
This post was first published on CoderHood as The 5 Problem-Solving Skills of Great Software Developers. CoderHood is a blog dedicated to the human dimension of software engineering.

To be effective, software engineers must hone their problem-solving skills and master a complex craft that requires years of study and practice. Despite what newcomers might think, understanding a programming language, a framework or even algorithms is not the hard part of building software.
For example, languages are easy, especially the C-inspired imperative ones. There are only 32 keywords in the C language, and their meaning is easy to master:
| auto | double | int |
| break | else | long |
| case | enum | register |
| char | extern | return |
| const | float | short |
| continue | for | signed |
| default | goto | sizeof |
| do | if | static |
C also has 14 pre-processor directives, which are also not difficult to understand:
| #define | #error | #import |
| #elif | #if | #include |
| #else | #ifdef | #line |
| #ifndef | #pragma |
Stringing many instructions together to accomplish something useful is far more complicated. The concept is similar to writing in human languages like English. Each word in English is easy to understand, but putting many words together to compose well formed and clear sentences and paragraphs is far from easy. It requires studying other people's work and a lot of practice.
Building software is more about solving problems than writing code or understanding technologies. Becoming good at solving problems requires a lot of practice and experience. A software engineer is a problem solver first, and a coder second. Computer languages, frameworks, and algorithms are tools that you can learn by studying. Solving problems, however, is complicated and hard to learn other than through long practice and applied mentorship.
How To Think Like a Software Engineer

Through practice, software engineers learn to think in ways that allow them to find efficient solutions to problems. Learning happens naturally with training, but it takes time. You can accelerate your learning progression by identifying and honing the problem-solving skills that you need to think like an already experienced software engineer.
I am going to use a non-technical problem to explain the five skills you must learn. The problem is: How do you make coffee for four people with different coffee preferences?
Making Coffee
Four people --- A, B, C, and D --- want coffee, and they have specific requirements.
- A. Black.
- B. Cream only.
- C. Sugar and cream.
- D. Sugar only.
You want to figure out a method, or algorithm, to get the coffee done quickly and as specified. The goal is to find a way to do it so that you can serve the coffee to the four people at the same time, and as hot as possible.
Five Problem-Solving Skills
1 -- Learn to split large complex goals into small, simpler ones.

Making coffee for four people as specified is the overall goal in this example. However, you can't just "make coffee" as if it was one single action. As anybody who knows how to make coffee could tell you, you need to divide the work into separate smaller tasks. Each of them needs to be simple enough to be easy to tackle at once.
Here is a list of tasks that needs to be done to make the coffee as specified by the main goal:
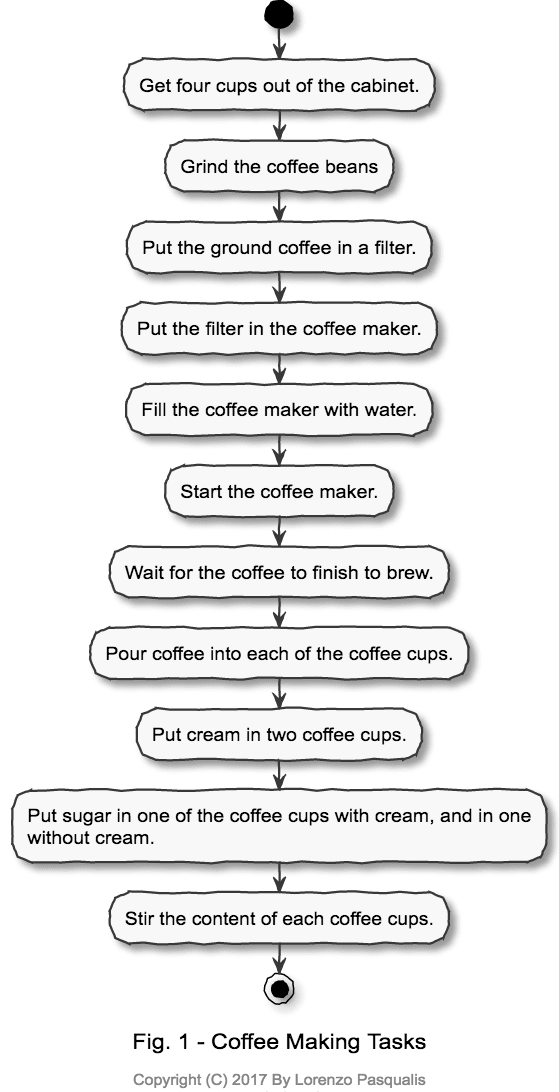
The ability to split work into tasks is natural to humans, and a required skill to get most things done. Making the above list doesn't require any particular study or practice other than knowing how to make coffee. In other words, more or less anyone can do it.
However, the difference between a practical everyday problem like making coffee and a more complex challenge like software building is that the steps to build software are rarely heavily rehearsed. To be able to list what tasks are necessary to build a particular piece of software requires having done it many times before. That is not very common in software building. That's why experienced software engineers don't jump immediately to writing a task list. Instead, they split the overall problem into more straightforward ones.
Engineers refer to the problems to resolve as the "what," and as the tasks to accomplish as the "how." In the coffee making example, the list of subgoals (the what) could be crafted as follows.
Subgoals:
- We have cups ready to be filled.
- We have enough ground coffee.
- The coffee maker is full of water.
- We have a filter filled with ground coffee. This subgoal requires subgoal #2 to be completed.
- The filter full of coffee is inside the coffee maker. This subgoal requires #4 to be completed.
- The coffee maker is brewing the coffee; requires #3 and #5 to be done.
- The coffee maker is done brewing; requires #6 to be done, and enough time to have passed.
- We have cups filled with coffee; requires #7 and #1 to be done.
- The cream was added to two of the cups; requires #1 to be completed.
- Sugar was added to one of the cups with the cream, and one of the cups without cream; requires #1 and #9 to be completed.
- The content of each cup is stirred and well mixed; requires #8, #9 and #10 to be completed.
Note how these are not descriptions of tasks or actions. They are descriptions of results that need to be obtained and their dependencies.
A graphical representation can be crafted to visualize the list above. Boxes represent subgoals, and incoming arrows into each box represent requirements to be satisfied for the subgoal to be achievable:

In the case of coffee making it is tempting to just write a list of tasks. That works only for simple problems that you know how to resolve without much planning. However, in software building that is rarely the case.
Planning subgoals allows us to abstract results from actions, and that is a critical difference. For example, subgoal #4, "we have a filter filled with ground coffee," might require going to the store to buy the filter. What matters in a subgoal is the result that needs to be achieved. The "what" is the important abstraction, while the "how" is a tactical choice that depends on the context (i.e., do you have filters or do you need to buy them?)
2 -- Learn to think parallel.

The subgoals presented above could be done one at the time, sequentially, in the order listed. However, that would not be optimal. The dependencies give us a clue on how what needs to be done in a specific order and what doesn't.
For example, you can start grinding the coffee beans first, and while the electric grinder is doing its job, you can fill the coffee maker with water. That's because filling the coffee maker with water doesn't require having the ground coffee ready. Also, grinding the coffee beans only requires to start the grinder, the rest of the time we'd be waiting for the grinder to finish. If the grinder were manual and kept you busy, that'd be a different story.
Moreover, while you are waiting for the coffee maker to brew, you can get the cups out of the cabinet. In fact, nothing depends on the cups to be ready until we need to start pouring ingredients into them.
You can also pour the cream and the sugar in the empty cups, even before the coffee is done. Doing that has the effect of making stirring unnecessary; if you pour lots of hot coffee in cups already containing a little cream and sugar, the coffee ingredients mix naturally eliminating the need to stir. On the other hand, if you pour a little sugar or cream in a cup full of coffee, you need to stir to obtain a homogeneous mix.
Reordering Tasks
Reordering the tasks with the intent of maximizing parallel execution saves time and eliminates one of the steps. The final list of tasks, in the optimal order, is:
- Fill the electric grinder with coffee beans, and start it.
- While the grinder is doing its job, fill the coffee maker with water.
- When the grinder is done, put the ground coffee in the filter.
- Put the filter in the coffee maker.
- Start the coffee maker.
- While the coffee is brewing, get four cups out of the cabinet.
- Put cream in two coffee cups.
- Put sugar in one coffee cup without cream and in one with cream.
- Wait for the coffee to finish to brew.
- Pour coffee into each of the coffee cups.
Or, represented as a sequence diagram (click on it to expand):
[
Note how the ordering of tasks doesn't affect the list of subgoals. It depends on it, and it's guided by it, but it doesn't change it. Tasks that are not dependent can be re-ordered in whatever way; that allows to maximize parallelism of execution.
Additionally, thinking about the subgoals first can be done without having to decide how to accomplish any of them. That further splits the overall problem into smaller ones that can be tackled in isolation.
3 -- Learn to abstract, but don't over-abstract.

The goal of making coffee as specified is narrow and prescriptive. If the problem changes and you now have five people instead of 4, and somebody wants vanilla syrup in their coffee, and one person wants decaf, the list of subgoals and tasks would have to be re-designed.
Programmers learn to design solutions so that they don't have to be re-designed every time that some of the parameters change. They learn to abstract problems in ways that allow a solution to resolve any class of problems similar to the original one.
Abstracting Coffee Making
In the coffee example, you might want to abstract the subgoals to account for any number N of people, instead of a fixed 4. You might also want to introduce an abstraction for things like cream and sugar. You might call it "extras." The list could change over time to include syrup, nutmeg, foam, eggnog, vodka or whatever people like to put in their coffee. Such abstraction could allow for any number X of extras that can be added in whatever amount in each of the cups.
Another abstraction could be the type of coffee. Caffeinated and decaf are two obvious ones, but there could be more, like a bold roast, medium roast, light roast, Colombian, breakfast blend, etc.
Since the coffee maker can only brew a type of coffee at the time, you can see how this complicates things substantially. If some of the four people in the original problem asked for caffeinated and others asked for decaf, the requirement of serving the coffee to all of them at the same time and as hot as possible would get complicated to pull off. At that point, you need to abstract away the concept of how many coffee makers you have --- up to Y if you have Y coffee varieties. Also, the parallelism of the operations, if you have Y coffee makers independently running, can become tricky. At that point, a developer might want to consider abstracting the number of baristas. If you have K baristas working together, how does the whole thing change?
Abstracting Some More
At that point, you might realize that coffee is just another ingredient of a beverage, so why make it unique? You could decide that coffee is one of the extras, and eliminate the whole specialized idea of coffee. However, coffee requires special handling and preparation, so maybe all extras should allow for generic special handling and preparation. For example, if eggnog is one of the extras, there could be a whole flow to describe the making of eggnog. But, at that point, you could abstract preparation of anything, and eggnog would merely be another product that you can create.
Over-Engineering
Does your head hurt yet? Welcome inside the twisted world of over-engineering. Do you see how quickly abstractions complicate the picture if you push them too far? We started from one type of coffee, four people to be served, a fixed configuration of extras and one barista. That was easy and natural. If you try to abstract every aspect of making coffee and if you are contemplating the possibility of having N people to serve, X types of extras, Y coffee varieties, K baristas... now that gets complicated, especially if you want to optimize cost and speed of the operation. You quickly go from making coffee to making any product under the sun using any process possible. Ouch.
An idealistic software engineer will try to abstract everything and will end up with a complicated machinery that is most likely planned to be used only to make coffee for a family of four people. An experienced software engineer, however, will abstract things to be able to resolve essential use cases and might consider other possible abstractions, but only to make sure that present decisions don't block future needs.
Balance
When do you stop abstracting? That is an art that experience refines. The rule of thumb is that you should abstract only use cases that you think will be required shortly, and try not to block future abstractions with narrow decisions.
4 -- Learn to Consider Re-Using Existing Solutions

No need to re-invent the wheel.
Not everything has to be re-invented from scratch. Experienced developers always consider using tools that are already available before they start designing a solution from scratch.
For example, instead of making coffee, can you go out and buy it from Starbucks and bring it to your four friends? If you don't have cups, coffee, and a coffee maker, going to Starbucks is a far cheaper and faster solution, especially if you don't plan to make coffee every day for a long time.
Finding and re-using solutions that are ready to go is part of the problem-solving skills a developer needs to acquire.
5 -- Learn to Think in Terms of Data Flows.

After years of practice, experienced developers start thinking of software, and problem-solving in terms of data flows through a system. In the coffee making problem, think of it as a flow of water, coffee, cups and extras from their sources all the way to the destination.
Water starts from the faucet; coffee comes from a bag that you have in your pantry --- the grocery store before that --- cups from your cupboard and the extras come from different sources depending what they are.
These materials (data) flow through a series of steps that manipulate, transform and mix. The initial state is the raw resources located wherever they are stored, and the final state is a series of cups filled with coffee plus extras. The destination is somebody's mouth.
Thinking in terms of data flows allow to visualize the primary goal and its subgoals as a series of boxes and arrows. The boxes represent each action that affects the materials flowing in the system, and the arrows are like pipes where the materials flow through.





Top comments (51)
Just awesome!
I agree with that that those 5 skill are necessary for software developers. You took very nice real life scenario which is very descriptive and easy to understand.
I think that your article should be a compulsory reading in high school in terms of first two skills. I could help students to understand why is so important to learn about flowchart, understand and play with it.
In my opinion last three skills (especially 4th) should be a mantra for more experienced developers. They often forget about reusing existing solutions and are reinventing wheel again.
I take off my hat to you! Great job. I'm sure that I'll use your article in the future.
Thank you, Rafal! Your comment made my day!
Great article! I am sharing it with the code school students I work with, I think it will be helpful to them.
I wrote an article approaching the issue of software problem-solving from a different angle--I think yours is much more detailed when it comes to breaking down large, complex problems.
Excellent, thank you! Let me know if it was helpful, and if you have any suggestions/feedback from the students.
I'd like to translate the article dev.to/lpasqualis/the-5-problem-so... into Japanese and publish on our tech blog techracho.bpsinc.jp/ if you're OK.
I make sure to indicate the link to original, title, author name in the case.
Best regards,
Thank you for your interest in translating this article into Japanese for cross-posting.
My requirements for cross-posting are highlighted here: CoderHood Cross Posting Policy
I am ok with you cross-posting on techracho.bpsinc.jp as long as all the requirements indicated in my policy are met.
Please let me know.
Thank you.
Thank you for the reply!
I'll look into your Cross Posting Policy.
I didn't think making coffee would be so complicated. I hope you can explain more of what you mean by the right times to abstract. Sometimes, I have a tendency to abstract things, and it sometimes don't fit with my new problem..
Ana, thank you for your note. I am writing an article about models and abstractions right now. Stay tuned!!!
Thank you! I'm looking forward to reading it. :)
I just published it :) Hope you like it, and looking forward your feedback.
First: Great Article!
Second: Could we please, please tattoo #4 on every programmer?
Seriously, we've gone through an explosion of programming art in the past 50 years. However, how much work do we waste writing and re-writing the same things over again?
I've noticed other engineering disciplines take a much stronger approach to understanding prior art and the state of the art when solving problems.
Indeed. The temptation is for people to re-do the work. The focus should be on doing work that is at the core of the business. The vast majority of problems that developers solve AROUND the core business have been resolved before, and time should not be wasted on those.
Super post! I've been a pro front-end developer for almost three years and around 18 months in I started to realise that my job is to solve problems, not necessarily to write code. It's a fantastic way to look at things and helps tremendously with abstraction.
I can sometimes be guilty of over abstraction so it's reassuring to read that it's ok to just minimise the abstraction to satisfy likely outcomes.
Amazed to see that "extreme reading and comprehending ability" is not mentioned at all, which I suppose should be the top most skill for a software developer/programmar/coder.
youtube.com/channel/UCQk0GDiOtiwPo...
The article is about problem solving skills, not skills in general. Regardless, thank you for your note.
In the article headline, It was mentioned Skills. Apologies, maybe I got confused.
One of the best articles on software engineering I ever read. Excellent article, with useful, real life scenarios.
That is music to my ears. Thank you so much!!
Great one! Me being a beginner, I like to read a lot how to become a better developer. Thanks, it was a pleasure reading!
Thoroughly enjoyed reading this one. Thank you @lpasqualis . First time in a long time that I had several "Aha!" moments reading an article. Learnt several things.
Wonderful, thank you for your note.
Great article. Pretty much sums up the lessons learned from my first junior position. I couldn't have put it better myself.
Awesome, thank you Ethan!!
Congrats man! Really good. It takes years to fullfiled all those points. But, when we look back, we get proud of ourselfs. I still can't be away from coding. Can I use that with my students?
Thank you, Matheus. Yes, absolutely, I’d be honored if you used it with your students.
And that's why I love diagrams. Thank you for this article, so many times we use this cycle but I totally forget about it. I agree with you and you make it really easy to understand.
Thank you, Gregor!!
You make serving coffee looks complex, sounds complex, but some how in the end, its easy, its fun, and a lot of thinking! Hats off!
Salute from Malaysia.
Thank you so much for your note, Jamal!! Made my day.
Thank you. Well thought and organized.