Improving reliability
Shifting away from impacts on reliability, it's time to move to thinking about how to improve reliability.
There are lots of options for improvement and prioritising them requires some thought. I'll share the options in a moment but the Google SRE team share this calculation for measuring the impact on your error budget.

TTD
Time to Detect - The time between the user being impacted and someone in your team being informed.
TTR
Time to resolution - The time between being informed and a fix being presented.
impact%
Impact percentage - how many users will this particular failure impact.
TTF
Time to failure (sometimes called TBF time between failures) is how frequently you expect something to happen.
All together...
The expected impact of a particular type of failure on your error budget is proportional to the time-to-detect plus the time-to-resolution multiplied by the percentage of impact over the time-to-failure. This last value TTF expresses how frequently you expect this particular failure to occur.
To improve reliability
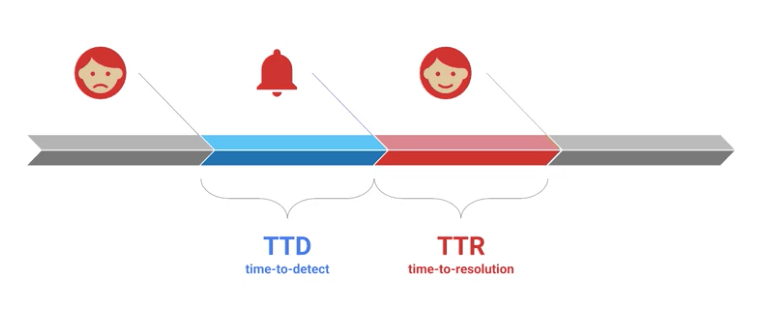
So to improve reliability you could focus on reducing the TTR. Maybe setting up quicker alerting or more frequent monitoring checks.
Or even introduce automated alerting in an environment that previously relied upon humans spotting things on graphical dashboards.
Maybe spotting Single Points of Failure (SPOF's) in your architecture and then replicating those is another option to lower the impact% or maybe doing canary releases with dedicated groups of users thus lowering the impact%
The key point

Having this calculation means we can start to prioritise which areas of the SLO impact we focus on.

Top comments (0)