Requirement analysis on archiving MySQL data
MySQL is commonly used in OLTP to provide external services with qualified hardware resources, the amount of data provided can often reach TB level. In many scenarios, the storage data has a relatively long TTL. However, data records may lose business significance after being online for a period (examples below).
- A certain service is deactivated
- The life cycle of data exceeds service requirements. For example, a service only requires data within nearly 3 months
- Archiving log data
- Merging databases and tables to provide statistical query and analysis services
- Regular backup, archiving, and audit services
- ......
Usually, archiving schemes are proposed by DBAs, and developers then analyze which data can be archived. The archiving process can be completed with the help of standardization and automated execution.
Common solutions for archiving MySQL data
Current archiving methods are generally divided into two categories: MySQL and MariaDB. The key tool is pt-archiver or obtaining archived data by parsing binlog.
Using MySQL for storage and archiving
This is the most common solution: the archiving, or even synchronous backup, of the online production repository is processed by a PC (usually with a large capacity -- about 50T, and large memory, to run instances). It's also possible to build a master/slave server configuration offline to archive PolarDB data and provide offline intranet queries.

Advantages
Based on the familiar MySQL environment, it's easy to manage
Highly compatible with the online environment
Archiving environments can be built with large, inexpensive disks
Disadvantages
- In this kind of architecture, binlog is usually turned off in in the archive nodes for cost reduction. There will be a backup in the object storage, and no slave database. Therefore, once the data or the hard disk is damaged, it will take a long time to recover
- There's not enough computing power, and not much ability to extend the computing node either. The data needs to be extracted and put into a big data environment when computing is required
- Large amount of idle CPU and RAM resources
Using MariaDB for archiving
S3 engine is an experimental feature introduced in MariaDB, it has a better compression capability while retaining the usage habits of MySQL users. The complete archiving process includes writing to InnoDB first, then alter table tb_ name engine=s3;
Advantages
- Maintaining MySQL compatibility
- Supporting S3 class object storage
- Supporting highly compressed storage
Disadvantages
S3 engine is write only
Append writing is not supported, so conversion to an InnoDB table is required
The conversion from InnoDB to S3 engine takes a very long time, adding complexity to the process
Archiving method provided by Databend
So, is there a more elegant solution? Here we recommend Databend, a cloud native data warehouse.
Introduction & Architecture

Databend is a modern, open-source data warehouse developed using Rust. It's completely cloud-oriented, provides extremely fast elastic expansion capabilities, and is committed to creating an on-demand and volume-based Data Cloud product experience.
Features are as follows:
- A star project among open-source, cloud-based data warehouses
- Vectorized execution, pull&push-based processor model
- Real storage/computing separation architecture, high performance, low cost, on-demand use
- Complete database support, compatible with MySQL, Clickhouse protocol, SQL over HTTP, etc.
- Complete transaction,
- Ensured transaction integrity, support time travel, database clone, data share and other functions
- Support multi-tenant read/write and sharing operations on the same data
Databend's design principles:
No Partition
No index(Auto Index)
Support Transaction
Data Time travel/Data Zero copy clone/Data Share
Enough Performance/Low Cost
Deployment
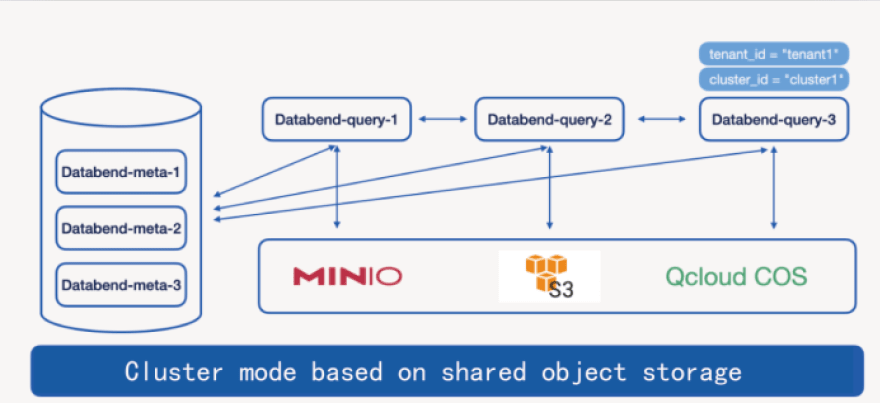
Three processing methods are supported,including MySQL, Clickhouse and SQL Over Http.
Please refer to https://databend.rs/doc/deploy for installation instructions.
For more support during installation or usage, please contact us via wechat (wechat number: 82565387).
Writing methods
Insert into
Insert writing operations using JDBC, python and golang are supported. Here is a recommended guidance: https://databend.rs/doc/develop.
It's suggested to use Bulk insert to achieve batch writing operations, which has similar usage with MySQL.
Streaming load
Please refer to https://databend.rs/doc/load-data/local to see more of streaming load.

It only takes about 3 minutes to load an 81G file with 200 million rows of data into Databend (As seen in the picture above).
Besides, Databend now supports reading directly from compressed files. For example:
ls ./dataset/*.csv.gz|xargs -P 8 -I{} curl -H "insert_sql:insert into ontime format CSV" -H "skip_header:1" -H "compression:gzip" -F "upload=@{}" -XPUT http://root:@localhost:8000/v1/streaming_load
It should be noted that the scheme for reading compressed files has not been optimized, it takes about 13 minutes to load the same data using this method. There is much room for performance improvement in the future.
Using Stage
Stage can be considered as an online storage manager of Databend, please refer to https://databend.rs/doc/load-data/stage for detailed syntax。

The above PPT page shows the process of creating Stage, uploading files, and viewing files online. Files in Stage can be loaded into Databend by "copy into" command.
Advantages of archiving MySQL data with Databend
We recommend to use Databend combined with object storage for MySQL data archiving.
The advantages are as follows:
- Object storage breaks the limit of storage capacity
- Databend has a relatively high data compression ratio of 10:1, which saves a lot of storage resource
- Databend manages data based on MySQL protocols, so users don't need to change their usage habits
- The storage/computing separated architecture makes it easier to scale up, when facing computing resources insufficiency, and there is no need to worry about the high availability of storage
- Most original MySQL tools can be reused
Databend now supports object storage: AWS S3, Azure, Alicloud, Tencent Cloud, QingCloud, Kingsoft Cloud and equipments like minio and ceph. Meanwhile the surprising computing ability of Databend supports data computation services if needed.
People can make better use of cloud resources and obtain qualified performance with a relatively low cost using Databend.
Please contact us via wechat (wechat number: 82565387) to get more information!
About Databend
Databend is an open-source modern data warehouse with elasticity and low cost. It can do real-time data analysis on object-based storage.
We look forward to your attention and hope to explore the cloud native data warehouse solution, and create a new generation of open-source data cloud together.
- Databend docs:https://databend.rs/
- Twitter:https://twitter.com/Datafuse_Labs
- Slack:https://datafusecloud.slack.com/
- WeChat:Databend
- GitHub :https://github.com/datafuselabs/databend

Top comments (0)