
Simulations are NOT the Real World
The Problem
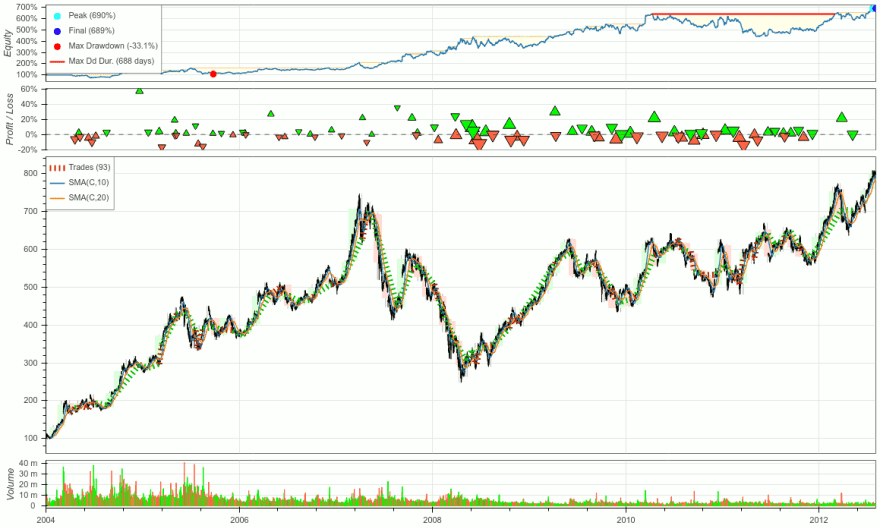
It’s super easy to get up and running with code. With the rise of data science as a field, datasets are far and wide. Accessible from just about any venue. Take a look at Kaggle, QuiverQuant, Yahoo Finance, or even directly from the brokerages and exchanges. Developers can easily download data directly as a .csv or .json and quickly get up and running by utilizing frameworks like backtesting.py or vectorbt. “Great, it seems like I can get up and running and I’ll have an awesome money making trading algorithm in no time”.... unfortunately, wrong. Why is this wrong? Well, simulation is NOT the real world. The real world is not a CSV file—the real world is a stream of events. Cause and effect. The real world works in a fashion where new data comes in, you make a decision, and then you figure it out, not “I have all of this data, let me run this all through time and figure it out”. Indeed, the data sources that you get in real-time are almost completely different from the data sources you use in simulation. Rather than .csv you use WebSockets; rather than QuiverQuant you use APIs; rather than backtesting frameworks you use more robust, event driven packages. Without it, you’re stuck duplicating code, rewriting it into an event-based system, and ultimately using that to go into production, and who knows if your code is going to change along the way.
The Solution
Use an Event-Driven Package
As mentioned, focus on building trading algorithms with the production world in mind. It is perfectly fine to utilize a vectorized backtesting system for rapid iteration, but be prepared to have to rewrite your code to put it into a paper trade or live environment. An event-driven backtesting system can provide much more power and flexibility.
As by design, it can be integrated for both historical backtesting and live trading without compromising the overall structure and logic. As vectorized backtesting requires all data to be available at once to perform any sort of analysis, this is not possible, of course, in a live environment, with no data of the future at hand.
It can prevent look-ahead bias. An event-driven backtester will never factor future data—instead, it takes each point of the most recent market data as an event to act upon.
Event-driven backtesters provide customization in market orders. From basic market to limit orders, to market-on-open and market-on-close orders, stop orders, and more, they can all be built in as a custom handler.
Focus on Figuring Out Your Live Data Sources Early
Again, it’s super easy to think that you’ll have all the data in the world in the real environment. Most of the time, the data you have in testing is very different from the data that you receive from the real environment—and ensuring that you’re able to match up the two, easily format the data into the same way is going to be super super important. Figuring out where your historical datasets come from and corollary live data streams will come from will be imperative.
So uh....where am I going to make trades?
The Problem
Let’s take, for example, the crypto world. In this space, there are over ten difference crypto exchanges all with their different ploys and different opportunities, including Binance, Coinbase, FTX, Kraken, KuCoin, and much, much more. Some originate in Fiat, others originate in crypto. Moreover, what if you wanted to switch your trading algorithm to run on forex or stocks? The list of exchanges increase by the dozen, and each one is its own independent entity. These kinds of questions, though a little less important in a backtesting environment, become imperative in a live environment. In order to make trades, you HAVE to connect to an exchange or brokerage... there’s no way around it. For many, the connection to an exchange is completely skipped over during the testing and experimental stage. Again, de facto-ing to downloading datasets is great, but how will you operate on the logic of making trades? How are you going to switch your algorithm into a paper trade environment for every exchange? These are critical questions to ask yourself as you implement your trading algorithm: what asset are you going to use, what exchange are you going to integrate with, and how are you going to actively manage and maintain that exchange as it changes its API (look at Alpaca, they’ve been constantly changing their APIs and systems).

The Solution
For all the DIYBIY people out there, this is probably one of the largest pain points. You have to actively manage exchange connections while also maintaining your code and ensuring that your strategy is always updating and improving. If you know that you’re going to just be using one exchange or asset type, this is relatively easy as there are typically wrappers in various languages for each exchange. However, if you are not really sure and you plan on changing, choosing a cross-asset and cross-exchange package such as CCXT that allows you to test and deploy between multiple with ease is a game-changer. The worst case scenario you let your model run and the exchange changes their API, so offset this risk to someone else so you can focus on building a better trading algorithm.
What’s my deployment infrastructure?
The Problem
This is the biggest whammy of them all. How are you going to launch and deploy your trading algorithms? Now that you have code that works, and assuming that you have solved problems 1 and 2, you’re going to have figure out problem 3. Are you going to choose AWS or GCP? Are you going to choose a cluster near the exchange? Are you going to SSH into the EC2 instance? What about DigitalOcean? Do I use a cloud run instance or do I use a lambda function? The number of decisions that you have to make just to deploy your trading algorithm is a whole new skillset of cloud that you don’t want to worry about. Don’t want to use the cloud? How are you going to actively manage firewall connections, security, ensuring that your computer is always on, that your desktop is running. How can you make sure your wifi doesn’t cut out? All of these questions are important considerations as you begin moving deeper into automated trading.
Again, what was your goal at the beginning? It was to make sure that we had an automated system that can make trades; NOT a system that we have to constantly worry about.
The Solution
There really isn’t any solution around this. The best way to do this is to deploy onto the cloud into an optimized environment. Yet managing CPU, RAM, and other issues like monitoring, SSH’ing, configuring security for API keys, ensuring isolation and proper firewall connections are going to be a major pain.
So, how can we help?
Building a trading algorithm is not just about building a strong strategy. Though that is a precursor to everything, not building it the proper way can lead to major complications, especially in production. Imagine spending 2 months building out an optimized algorithm and an optimized system only to realize that it won’t work in production. That’s how Blankly came to existence—we were looking for the best solution possible to put together each of these problems, and ultimately take away the backend, infrastructure side of making trading algorithms.
With the Blankly Package to help with maintaining active exchange connections and optimized event-driven backtesting, and the Platform to deploy your algorithms and monitor your strategies live in the cloud, your quant workflow is sped up from head to toe. The barrier to entry shouldn’t be around infrastructure and data, and should be around how to use data and algorithms to make the most profit. Let us do the heavy lifting, so you can focus on building better algorithms.
Want to learn more? Check out our website, blankly.finance, or reach out to us by email (hello@blankly.finance) or our Discord.

Top comments (0)