
You can check this blog posted by the Dev Community and the Docker Dev
Kubernetes also known as K8s was built by Google based on their experience running
containers in production. It is now an open-source project and is arguably one of the
best and most popular container orchestration technologies out there
Check out the basic concepts of Kubernetes
To understand Kubernetes, we must first understand two things – Container and Orchestration.

*Container *
A system which required to work with each of this, made hell for developers
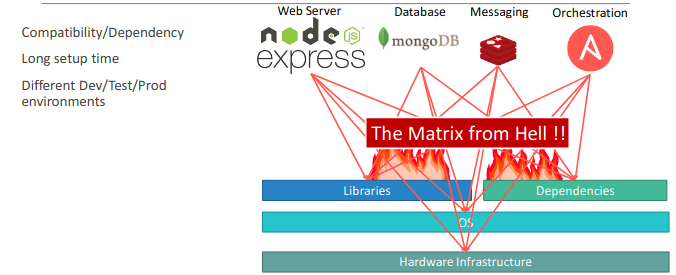
To solve these issues, we had:
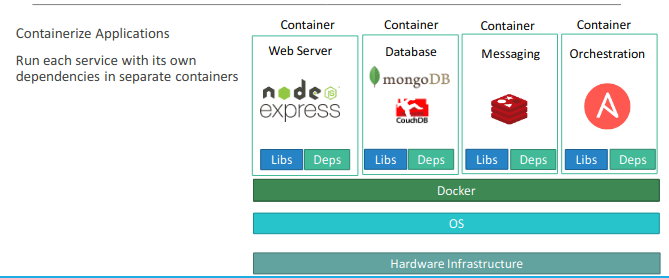
With Docker I was able to run each
component in a separate container – with its own libraries and its own dependencies.All on the same VM and the OS, but within separate environments or containers. We just had to build the docker configuration once, and all our developers could now get started with a simple “docker run” command. Irrespective of what underlying OS they run, all they needed to do was to make sure they had Docker installed on their systems.
So what are containers?
Containers are completely isolated environments, as in they
can have their own processes or services, their own network interfaces, their own mounts, just like Virtual machines, except that they all share the same OS kernel.
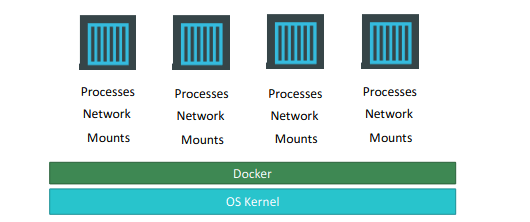
Containers have existed for about 10 years now and some
of the different types of containers are LXC, LXD , LXCFS etc. Docker utilizes LXC containers. Setting up these container environments is hard as they are very low level and that is were Docker offers a high-level tool with several powerful functionalities making it really easy for end users like us .
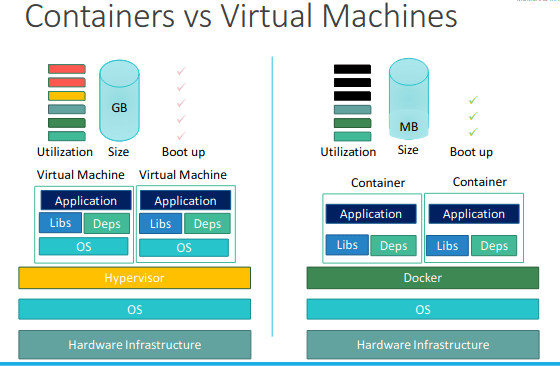
Containers vs Virtual Machines
Containers must have the same Oerating System(OS) for all the softwares. For example, assume 4 software can be run on ubuntu and you are working on docker using ubuntu and you have 1 software which needs windows to work. Now 4 software will work but the one which needs windows won't work, why?
because docker working on Ubuntu here . It can not handle other operating systems.

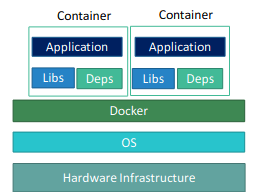
What happens in VMs?
Actually VMs have a Hypervisor layer over OS layer also each software has OS layer in it. That means each software runs depending on its OS layer, For example,
on a VM , you may have different OS dependencies

Look carefully, containers don't have OS layer but VMs do have thus each VM can run with its required OS type but containers need to depend on the OS type which docker inherits.
Also, this makes VMs very heavy and containers very light weight.

Therefore, this becomes the final situation
Benefits of containers:
Light weight & can easily handle multiple software.
Demerits:
It can not run software which needs other type of OS to run t.
How containers work?
With every command, this is how docker works and deploys a software or you can say image to create a container.

Container vs Image
An image is a package or a template, just like a VM template that you might have worked with in the virtualization world. It is used to create one or more containers

Containers are running instances off images that are isolated and have their own environments and set of processes

Container Orchestration

Assume that we have our applications packaged in a docker container.
What if your application relies on other containers such as database or messaging services or other backend services? What if the number of users increase and you need to scale your application? You would also like to scale down when the load decreases.
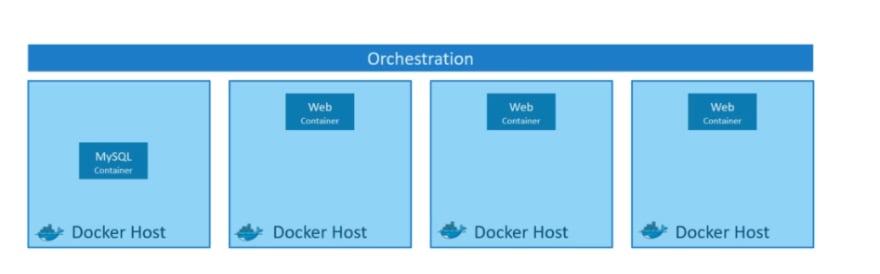
To enable these functionalities you need an underlying platform with a set of resources. The platform needs to orchestrate the connectivity between the containers and automatically scale up or down based on the load. This whole process of automatically deploying and managing containers is known as Container Orchestration.

Kubernetes is one of the famous container orchestration and we will learn about it.
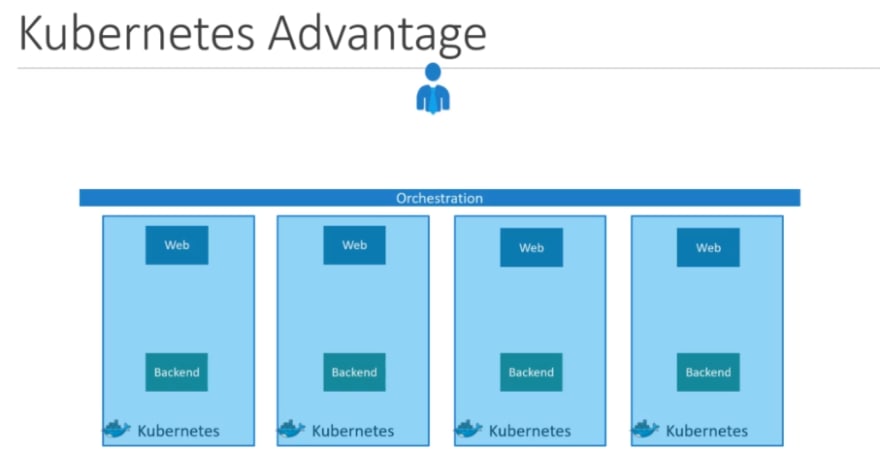
You can see your instance or containers are now running on different nodes Ultimately having multiple copies of each.
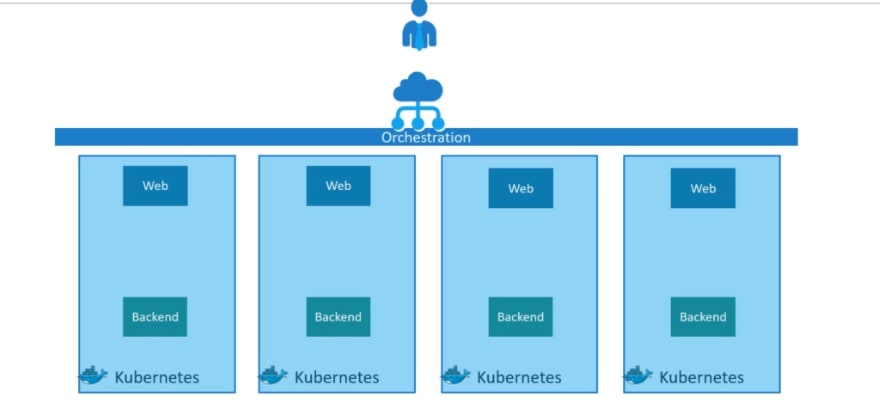
Load balancer is used to scale up the containers .
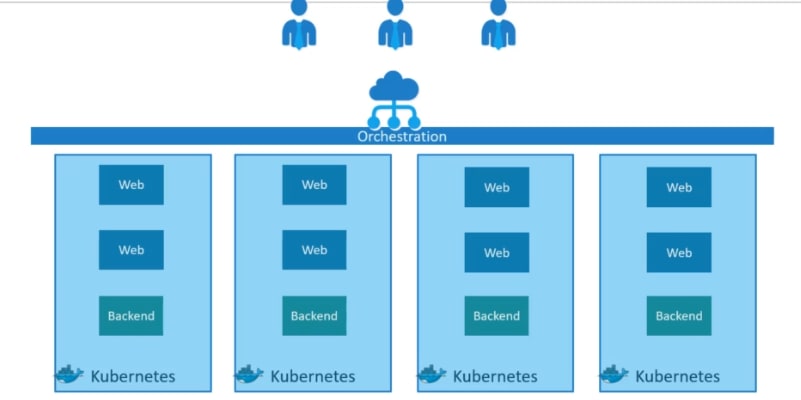
When demand increases, it launches multiple instances of the image.
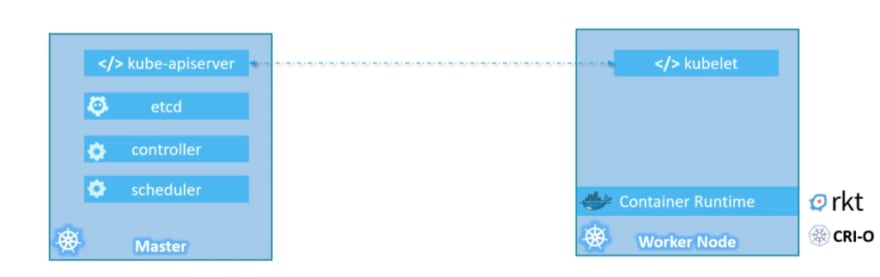
Kubernetes Architecture
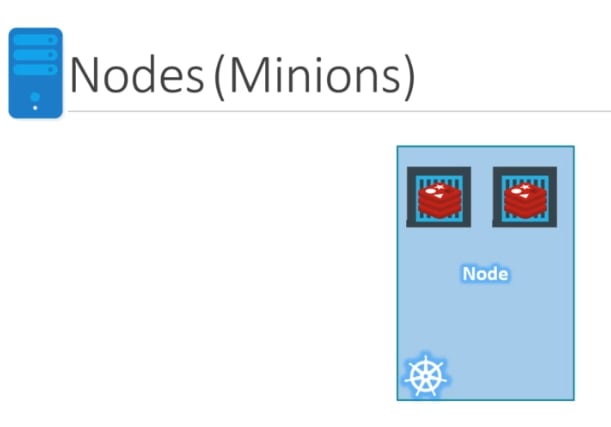
- Node: node is a machine – physical or virtual – on which kubernetes is installed. A node is a worker machine and this is were containers will be launched by kubernetes.
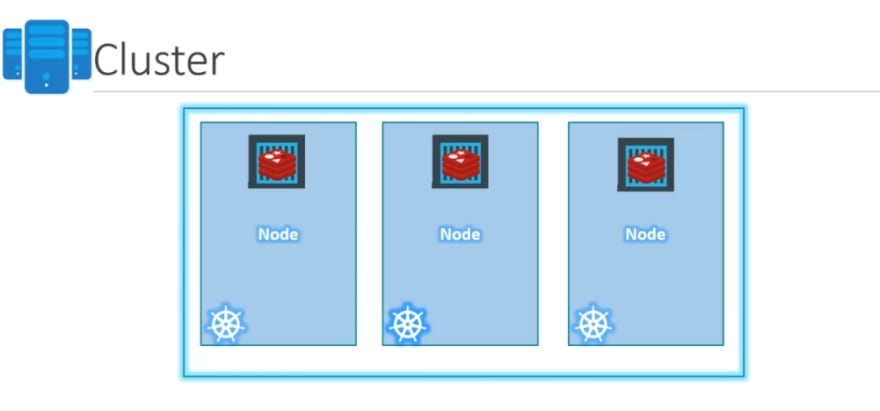
- Cluster: A cluster is a set of nodes grouped together. This way even if one node fails you have your application still accessible from the other nodes. Moreover having multiple nodes helps in sharing load as well
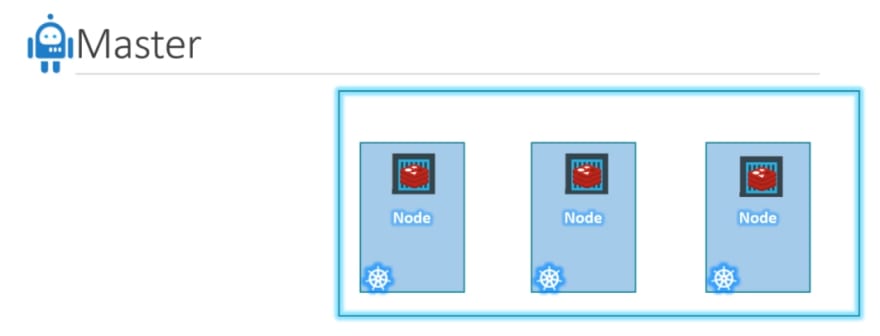
- Master:
An image of just a cluster:
Now we have a cluster, but who is responsible for managing the cluster? Were is the information about the members of the cluster stored? How are the nodes monitored? When a node fails how do you move the workload of the failed node to another worker node?
Master with the cluster:
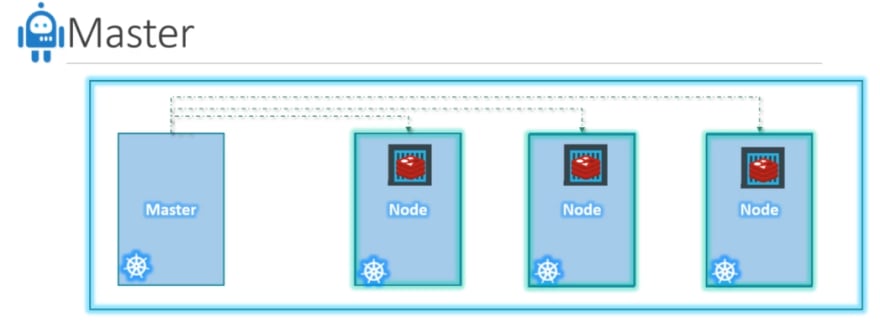
That’s where the Master comes in. The master is another node
with Kubernetes installed in it, and is configured as a Master. The master watches over the nodes in the cluster and is responsible for the actual orchestration of containers on the worker nodes.
When we install Kubernetes, we actually install these:
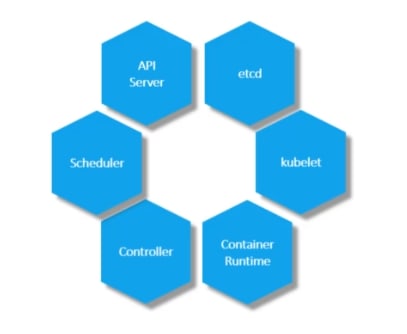
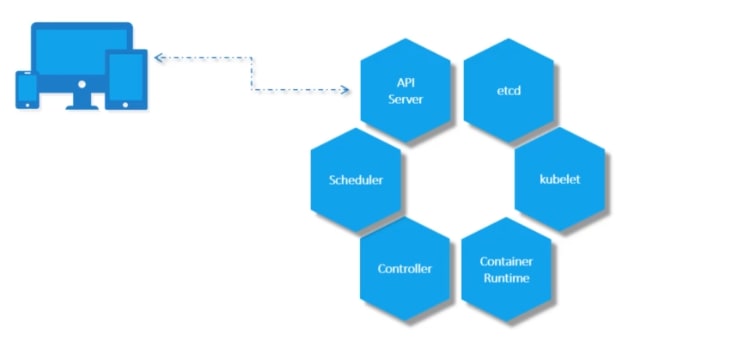
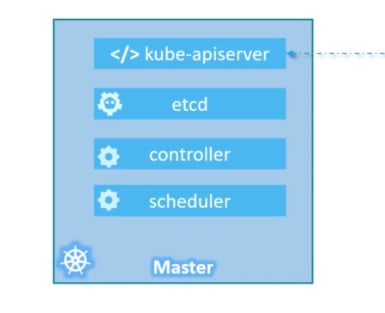
API server: The API server acts as the front-end for kubernetes. The users, management devices, Command line interfaces all talk to the API server to interact with the kubernetes cluster.
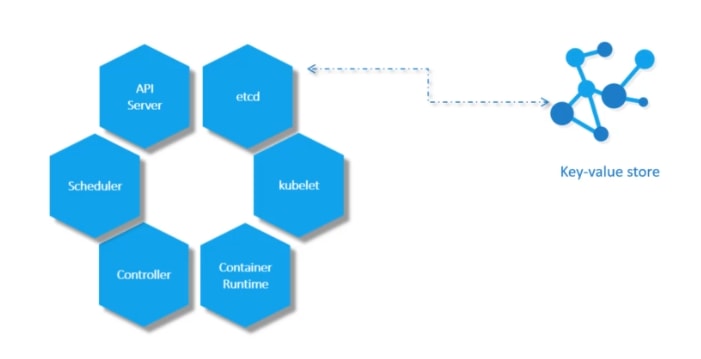
ETCD: ETCD is a distributed reliable key-value store used by
kubernetes to store all data used to manage the cluster. Think of it this way, when you have multiple nodes and multiple masters in your cluster, etcd stores all that information on all the nodes in the cluster in a distributed manner. ETCD is responsible for implementing locks within the cluster to ensure there are no conflicts between the Masters.
Scheduler:
The scheduler is responsible for distributing work or containers across multiple nodes. It looks for newly created containers and assigns them to Nodes.
Controller:
The controllers are the brain behind orchestration. They are responsible for noticing and responding when nodes, containers or endpoints goes down. The controllers makes decisions to bring up new containers in such cases.
Container runtime:
The container runtime is the underlying software that is used to run containers. In our case it happens to be Docker.
Kubelet:
kubelet is the agent that runs on each node in the cluster. The agent is responsible for making sure that the containers are running on the nodes as expected.
*Basics of worker node *
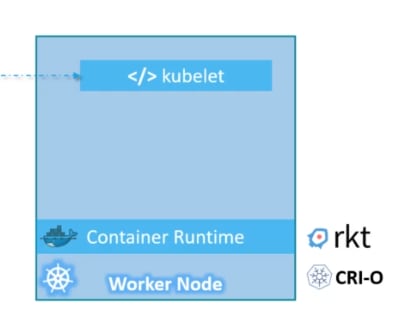
First we have a node where we will have a container run time . In this case we can use Docker but there are other options too.

it also has kubelet to contact with master . Kube-api contacts with kubelet and gives instructions
*Basics of Masters server *
Masters server has kube-api in it which makes it the master.
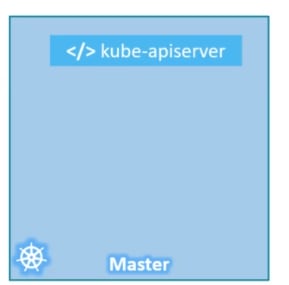
The masters also has etct, controller and scheduler. It also has more component but it is enough by now
Basics of kubectl command

The kube control tool is used to deploy and manage applications on a kubernetes cluster, to get cluster information, get the status of nodes in the cluster and many
other things. The kubectl run command is used to deploy an application on the cluster. The kubectl cluster-info command is used to view information about the cluster and the kubectl
get pod command is used to list all the nodes part of the cluster
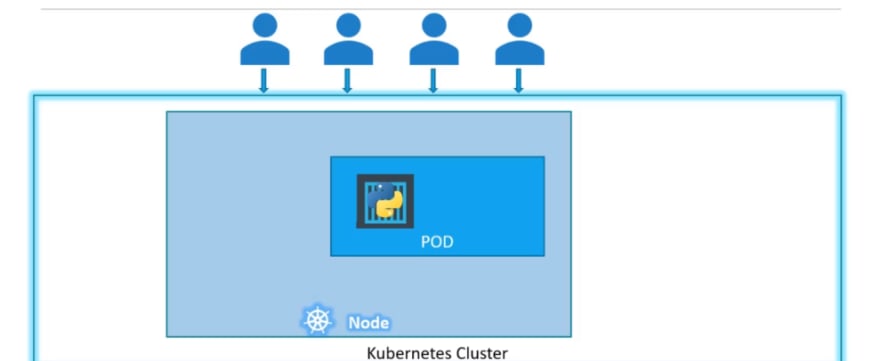
Basics of Pod
he containers are encapsulated into a Kubernetes object
known as PODs. A POD is a single instance of an application. A POD is the smallest object, that you can create in kubernetes.

Let's see a situation:
here is a Single node kubernetes cluster with a pod inside it. The container is encapsulated by the pod.

When we have more people and need additional applications , we need to increase our containers.
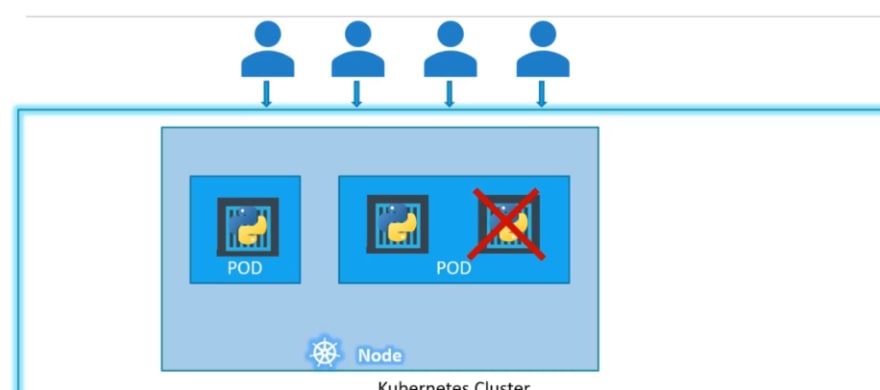
We will node create containers within a pod, rather we will create a new pod with the same application (container)
If your node does not have sufficient capacity, you can add new node with a pod
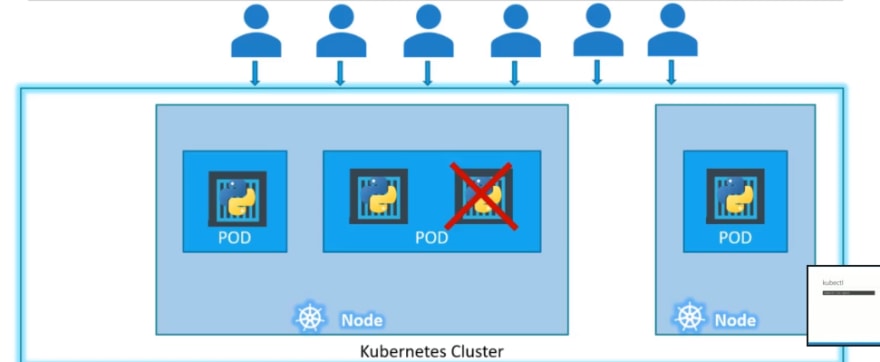
There can be multiple containers in a pod:
A single POD CAN have multiple containers, except for the fact that they are usually not multiple containers of the same kind.
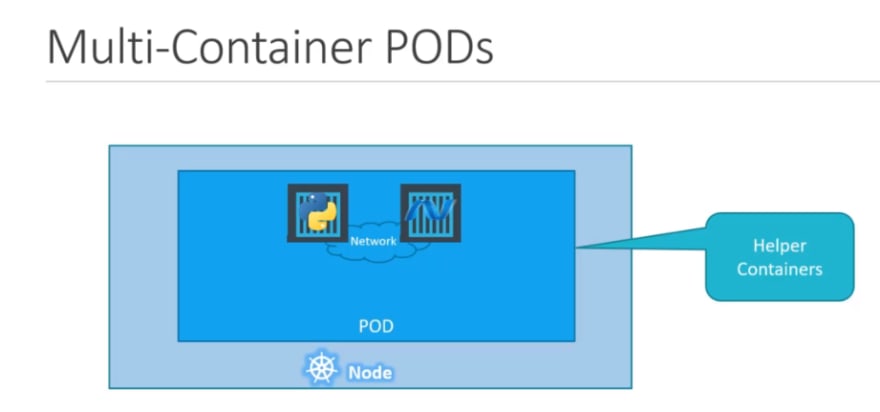
Sometimes you might have a scenario were you have a helper container,that might be doing some kind of supporting task for our web application such as processing a user entered data, processing a file uploaded by the user etc. and you
want these helper containers to live along side your application container. In that case, you CAN have both of these containers part of the same POD, so that when a
new application container is created, the helper is also created and when it dies the helper also dies since they are part of the same POD. The two containers can also
communicate with each other directly by referring to each other as ‘localhost’ since they share the same network namespace. Plus they can easily share the same storage
space as well.
Lets learn why we use pods
lets assume we have created 4 containers
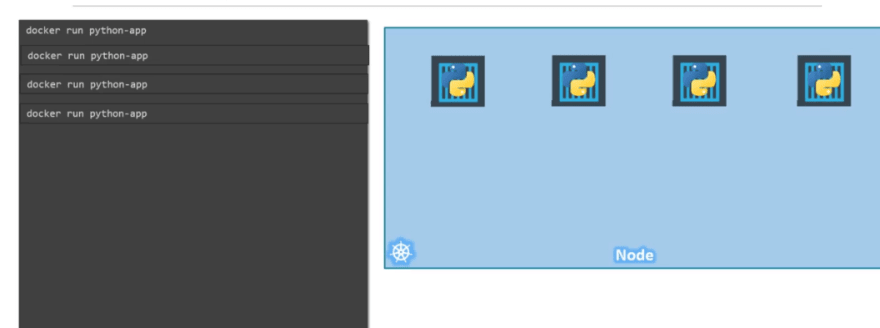
now we need helping containers with each and we need to connect a helping container with a container.
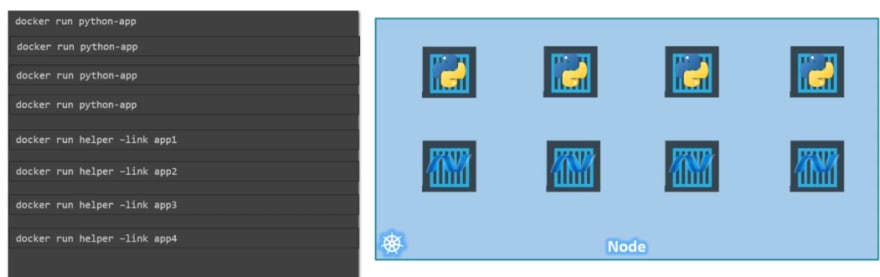
now we need manage network and storage and so many things for corresponding helping container and a container.
But kubernetes does all of this for us by creating a pod and keeps the helping container and a container together.
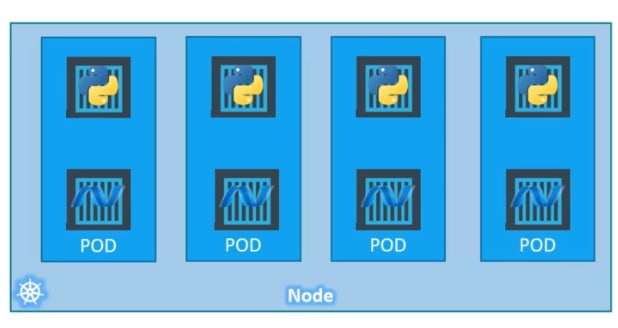
*How to create a pod? *
To create a pod named nginx, using image nginx, we need to use the command
kubectl run nginx --image=nginx
here left side's nginx is the pod name and the right side's nginx means image name from dockerhub


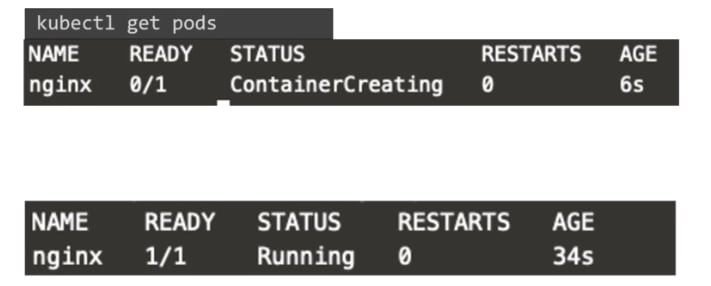
to see the list of pods,
type
kubectl get pods
Also checkout the description of the pod, using
kubectl describe pod nginx
here nginx is the pod name
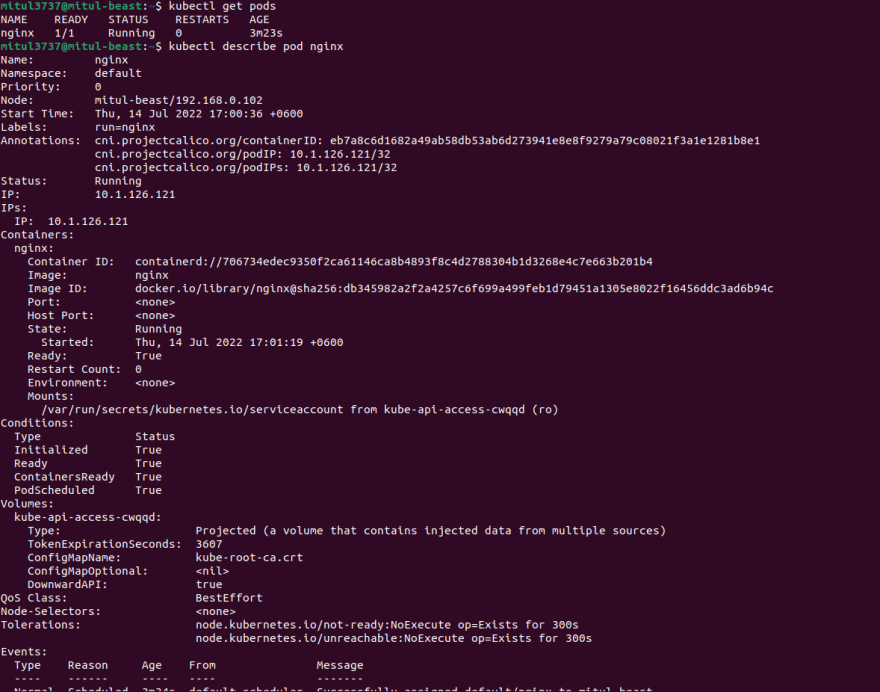
Lets see by parts:

We can see the status, node, IP address and so on.
Lets see what we actually get from the description of the pod:
all info regarding the pod
Name: nginx
Namespace: default
Priority: 0
Node: mitul-beast/192.168.0.102
we can see the node where the pod is assigned and it is within the default namespace.here is the list of namespace:

IP address for the pod:

Containers within a pod:
As we have just nginx container within the pod, we can see just 1 container
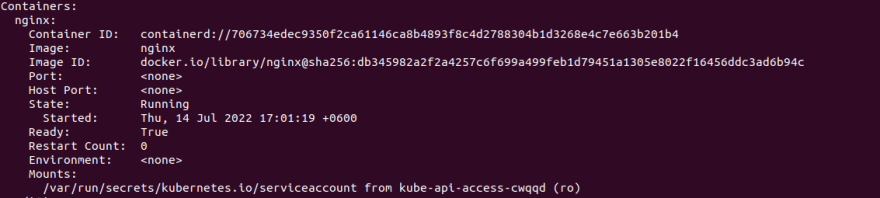
Events that happened while creating the pod:

Lets see again the pods information with some additional data by adding "-o wide" at the last of it.
kubectl get pods -o wide
![]()
It shows node it has been part of etc. Also we see he Internal IP address of the pod it has been assigned.
See official documentations of the pods


Top comments (1)
Very nice information on docker and CKA. I also created a dedicated course on Udemy for CKA exam and more than 1k+ people get benefited
My CKA Course