For this demo, I'm using the Eurovision songs available at Kaggle, which contain lyrics in their original language, and translated into English
Sample data
I downloaded and uncompressed the files:
wget -c -O eurovision-song-lyrics.zip eurovision-song-lyrics.zip https://www.kaggle.com/api/v1/datasets/download/minitree/eurovision-song-lyrics
unzip -o eurovision-song-lyrics.zip
rm -f eurovision-song-lyrics.zip
MongoDB Atlas and Shell
I install MongoDB Atlas CLI and start a local instance:
curl https://fastdl.mongodb.org/mongocli/mongodb-atlas-cli_1.41.1_linux_arm64.tar.gz |
tar -xzvf - &&
alias atlas=$PWD/mongodb-atlas-cli_1.41.1_linux_arm64/bin/atlas
atlas deployments setup atlas --type local --port 27017 --force
This runs MongoDB Atlas in a Docker container:
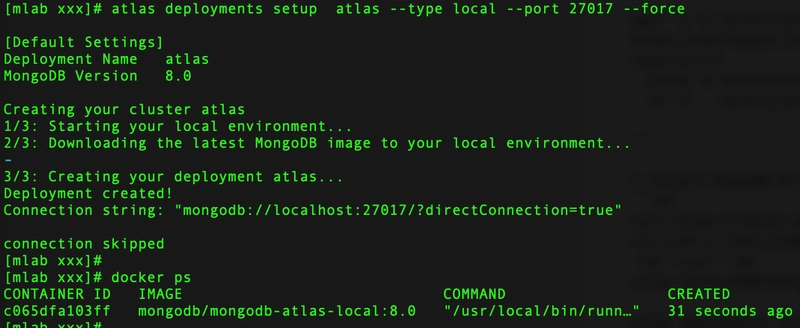
I also installed MongoDB Shell to connect and run JavaScript and Node.js:
curl https://downloads.mongodb.com/compass/mongosh-2.4.2-linux-arm64.tgz |
tar -xzvf - &&
alias mongosh=$PWD/mongosh-2.4.2-linux-arm64/bin/mongosh
Ollama Large Language Model
I need a local LLM model to generate embeddings from lyrics. To avoid relying on external services, I will use Ollama with the nomic-embed-text model, which I install locally:
curl -fsSL https://ollama.com/install.sh | sh
ollama pull nomic-embed-text
npm install ollama
mongosh
I've installed the Ollama module for node.js and started MongoDB Shell.
Load data into MongoDB
I load the files into an eurovision collection:
const fs = require('fs/promises');
async function loadJsonToMongoDB() {
const fileContent = await fs.readFile('eurovision-lyrics-2023.json', 'utf8');
const jsonData = JSON.parse(fileContent);
const documents = Object.values(jsonData);
const result = await db.eurovision.insertMany(documents);
}
db.eurovision.drop();
loadJsonToMongoDB();
db.eurovision.countDocuments();
Generate embeddings
I update the MongoDB collection to add embeddings, generated from the lyrics, and generating embeddings with Ollama:
const ollama = require("ollama"); // Ollama Node.js client
// Calculate embeddings
async function calculateEmbeddings(collection) {
try {
// Process each document and update the embedding
const cursor = collection.find();
let counter = 0;
for await (const doc of cursor) {
// Call the embedding API
const data = {
model: 'nomic-embed-text',
prompt: doc["Lyrics translation"]
};
const { embedding } = await ollama.default.embeddings(data);
// Update the document with the new embedding
await collection.updateOne(
{ _id: doc._id },
{ $set: { embedding: embedding } }
);
counter++;
console.log(`Added embeddings for ${doc.Year} ${doc.Country}`);
}
} catch (error) {
console.error('Error:', error);
}
}
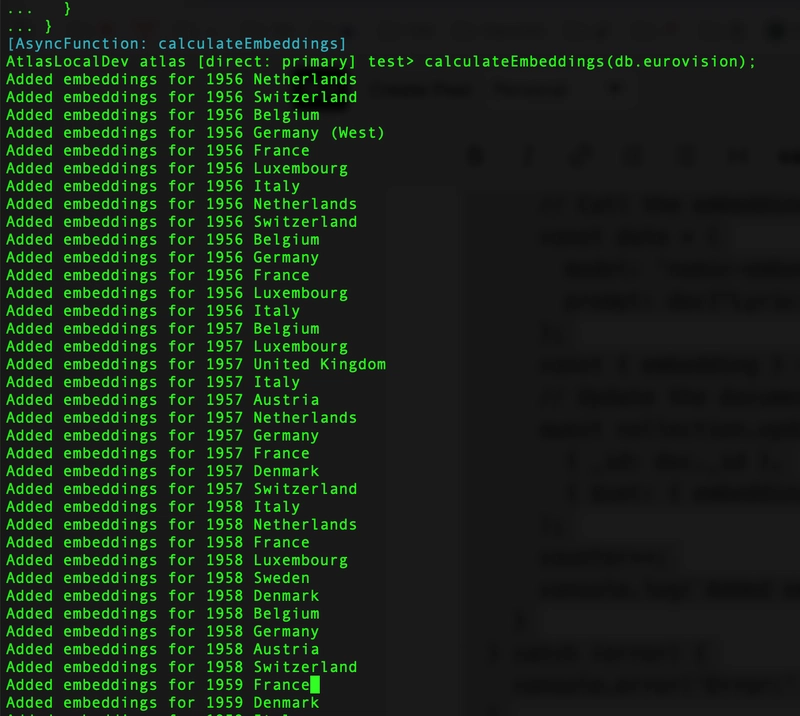
calculateEmbeddings(db.eurovision);
This takes some time:
MongoDB Vector Search Index
I create a vector search index (Ollama nomic-embed-text, like BERT, has 768 dimensions):
db.eurovision.createSearchIndex(
"vectorSearchOnLyrics",
"vectorSearch",
{
fields: [
{
type: "vector",
numDimensions: 768,
path: "embedding",
similarity: "cosine"
}
]
}
)
db.eurovision.getSearchIndexes()
Don't forget the name of the index, it will be used to query, and a wrong index name simply results on no results.
Aggregation pipeline with vector search
Here is the function I'll use to query with a prompt, converting the prompt to vector embedding with the same model:
const ollama = require("ollama"); // Ollama Node.js client
async function vectorSearch(collection, prompt) {
try {
// Get the embedding for the prompt
const data = {
model: 'nomic-embed-text',
prompt: prompt,
};
const { embedding } = await ollama.default.embeddings(data);
// Perform a vector search in aggregation pipeline
const results=collection.aggregate([
{
"$vectorSearch": {
"index": "vectorSearchOnLyrics",
"path": "embedding",
"queryVector": embedding,
"numCandidates": 10,
"limit": 5
}
},{
"$project": {
"Year": 1,
"Country": 1,
"Artist": 1,
"Song": 1,
"Language": 1,
"score": { "$meta": "vectorSearchScore" }
}
}
]);
// Display the result
results.forEach(doc => {
console.log(`${doc.score.toFixed(2)} ${doc.Year} ${doc.Country} ${doc.Artist} ${doc.Song} (${doc.Language})`);
});
} catch (error) {
console.error('Error during vector search:', error);
}
}
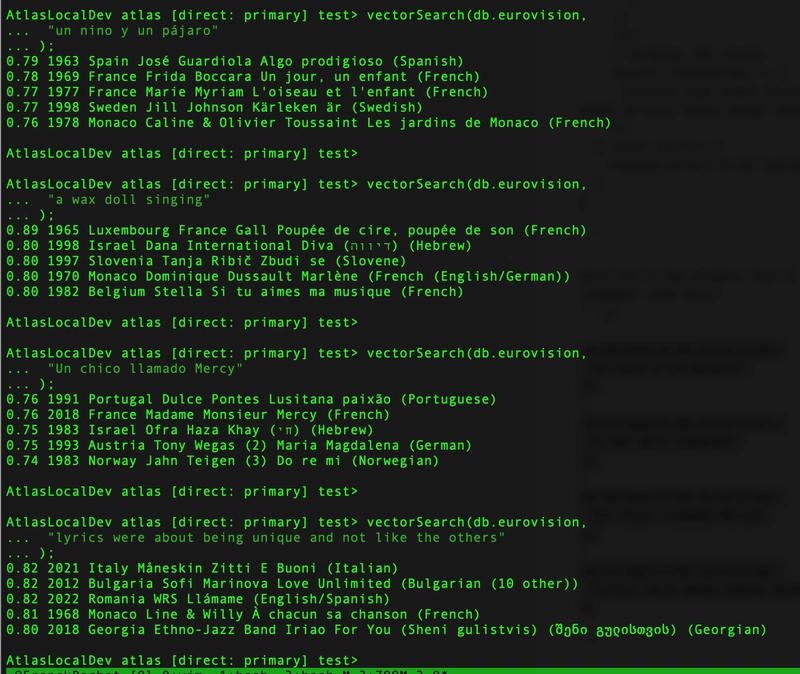
Here are a few prompts that I tried to find the songs for which I remember some bits, using different languages:
vectorSearch(db.eurovision,
"un nino y un pájaro"
);
vectorSearch(db.eurovision,
"a wax doll singing"
);
vectorSearch(db.eurovision,
"Un chico llamado Mercy"
);
vectorSearch(db.eurovision,
"lyrics were about being unique and not like the others"
);
Here are my results, the songs I had in mind appeared in the forst or second position:
Conclusion
This article discusses implementing vector search in a local MongoDB Atlas setup using Ollama and the Eurovision song lyrics dataset. We populated the database with vectorized data embedded in the documents and created a vector search index for retrieving songs based on semantic similarity.
Storing embeddings with data, rather than in a separate database, is advantageous because embeddings are generated from document fields and can be indexed like any other fields. MongoDB stores arrays natively with the document model. The next step will involve generating embeddings without moving data out of the database, by integrating Voyager AI into MongoDB.

Top comments (0)