
In the previous article of the series we got familiar with order types. Today we’ll take a closer look at an order book, processing orders, and dealing with issues of trade information storage.
Supply and demand
I’m pretty sure you remember the law of supply and demand from economics. It shows the market mechanics in pricing:
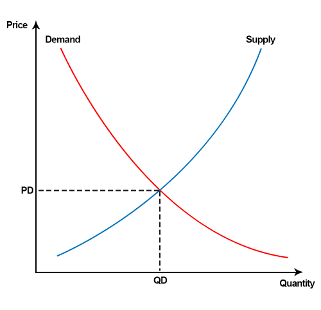
The same mechanics works at exchanges.
An order book is a list where all limit orders of buyers and sellers go. This way, the current interest to a particular financial instrument is demonstrated.
If we transform the previous graph with regard to an order book, we’ll have something like that:
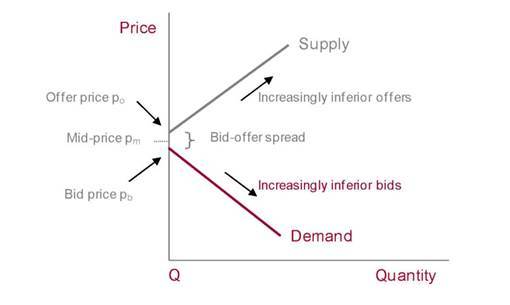
We can see that the market price appears when the maximum bid price equals the minimum offer price. The difference between these prices is called spread. Spread is an important indicator as it is connected with an instrument liquidity. The less the spread is, the more liquidity the instrument has. To provide liquidity within exchange trading process, a limit on maximum spread is often imposed. If this limit is exceeded, bidding is stopped.
Creating an order
Let’s have a look at an order life cycle, from getting to the exchange to being executed or cancelled. For ease, we’ll focus on a foreign exchange market. A special process is responsible for order processing logic. Let’s call it a market controller.
So, a trader creates an order and it gets to the exchange. The controller must make sure that the trader has enough liquidity to create the requested type of order. As a source of information, an internal accounting server or any external APIs can be used.
To fulfil this order immediately, the market must have a counterbid, or a so-called matching order. If the counterbid exists, then a smaller order from the pair is executed fully, and the bigger one partially — of course, as long as partial order fulfillment is allowed by the order trade instructions. If the counterbid doesn’t exist, a new order gets into the order book and takes its place in the list of the orders of its type.
Since only pending orders can get into the order book, we need to create special lists for other order types.
In all order lists the buy side should be sorted in descending order while the sell one — in ascending order. The first item of the limit orders list shapes the best ask and bid prices respectively.
One more important point is the order of execution. The controller must implement FIFO. That is why, if the prices of two orders are identical, the first one to fulfil is the one which has been created first.
In user interface the order book looks like a table with a set of price levels. It shows both buy limit orders and sell limit orders.
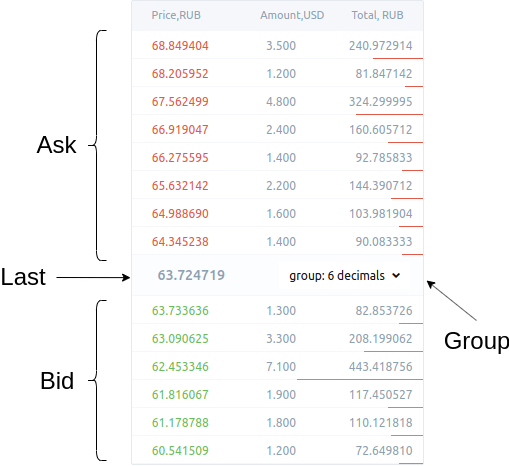
Buy orders and sell orders are in different colours to be distinguished easier.
Price levels aggregation
The order book depth is a number of price levels. For active markets with lots of pending orders, which differ as little as they can, this depth can be too big to be shown in the trader’s terminal. We need a tool for grouping the levels to assess the whole book.
By cutting off one decimal place at a time and grouping the levels, we can reduce the number of levels with each step.
Fulfilling and cancelling orders
After an order in the order book has been executed or cancelled, the controller must update the book and delete the order. It also notifies all interested parties of the changes in the book.
Handlers architecture and scaling
Taking into account required performance and reliability of the system, we need to define the approaches to scale applications and data storage layers.
Normally, vertical scalability is used for exchanges. The code of order processing and user accounts processing is run on one machine as a monolith process. Such approach demonstrate good performance but has certain limitations — in any case, vertical scalability has its limits in terms of CPU and storage capacity.
As part of the experiment, I decided that market processing should be scaled horizontally. Each individual instrument is handled by its own process. The processes are automatically distributed between cluster nodes. In case of failure, a market is moved to another node without loss of state.

The system formula is quite simple: M handlers are distributed on K cluster nodes and use L data storages.
This model lets us scale a system up to approximately 150k nodes, and each market controller can process about 30k RPS.
As the flow of orders is different at different markets and depends on users participation, we can divide all markets into several groups: big, medium, and small ones. Each node has the settings enabling us to specify the limits of the markets which it can process. The master is evenly and automatically distributing the markets of the same type between the cluster nodes. If the cluster composition has been changed, the markets are redistributed. This way we can achieve more or less equal distribution of the system load.
Nodes in management UI look something like this:

Data storage
The order book is constantly changing and must be stored in memory. For MVP I’ve opted for Tarantool with WAL as an in-memory storage. All historical data will be stored in PostgreSQL.
The storage scheme for current and historical data must comply with the chosen scheme of code scalability of the handlers. Each market can use its own postgres and tarantool. To make it possible, let’s combine postgresql and tarantool into a single entity — market data storage. While setting the market, an administrator is able to manage the storages. To retain flexibility, we’ll be indicating the unique id of the connection pool instead of credentials to certain postgresql and tarantool instances. The pool interface is supported by the platform. So, the storage looks like this in admin UI:

While setting the market, the administrator must indicate at least one storage for each market. If several are indicated, we’ll have a market with logical replication of data. This function enables us to configure the reliability and performance of the data storage scheme.
Order book data
Tarantool uses spaces for stored data organisation. The declaration of spaces necessary for the order book looks like this:
book = {
state = {
name = 'book_state',
id = 1,
},
orders = {
limit = {
buy_orders = {
name = 'limit_buy_orders',
id = 10,
},
sell_orders = {
name = 'limit_sell_orders',
id = 20,
},
},
market = {
buy_orders = {
name = 'market_buy_orders',
id = 30,
},
sell_orders = {
name = 'market_sell_orders',
id = 40,
},
},
...
},
orders_mapping = {
name = 'orders_mapping',
id = 50,
},
}
As several markets can store their data on one tarantool instance, let’s add market id to all instances. Current book implementation is based on the so-called precalculated principle. When the book is being updated, the groups are automatically recalculated. For example, we add an order to the market with 6 digit precision for prices. We can have 6 possible groups of prices + one slice with the order raw data which need to be updated.
There is a number of orders_mapping orders for getting the client’s active orders.
Thanks to tarantool’s indexes and iterators, lua-code for the order book storage consists of 600 lines only (together with initialization).
Historical data
Market data are stored in tables, separately for each market. Let’s take a look at the set of basic tables.
Orders execution history
To save the results of order processing, we have history table. All the orders that are completely fulfilled and the orders which are cancelled but partially fulfilled go there.
CREATE TABLE public.history
(
id uuid NOT NULL,
ts timestamp without time zone NOT NULL DEFAULT now(),
owner character varying(75) COLLATE pg_catalog."default" NOT NULL,
order_type integer NOT NULL,
order_side integer NOT NULL,
price numeric(64,32) NOT NULL,
qty numeric(64,32) NOT NULL,
commission numeric(64,32) NOT NULL,
opts jsonb NOT NULL,
CONSTRAINT history_pkey PRIMARY KEY (id, ts)
)
Reports for customers are computed based on their trade history which is stored in this table.
Historical data feed
For analytical purposes and historical data feed building, the market controller must save the information about the event after every transaction. The ticks table is used to commit all market changes:
CREATE TABLE public.ticks
(
ts timestamp without time zone NOT NULL,
bid numeric(64,32) NOT NULL,
ask numeric(64,32) NOT NULL,
last numeric(64,32) NOT NULL,
bid_vol numeric(64,32),
ask_vol numeric(64,32),
last_vol numeric(64,32),
opts jsonb DEFAULT '{}'::jsonb,
CONSTRAINT ticks_pk PRIMARY KEY (ts)
)
It contains prices and market volume after a transaction has been made. The opts field contains service-based data, for example, the description of the orders involved in the transaction.
Data feed for charts
The ticks table is enough to be able to build stock charts. It contains the so-called raw data stream, but postgresql has powerful analytical functions and enables us to aggregate data on request.
Troubles start when there is too much of data and lack of available computing resources. To solve it, let’s create a table with pre-calculated data:
CREATE TABLE public.df
(
t timestamp without time zone NOT NULL,
r df_resolution NOT NULL DEFAULT '1m'::df_resolution,
o numeric(64,32),
h numeric(64,32),
l numeric(64,32),
c numeric(64,32),
v numeric(64,32),
CONSTRAINT df_pk PRIMARY KEY (t, r)
)
In the next article we’ll talk about working with time series in Postgresql, preparing data for df table, and building charts.
Conclusion
This article has given us a better understanding of the main moments of order book organisation, as well as order processing mechanism. We have also had some practice of working with market data.
The chosen storage scheme enables us to start with just one storage for all markets and, as the project grows, spread the markets to different storages and place them as close as possible to market handlers.

Top comments (0)