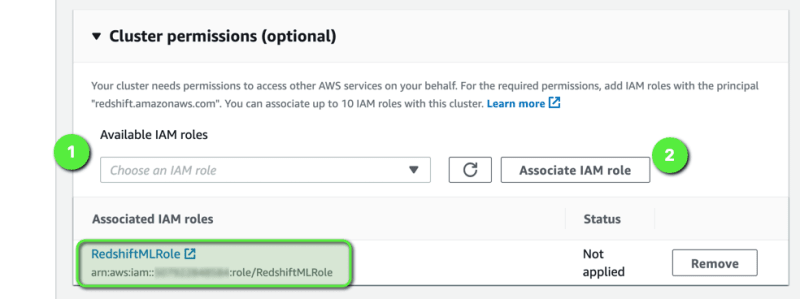
Next, we need to expand the Cluster permissions section and attached an IAM role. Since our cluster would use Amazon S3 and Amazon SageMaker later on, we need to provide adequate permission so that our Redshift cluster can access data saved in Amazon S3, and Redshift ML can access Amazon SageMaker to build and train the model. We have already created an IAM role namely, RedshiftMLRole. We can just select the right IAM role from the dropdown and click on Associate IAM role
If you want to create an IAM role with a more restrictive policy, you can use the policy as following. You can also modify this policy to meet your needs.

Also, if you would like to connect to this cluster from instances/devices outside the VPC via the cluster endpoint, you would need to enabled Public accessible option as bellow, but it is not recommended to enable Public accessible, in our demo we are going to use an Amazon EC2 Instance to connect to the cluster via SSH Tunneling:

Just review all the configurations and click on Create cluster

Connecting to Redshift Cluster
Next, we can use any tool of our choice to connect to our cluster and we are going to use Jetbrains DataGrip.
Now, if you have created the cluster with
Public accessible enabled, then you can directly connect with the cluster, but since we created the cluster without public access, we are going to use Amazon EC2 Instance to connect to the cluster via SSH Tunneling as mentioned above. And for that we have already created an Amazon EC2 instance in the same region where we created our Redshift cluster and we are going to use the same instance to access the cluster via SSH Tunning.
But before we connect, we need to fist know the JDBC URL endpoint of our cluster, for that we can click on our cluster and copy the JDBC URL in our clipboard


Now, we can open Datagrip(or any tool of your choice and connect to the cluster) using the JDBC URL, user name and password which we have used while creating the cluster and text the connection.
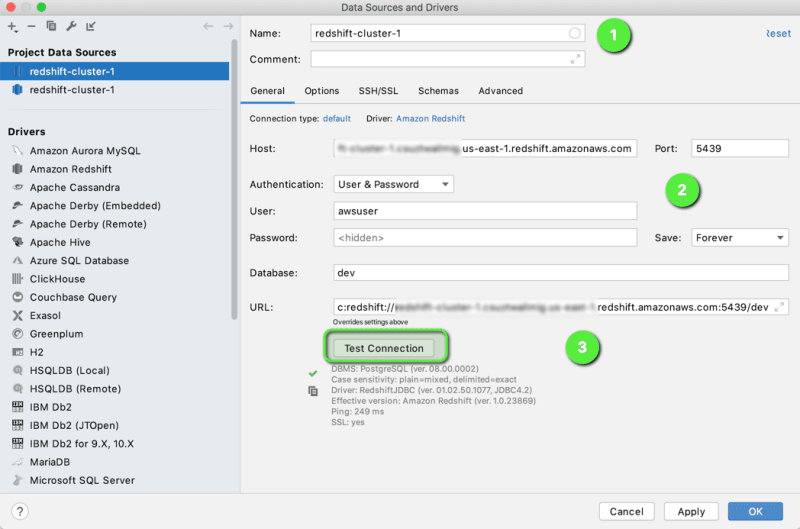
And then go to the SSN/SSL option to add the tunnel, this is the place where we need to mention the Amazon EC2 Instance details which we had created earlier and once that is done, we can click on Test Connection to test if everything is working fine or not.

Ok, we are now all set to see Redshift ML all in action :)
Dataset
We are going to see 3 demos next showing different aspects and functionalities of Redshift ML, which will hopefully help you to get an understanding of different use cases and learn how you make use of Redshift ML irrespective of your background. You may be a Database Engineer/Administrator or Data Analyst or an advanced Machine Learning practitioner, we will cover different demo from the perspective of all these different personas.
First we need to make sure we upload the dataset on S3(we have uploaded all the dataset in our Amazon S3 bucket, redshift-downloads-2021). All the dataset can be found inside this GitHub repo
Exercise 1 (Database Engineer's perspective)
Dataset
In this problem, we are going to use the Bank Marketing Data Set from UCI Machine Learning Repository. The data is related with direct marketing campaigns of a Portuguese banking institution. The marketing campaigns were based on phone calls. Often, more than one contact to the same client was required, in order to access if the product (bank term deposit) would be ('yes') or not ('no') subscribed.
The objective is to predict if the client will subscribe (yes/no) a bank term deposit (variable y).
The dataset consists of total 20 features/input variable and one class label/output variable.
Since our dataset is located in Amazon S3, first we need to load the data in table. We can open DataGrip(or whatever SQL Connector you are using) and create the schema and the table. Once that is done, we can use COPY command to load the training data from Amazon S3(bank-additional-full.csv) to the Redshift cluster, in the table, client_details
We need to make sure that colum names of the table matches with the feature sets in the CSV training dataset file.

Similarly we can load the dataset for the testing(bank-additional-inference.csv) in a separate table, client_details_inference

Users and Groups
Before we try to create the model, we need to make sure that the user is having the right permission. Just like how Amazon Redshift manages other database objects, such as tables, views, or functions, Amazon Redshift binds model creation and use to access control mechanisms. There are separate privileges for creating a model running and prediction functions.
Here are going to create 2 user groups, dbdev_group(users who will use the model for prediction) and datascience_group(users who will create the model) and within these groups we will have one user each, dbdev_user and datascience_user respectively.
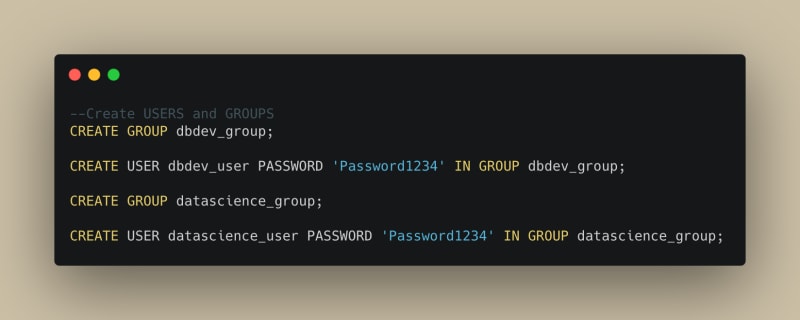
Next, we can grant the appropriate access/permission to the respective group and authorize the user datascience_user as the current user.

Training (Model Creation)
Finally, now we are all set to create the model using a simple CREATE MODEL command, it will export the training data, train a model, import the model, and prepare an Amazon Redshift prediction function under the hood.

Two things to note here:
- The
SELECTquery above creates the training data(input features), i.e. all columns except columny - The
TARGETclause specifies which column should be used asclass labelthat theCREATE MODELshould uses to learn how to predict, i.e. theycolumn.
Behind the scene, Amazon Redshift will use Amazon SageMaker Autopilot for training. At this point, Amazon Redshift will immediately start to use Amazon SageMaker to train and tune the best model for this binary classification problem(as the output or class label can be either yes or no).
The CREATE MODEL command operates in an asynchronous mode and it returns upon the export of training data to Amazon S3. As the remaining steps of model training and compilation can take a longer time, it continues to run in the background.
But we can always check the status of the training using the STV_ML_MODEL_INFO function.

Once the training is done, we can use SHOW MODEL ALL command to see all the models which we have access to:
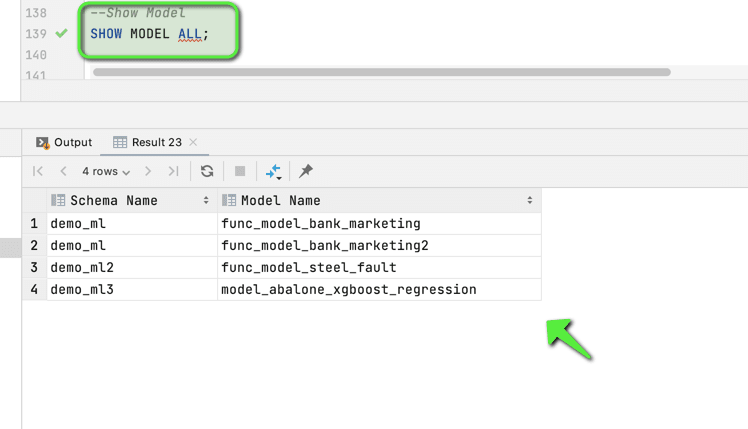
We can also see some more details about the model, e.g. model performance(like accuracy, F1 score, MSE, etc. depending on the problem type), model type, problem type, etc.

Accuracy of the Model and Prediction/Inference
Now that we have the new SQL function, func_model_bank_marketing2, we can use the same function for prediction. But before we do so, let's first grant the appropriate access/permission to the dbdev_groupso that the dbdev_user can use the function for prediction. Once that is done we can change the authorization to dbdev_user as we expect that the prediction operation to be executed by the database engineer or the data analyst and not necessarily by only the data scientists in the organization.

First let's try to see what's the accuracy of out model, using the test data which we have in the client_details_inference table.

As we can see the accuracy is around 94%, which is not all that bad considering the small dataset we used for this problem, but we can see how easily we use simple SQL query to create, train and deploy our ML models using Redshift ML.
And finally let's try to do some prediction using this same model function
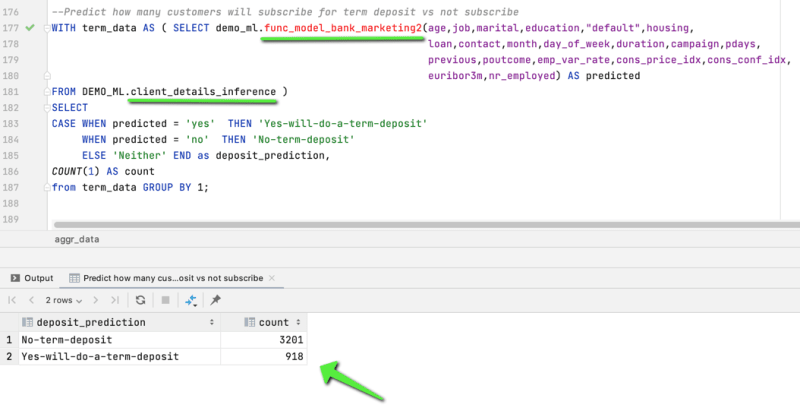
In the Part 2 of this tutorial series we will try to cover few more advanced functionalities, and those would be from a Data Analyst or any expert Data Scientist viewpoint, wherein you can define many advanced options, like model type, hyperparameters, objective function, pre-processors, and so on.
But before we move on to the Part 2, let's spend some time to underhand the costs consideration using Redshift ML and how you can control it.
Cost and Redshift ML
As Amazon Redshift ML use the existing cluster resources for prediction, there is no additional Amazon Redshift charges. That means, there is no additional Amazon Redshift charge for creating or using a model,
and as prediction happens locally in your Amazon Redshift cluster, you don't have to pay extra.
But, as we learnt that Amazon Redshift ML uses Amazon SageMaker for training our model, which does have an additional associated cost.
The CREATE MODEL statement uses Amazon SageMaker as we have seen before, and that incurs an additional cost. The cost increases with thenumber of cells in your training data. The number of cells is proportional to number of records (in the training query or table) times the number of columns. For example, when a SELECT query of the CREATE MODEL statement creates 100,000 records and 50 columns, then the number of cells it creates is 500,0000.
One way to control the cost is by using two option MAX_CELL and MAX_RUNTIME in the CREATE MODEL command statement. Where MAX_RUNTIME specifies the maximum amount of time the training can take in SageMaker when the AUTO ON/OFF option is used. Although training jobs can complete sooner than MAX_RUNTIME, depending on the size of the dataset. But there are additional works which Amazon Redshift performs after the model is trained, like compiling and installing the model in your cluster. So, the CREATE MODEL command can take a little longer time then then MAX_RUNTIME to complete. This option can be used to limit the cost as it controls the time to be used by Amazon SageMaker to train your model.
Under the hood, when you run CREATE MODEL with AUTO ON, Amazon Redshift ML uses SageMaker Autopilot which automatically explores all the different models(or candidates) to find the best one. MAX_RUNTIME limits the amount of time and computation spent and if MAX_RUNTIME is set too low, there might not be enough time to explore even one single candidate. And you would get an error saying, "Autopilot candidate has no models" and in that case you would need to re-run the CREATE MODEL with a larger MAX_RUNTIME value.
One another way to control cost for training (which may not be a good idea always as it would affect the model accuracy), is by specifying a smaller MAX_CELLS value when you run the CREATE MODEL command. MAX_CELLS limits the number of cells, and thus the number of training examples used to train your model.
By default, MAX_CELLS is set to 1 million cells. Reducing MAX_CELLS reduces the number of rows from the result of the SELECT query in CREATE MODEL that Amazon Redshift exports and sends to SageMaker to train a model. Reducing MAX_CELLS thus reduces the size of the dataset used to train models both with AUTO ON and AUTO OFF. This approach helps reduce the costs and time to train models.
In summary, by increasing MAX_RUNTIME and MAX_CELLS we can often improve the model quality as it allows Amazon SageMaker to explore more candidates and it would have more training data to train better models.
What next...
So, in the tutorial we learnt a bit about, what Amazon Redshift is and how you can create, train and deploy a ML model using familiar SQL query from a Database Engineer's/Administrator's perspective, in the next part we will explore little bit more on how you can make use of Amazon Redshift ML if you are an advanced data analyst or a data scientist and shall explore some advanced options, which it has to offer.
Resources
- Code : GitHub repo
- Blog : Amazon Redshift ML - Machine Learning in SQL Style (Part-2)
- Documentation:
- Book:
- Videos:





Top comments (0)