In this post we’ll see how to create an "intelligent search service" using Micronaut, Milvus and OpenAI.
- WARNING
-
I’ll show only most important part of the code to have an idea about the full picture
Idea
Say we want to create a service to search across a bunch of product descriptions using a user input.
ProductId
|
ProductDescription
|
|
1
|
This is long text with several info for product 1
|
|
2
|
This is long text with several info for product 2
|
|
…
| |
|
n
|
This is long text with several info for product n
|
Traditionally we will use some kind of `LIKE %str%' approach, so we’ll try to find descriptions containing the input text. But we want to improve our service with a little intelligence and search using vector search where information is represented as vectors instead to plain text so queries can retrieve "closed" documents instead "matched" documents.
For this example, we’ll use Milvus (https://milvus.io/) as a "similarity" database. Another alternatives can be Meilisearch or Postgresql with pg_vector plugin installed, for example
Architecture
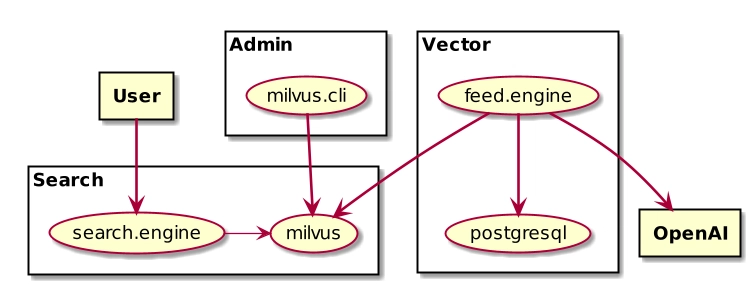
Requirements
PostgreSQL (or another source where "documents" are stored). For our example documents will be stock descriptions
Milvus
OpenAI account (we’ll use free tier of OpenAI to vectorized documents)
Collection
We need to create the collection in Milvus. For this purpose we’ll create a Micronaut command line (cli) application and add the milvus dependency
gradle.build
dependencies{
...
implementation 'io.milvus:milvus-sdk-java:2.2.5'
}
And we’ll create a PicoCli Command java class. We can implement also others commands as delete-collection, create-user, …
`
MilvusClient connect(){
return new MilvusServiceClient(
ConnectParam.newBuilder()
.withUri(url)
.withAuthorization(user, password)
.build()
);
}
void createCollection() throws Exception {
final var milvusClient = connect();
final var collection = positional.get(1);
final var createCollection = CreateCollectionParam.newBuilder()
.withCollectionName(collection)
.addFieldType(FieldType.newBuilder().withName("id")
.withDataType(DataType.Int64).withPrimaryKey(true).withAutoID(true).build())
.addFieldType(FieldType.newBuilder().withName("instrument_id")
.withDataType(DataType.VarChar).withMaxLength(36).build())
.addFieldType(FieldType.newBuilder().withName("stock_instrument")
.withDataType(DataType.VarChar).withMaxLength(20000).build())
.addFieldType(FieldType.newBuilder().withName("embedding")
.withDataType(DataType.FloatVector).withDimension(1536).build())
.build();
final var response = milvusClient.createCollection(createCollection);
if( response.getStatus().intValue() != R.success().getStatus() )
throw response.getException();
final var createIndex = CreateIndexParam.newBuilder()
.withCollectionName(collection)
.withFieldName("embedding")
.withIndexType(IndexType.IVF_FLAT)
.withMetricType(MetricType.L2)
.withExtraParam("{\"nlist\": 1024}")
.build();
final var index = milvusClient.createIndex(createIndex);
if( index.getStatus().intValue() != R.success().getStatus() )
throw response.getException();
}
`
Basically we’re creating a Milvus collection with 4 fields, and auto generated Id, our stock Id, the full description of the stock (for future reference) and an embedding vector to represent the description
Once we build the jar we can run something similar to
java -jar milvus-cli.jar --url milvus-instance --user user --password password create-schema
Documents
We can use also the previous command line java to feed the collection but as we want to update every day we’ll create a service and use a daily scheduler to do it.
Stock description will be extracted from our PostgreSQL but in your case can be text files, Excel, World, etc
@JdbcRepository(dialect = Dialect.POSTGRES)
public interface StocksRepository extends GenericRepository<StockInstrumentEntity, UUID> {
Flux<StockInstrumentEntity>findAll();
OpenAI
- INFO
-
This service will require an authorization token
We will use public OpenAPI endpoint to send descriptions and retrieve associated vectors.
`
@Serdeable
public record EmbeddingsModel(List input, String model) {
}
@Client("https://api.openai.com")
public interface OpenaiClient {
@post("/v1/embeddings")
EmbeddingsResponse embeddings(
@body EmbeddingsModel model,
@Header(HttpHeaders.AUTHORIZATION)String auth);
}
@Serdeable
public record EmbeddingData(String object, List embedding, int index) {
}
`
EmbeddingsModel is a POJO to send a list of Strings to be vectorized using a model, "text-embedding-ada-002"in this case, and receive a list of EmbeddingData where every input was converted to a List<Float> (the vector)
Feed Milvus
Basically we have a Micronaut service retrieving StockInstrumentEntities from the database, sending the description to OpenAI and receiving a List<Float> per each document. Now is time to store all information into the collection:
`
List fields = new ArrayList<>();
fields.add(new InsertParam.Field("instrument_id", ids));
fields.add(new InsertParam.Field("stock_instrument", stocks));
fields.add(new InsertParam.Field("embedding", vectors));
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName(configuration.getCollection())
.withFields(fields)
.build();
var resp = milvusClient.insert(insertParam);
`
As you can see Milvus allows feed collections using a batch of objects. In our example we’re sending a bunch of 100 Ids+Descriptions+Vectors
Intelligent Search
To run the search we need vectorized the user input as we did with the description of the stocks, using the OpenAI endpoint. Once we have the associated vector we can use Milvus to run a search:
`
LoadCollectionParam.newBuilder().withCollectionName(collection).build());
if( load.getStatus().intValue() != R.success().getStatus() )
throw load.getException();
List query_output_fields = List.of("id","instrument_id", stock_instrument");
QueryParam queryParam = QueryParam.newBuilder()
.withCollectionName(collection)
.withConsistencyLevel(ConsistencyLevelEnum.STRONG)
.withExpr(search)
.withOutFields(query_output_fields)
.withOffset(0L)
.withLimit(100L)
.build();
R respQuery = milvusClient.query(queryParam);
QueryResultsWrapper wrapperQuery = new QueryResultsWrapper(respQuery.getData());
var ids = wrapperQuery.getFieldWrapper("instrument_id").getFieldData();
var stocks = wrapperQuery.getFieldWrapper("stock_instrument").getFieldData();
for(var i=0; i< ids.size(); i++){
System.out.println(Map.of("id",ids.get(i),"stock",stocks.get(i)));
}
`
Using the search vector Milvus will run a query and find these related documents using the distances of the vectors.
- INFO
-
As you can see, we’re retrieving our custom Id (
instrument_id) so we can use it and retrieve from our Postgresql database more information
Some search examples:
"companies selling cars"
"women care"
Conclusion
As you can see it’s very easy to integrate new similarity databases, as Milvus in this case, to improve the user search experience

Top comments (0)