Motivation
Serverless is a way to deploy code, without having to manage the
infrastructure underneath it. In AWS terms this means there is an
compute instance that runs your code, except you don’t control it, and
that might be a good thing. It only exists when it’s asked for by
something else, and therefore you only pay for the work it does. If you
need to do work concurrently you get a new instance, which also goes
away as soon as you don’t need it, so it’s scaleable.
For a data scientist this is an interesting prospect for a number of
reasons. The first is keeping you hands clean. Not all people in this
role come from a ‘operations’ background. Many of us are analysts first,
and graduate into the role. However, that shouldn’t mean we don’t ‘own
our deployments’. However, it also means that we might not have the
background, time or inclination to really get into the nitty-gritty.
Managed infrastructure, that can scale seamlessly out of the box is a
nice middle ground. We can still manage our own deployments, but theres
less to worry about than owning your own EC2 instances, let alone a
fleet of them. The way that the instances themselves die off is also
valuable. We may be doing work that requires 24/7 processing, but often,
we aren’t. Why pay for a box which might have 50% required utilisation
time, or even less?
Limits
Just like in everything there is a balance. There are physical limits
to this process. I’ve had success deploying data science assets in this
architecture, but if you can’t fit your job in these limits, this
already isn’t for you. Sure, data science can be giant machine
learning models on huge hardware with massive data volumes, but we have
to be honest and acknowledge that it isn’t always. K.I.S.S. should apply
to everything.
If you can get good enough business results with a linear regression,
don’t put in 99% more effort to train the new neural network hotness to
get a 2% increase in performance. Simplicity in calculation, deployment,
and explainability matter.
“No ML is easier to manage than no ML” ©
[@julsimon](https://twitter.com/julsimon/status/1124383078313537536)
Getting started
from scipy import stats
import numpy as np
np.random.seed(12345678)
x = np.random.random(10)
y = 1.6*x + np.random.random(10)
slope, intercept, r_value, p_value, std_err =
stats.linregress(x, y)
This is a nonsense linear regression. IMHO it’s a data science ‘Hello
World’. Let’s make it an AWS Lambda serverless function.
+ import json
from scipy import stats
import numpy as np
+ def lambda_handler(event, context):
np.random.seed(12345678)
x = np.random.random(10)
y = 1.6*x + np.random.random(10)
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
+ return_body = {
+ "m": slope, "c": intercept,"r2": r_value ** 2,
+ "p": p_value, "se": std_err
+ }
+ return {"body": json.dumps(return_body)}
These changes achieve 3 things:
- Turning a script into a function
- Supplying the function arguments
eventandcontext - Formatting the return as json
These are required as AWS Lambda needs a function. This is so that its
event driven architecture can feed in data through event, and so
that it’s json formatted data can both be received by your function,
and then also the response be returned by that function into the rest of
the system.
You can then open up the AWS console in a browser, navigate to the
Lambda service, and then copy and paste this into this screen:
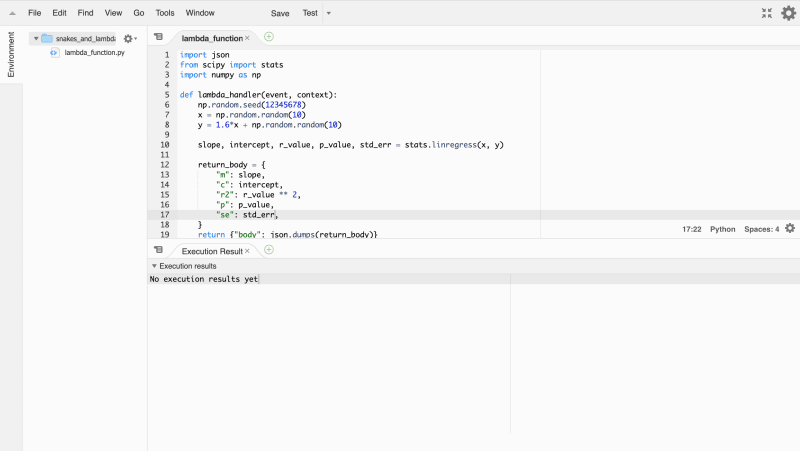
You can then hit run and…
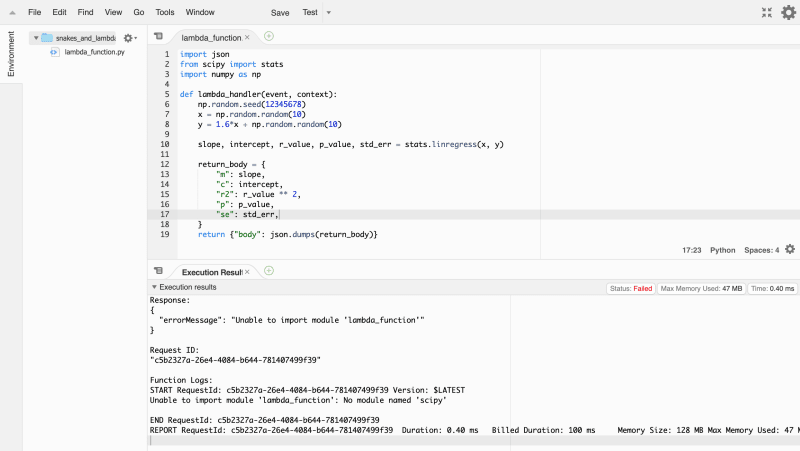
What happened? Well, because it’s a managed instance, the function
doesn’t know what scipy is. It’s not installed on the cloud, it was
installed on your machine…
Layers
AWS lambda doesn’t pip install ..... Seeing as these run on compute
instances that turn up when needed, and are destroyed when not needed,
with no attached storage, you need to find a way to tell AWS what your
dependencies are, or you’ll just have to write super-pure base Python!
Well, that may not be strictly true. json is built in by default to
every instance, so is boto3, but what about our data science buddies?
numpy, scipy are published by
aws as layers. Layers are bundles of code, that contain the dependencies you need to run the functions you write.
So in this case we can open the ‘layers’ view in AWS and attach these to our function.
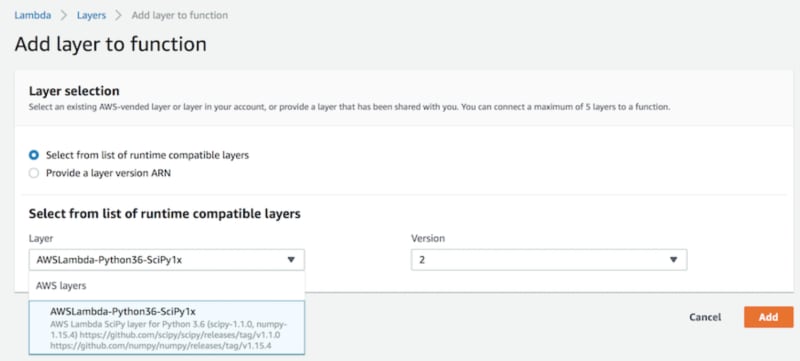
Now that you’ve attached all your dependencies with layers, go ahead and
run your function again.
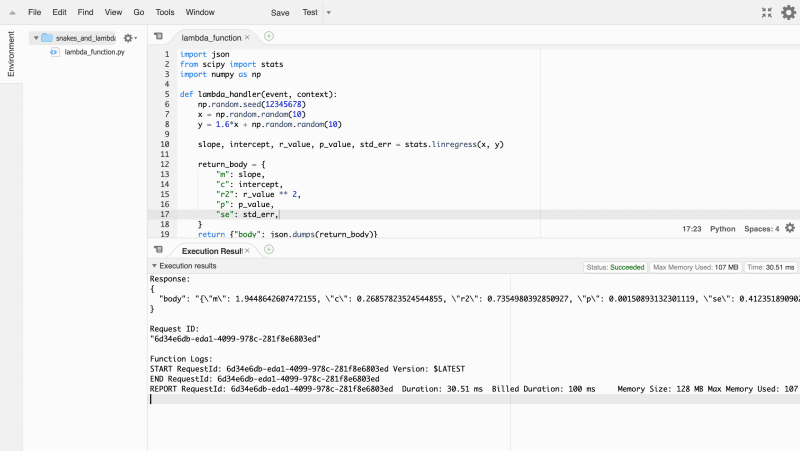
Success! So now you know the basics of how to put some Python data
science into practice on AWS Lambda.
This is a companion post to my talk on using data science in AWS lambda.
If you’re keen to know more, and can’t wait for me to write it all up
here. You can get the gist of the whole talks from this repo 😄
 DaveParr
/
snakes_and_lambdas
DaveParr
/
snakes_and_lambdas
Talk for pydata on python datascience lambdas
Snakes and Lambdas
A presentation on using aws lambda for data science tasks.
Foundation
- understand aws ecosystem from a base 'cloud concepts' POV
- some python experience
- data science concepts: linear regression, time series analysis, anomaly detection
Solves
- productionising python data science
- micro-service for data science
- local code -> cloud deployment workflow
Requires
- to generate the slides, use
revelation
Delivered at
Contributions
I wrote and compiled all the material and the experience that drove it, however I have also been able to use a vast wealth of other peoples resources they have shared on the topic. These are clearly linked and I encourage you to go and dive deeper into those resources. Without those resources I would not have been able to implement any of the material described here.

Top comments (3)
This is so useful! Thank you for sharing it. How does AWS compare with Google in terms of costs and ease of use? I tried using Google a while back and found it too complicated, and also had trouble with being charged for something I wasn’t using. It’s put me off exploring paying for cloud computing. I’m just using Google Colab (GPU) now which is easy and free but is restrictive (e.g after 12 hours of using it I am blocked from using it again for 24 hours)
I actually haven't used much g cloud tbh, though lots of people really rate it :) a real draw back of Aws compared to Azure is clarity of how it plugs together. This is really only a surface level intro. Other articles will move into plugging it into API gateway, Sam for cloud formation, maybe even logging and ci/cd.
Cost on lambda I found to be very generous in the free tier. Most hobby projects won't break out of that, but also tbf you will incur very small costs for using API gateway to handle request/response, and s3 to store custom layers (which will be future articles).
I would estimate the end to end costs to be acceptable even for low traffic personal projects. For less than something like 200,000 requests you can have systems running at less than a few pounds.
Thanks Dave 👍🏽