
One of the many aspects that a data scientists must deal with on a day to day basis is addressing statistical bias within the models and datasets they use. Another aspect of the work that is less often mentioned is addressing societal bias on statistical and machine learning predictions. Mitchell et al's article: "Prediction-Based Decisions and Fairness: A Catalogue of Choices, Assumptions, and Definitions" attempts to offer a concise reference for thinking through the choices, assumptions and fairness considerations of predictions-based decision systems.
As the use of prediction based and decision making machine learning models continues to grow and interweave itself into the societal fabrics of one's day to day life. It has become all the more important to investigate and know if any bias are found due to statistical or societal bias. Mitchell et al uses the two real world examples of pretrial risk assessment and lending models to summarize the definitions and results that have been formalized to date.
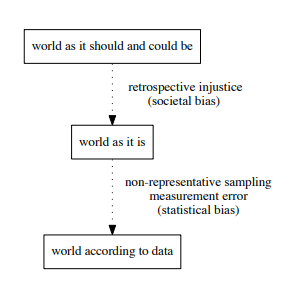
Th article highlights three examples of societal bias within predictive modelling. The first is the data: Even if the data were to be representative and accurate, they could perpetuate social inequalities that run counter to the decision maker's goals. In the case of pretrial risk assessments, using arrests as a measure of crim can introduce statistical bias from measurement error that is differential by race because of a racist policing system.
This bias is compounded because statistical and machine learning models are designed to identify patterns in the data used to train them and to an extent reproduce unfair patterns. This also takes place in the parameters that a data analyst uses in the models such as choosing the class of a model, which metrics to focus on for interpretability, and which covariates to include in the model.
Lastly, a final choice in mathematical formulations of fairness is the axes along which fairness is measured. In most cases, deciding how attributes map individuals to these groups is important and highly context specific. In regulated domains such as employment, credit, and housing, these so-called “protected characteristics” are specified in the relevant discrimination laws. Even in the absence of formal regulation, though, certain attributes might be viewed as sensitive, given specific histories of oppression, the task at hand, and the context of a model’s use.
As a junior data scientist, this paper can be informative both in the job application process and in understanding the company's work culture. One can elevate themselves as a more ideal candidate by acknowledging the implicit societal bias in the data / model that they will work with during their interview. Even if one doesn't fully comprehend or know all the factors at play, a recruiter will appreciate a new approach or that you, as a candidate, have domain knowledge about the industry. Knowing how a company addresses societal bias could also be a helpful indicator to a job applicant on the type of work culture at the company they are interested in applying to.
As the two main examples listed in the article show: there are many important and real life applications were the policy and decisions made could have adverse effects to a certain demographic, but not others. As American society is becoming more cognizant about the societal inequalities endemic in its systems and structures, it is becoming more important to also be aware of the bias in machine learning models that play a decision or prediction roles.
Citation
Prediction-Based Decisions and Fairness: A Catalogue of Choices, Assumptions, and Definitions
Shira Mitchell, Eric Potash, Solon Barocas, Alexander D'Amour, Kristian Lum

Top comments (0)