Data Augmentation

Although tuning model architecture and hyperparameter are successful factor of building a wonderful model, data scientist should also focus on data. No matter how amazing model you build, garbage in, garbage out (GIGO).
Intuitively, lack of data is one of the common issue in actual data science problem. Data augmentation helps to generate synthetic data from existing data set such that generalisation capability of model can be improved.
In the previous story, we explained how we play with spectrogram. In this story, we will talk about a basic augmentation methods for audio. This story and implementation are inspired by Kaggle’s Audio Data Augmentation Notebook.
Data Augmentation for Audio
To generate syntactic data for audio, we can apply noise injection, shifting time, changing pitch and speed. numpy provides an easy way to handle noise injection and shifting time while librosa (library for Recognition and Organization of Speech and Audio) help to manipulate pitch and speed with just 1 line of code.
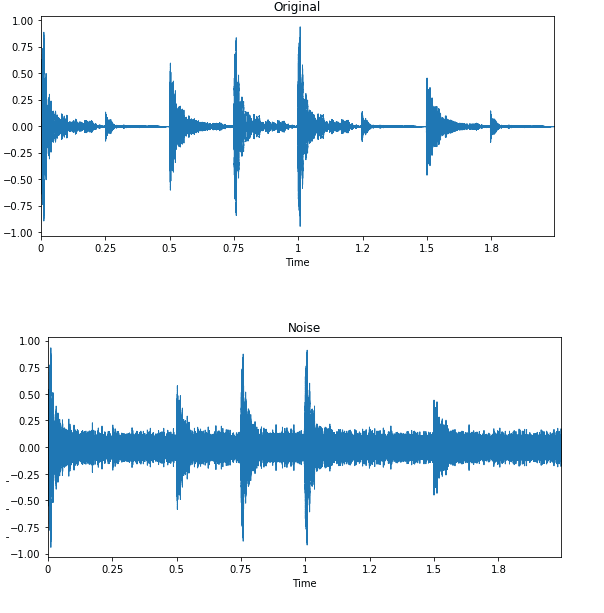
Noise Injection
It simply add some random value into data by using numpy.
import numpy as np
def manipulate(data, noise\_factor):
noise = np.random.randn(len(data))
augmented\_data = data + noise\_factor \* noise
# Cast back to same data type
augmented\_data = augmented\_data.astype(type(data[0]))
return augmented\_data
Shifting Time
The idea of shifting time is very simple. It just shift audio to left/right with a random second. If shifting audio to left (fast forward) with x seconds, first x seconds will mark as 0 (i.e. silence). If shifting audio to right (back forward) with x seconds, last x seconds will mark as 0 (i.e. silence).
import numpy as np
def manipulate(data, sampling\_rate, shift\_max, shift\_direction):
shift = np.random.randint(sampling\_rate \* shift\_max)
if shift\_direction == 'right':
shift = -shift
elif self.shift\_direction == 'both':
direction = np.random.randint(0, 2)
if direction == 1:
shift = -shift
augmented\_data = np.roll(data, shift)
# Set to silence for heading/ tailing
if shift \> 0:
augmented\_data[:shift] = 0
else:
augmented\_data[shift:] = 0
return augmented\_data

Changing Pitch
This augmentation is a wrapper of librosa function. It change pitch randomly
import librosa
def manipulate(data, sampling\_rate, pitch\_factor):
return librosa.effects.pitch\_shift(data, sampling\_rate, pitch\_factor)

Changing Speed
Same as changing pitch, this augmentation is performed by librosafunction. It stretches times series by a fixed rate.
import librosa
def manipulate(data, speed\_factor):
return librosa.effects.time\_stretch(data, speed\_factor)

Take Away
- Above 4 methods are implemented in nlpaug package (≥ 0.0.3). You can generate augmented data within a few line of code.
- Data augmentation cannot replace real training data. It just help to generate synthetic data to make the model better.
- Do not blindly generate synthetic data. You have to understand your data pattern and selecting a appropriate way to increase training data volume.
About Me
I am Data Scientist in Bay Area. Focusing on state-of-the-art in Data Science, Artificial Intelligence , especially in NLP and platform related. Feel free to connect with me on LinkedIn or following me on Github.
Extension Reading
- Audio Data Augmentation in Kaggle competition
- librosa
- Data Augmentation in NLP
- Data Augmentation for Text
- Data Augmentation for Spectrogram

Top comments (0)