One of the most important axioms in data science that I've come across in my extensive and thorough journey is the idea that 1 x 1 = 2. No, no wait...

Actually it's the idea that good features build good models. Without a solid understanding of the underlying structures and interactions within your data (or lack thereof) you cannot hope to create a meaningful interpretation of the information in question, and thus cannot manipulate or create meaningful features for your model. This is the driving force behind quality EDA exploratory data analysis.
Given the integral nature of EDA concerning the process of data science and effective modeling it is important that it be done well. The initial approach to most projects will generally start with the same methods (discerning ranges of features, looking for missing information, looking for how many different values a feature might contain etc.) and can be done almost entirely with pandas. So what problem is?
While pandas is fully capable it can be cumbersome. Repeating the same functions over and over, regardless of their simplicity, becomes more tedious and time consuming as your data becomes larger and more complex. Each action generally requires separate lines of code, potentially costing you seconds, even minutes of your time. Absolutely outrageous. With Pandas Profiling you can accomplish most of your rudimentary analysis with a single line:
df.profile_report()
This humble command will output a lovely report that tidily answers many of the fundamental questions you would typically have concerning a given data set, and can even be output in HTML format! 
Included in the report are:
-
Essentials: type, unique values, missing values
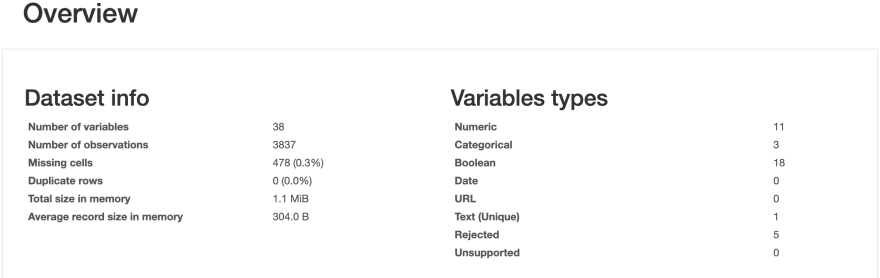
- Quantile statistics: minimum value, Q1, median, Q3, maximum, range, interquartile range
- Descriptive statistics: mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness
- Most frequent values
-
Histogram

-
Correlations: Spearman and Pearson matrixes
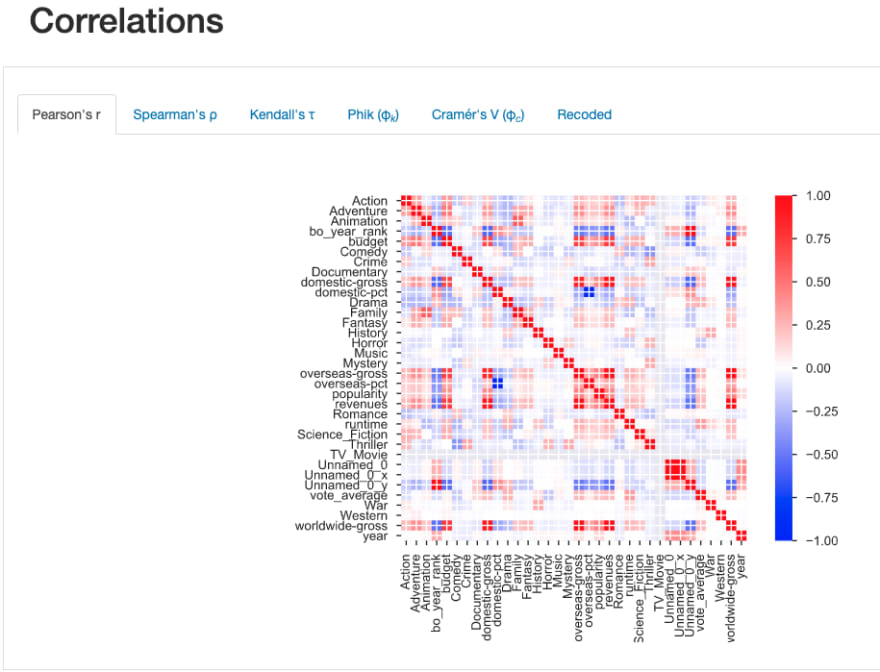
Another interesting feature is that the report will automatically detect and drop features that it interprets as being negligibly influential.

This may or may not be reliable or even desirable depending on the nature of your data, but potentially useful in helping to identify certain features that may more or less be redundant or contain no information.
Each of these features has a number of more advanced parameters that you can alter when you call pandas-profiling to generate the report, and within the report itself many features are interactive. For instance, in the above correlation matrix example you can see that various measures of correlation can be viewed in individual tabs.
For a more comprehensive look at the various parameters, as well as the source code behind the outputs found in the report, you can check out the GitHub for Pandas Profiling.
This is, in the end, merely a tool of convenience meant to help the user quickly and effectively assess data at a glance. It is in no way a replacement for further probing and analysis, but can be helpful in saving time and allowing for a faster, albeit somewhat shallow understanding of the nature of a data set.
Here is the full report sampled in this blog


Top comments (0)