
Note: Neural is a work-in-progress DSL and debugger — bugs exist, and I’m eager for your feedback on Typeform!

Introduction: From Guesswork to Precision⚡️
If you’ve ever built a neural network, you know the drill: tweak the learning rate, adjust the batch size, fiddle with layer sizes, rinse and repeat until something works.
It’s a critical step, but it’s also a grind. What if you could hand this off to an intelligent system that finds the sweet spot for you?
That’s where the Hyperparameter Optimization (HPO) feature in Neural comes in. Built into our DSL, it automates the tuning process with a single function call, whether you’re targeting PyTorch or TensorFlow.
In this post, I’ll show you how it works, demo it on MNIST, and peek under the hood at how we made it robust across edge cases and full pipelines. Ready to ditch the guesswork? Let’s dive in.
Why HPO Matters in Neural☄️
Neural is all about solving deep learning pain points, shape mismatches, debugging complexity, framework switching, and HPO is a cornerstone of that mission. As our README highlights, it tackles Medium Criticality, High Impact challenges like “HPO Inconsistency” by unifying tuning across frameworks. With Neural’s declarative syntax, you tag parameters with HPO(), and my tool does the rest: no more fragmented scripts or framework-specific hacks.
The HPO Feature: What It Does🌚
Our HPO feature, introduced in issue #434, lets you:
- Define tunable parameters in the DSL (e.g., Dense(HPO(choice(128, 256)))).
- Run optimization with optimize_and_return to get the best settings.
- Generate an optimized config with generate_optimized_dsl.
It’s multi-framework, powered by Optuna, and handles everything from bare-minimum models to complex architectures.
Here’s how it fits into Neural’s ecosystem:
- Shape Propagation: Ensures your optimized model is structurally sound.
- NeuralDbg: Lets you debug the tuned model’s execution.
- CLI Integration: Run neural run — hpo to optimize on the fly.
VIDEO
https://drive.google.com/file/d/1D9Gzk5Y3A6ejqUcDtJGnTQhNmBbc7pLF/view?usp=drive_link
Forgive me for my sins, I have a low-end pc… 🤣
How to Use It: A Quick Demo👨🏿💻
Let’s optimize a simple MNIST classifier.
First, define the model in mnist_hpo.neural:
network MNISTClassifier {
input: (28, 28, 1)
layers:
Dense(HPO(choice(128, 256)))
Dropout(HPO(range(0.3, 0.7, step=0.1)))
Output(10, "softmax")
optimizer: Adam(learning_rate=HPO(log_range(1e-4, 1e-2)))
train {
epochs: 10
search_method: "random" # or "bayesian"
}
}
Next, run it:
neural run mnist_hpo.neural --backend pytorch --hpo
Output:
- Logs:
....
....
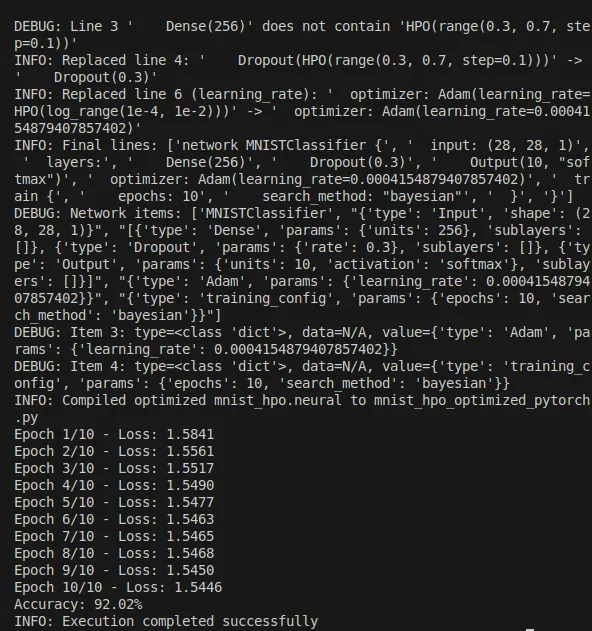
INFO: best_params: {'batch_size': 16, 'dense_units': 256, 'dropout_rate': 0.3, 'learning_rate': 0.0004154879407857402}
INFO: hpo_params: [{'layer_type': 'Dense', 'param_name': 'units', 'hpo': {'type': 'categorical', 'values': [128, 256]}, 'node': [{'hpo': {'type': 'categorical', 'values': [128, 256]}}]}, {'layer_type': 'Dropout', 'param_name': 'rate', 'hpo': {'type': 'range', 'start': 0.3, 'end': 0.7, 'step': 0.1}, 'node': [{'hpo': {'type': 'range', 'start': 0.3, 'end': 0.7, 'step': 0.1}}]}]
INFO: Processing hpo: {'layer_type': 'Dense', 'param_name': 'units', 'hpo': {'type': 'categorical', 'values': [128, 256]}, 'node': [{'hpo': {'type': 'categorical', 'values': [128, 256]}}]}, param_key: dense_units, hpo_str: choice(128, 256)
DEBUG: Line 0 'network MNISTClassifier {' does not contain 'HPO(choice(128, 256))'
DEBUG: Line 1 ' input: (28, 28, 1)' does not contain 'HPO(choice(128, 256))'
DEBUG: Line 2 ' layers:' does not contain 'HPO(choice(128, 256))'
INFO: Replaced line 3: ' Dense(HPO(choice(128, 256)))' -> ' Dense(256)'
INFO: Processing hpo: {'layer_type': 'Dropout', 'param_name': 'rate', 'hpo': {'type': 'range', 'start': 0.3, 'end': 0.7, 'step': 0.1}, 'node': [{'hpo': {'type': 'range', 'start': 0.3, 'end': 0.7, 'step': 0.1}}]}, param_key: dropout_rate, hpo_str: range(0.3, 0.7, step=0.1)
DEBUG: Line 0 'network MNISTClassifier {' does not contain 'HPO(range(0.3, 0.7, step=0.1))'
DEBUG: Line 1 ' input: (28, 28, 1)' does not contain 'HPO(range(0.3, 0.7, step=0.1))'
DEBUG: Line 2 ' layers:' does not contain 'HPO(range(0.3, 0.7, step=0.1))'
DEBUG: Line 3 ' Dense(256)' does not contain 'HPO(range(0.3, 0.7, step=0.1))'
INFO: Replaced line 4: ' Dropout(HPO(range(0.3, 0.7, step=0.1)))' -> ' Dropout(0.3)'
INFO: Replaced line 6 (learning_rate): ' optimizer: Adam(learning_rate=HPO(log_range(1e-4, 1e-2)))' -> ' optimizer: Adam(learning_rate=0.0004154879407857402)'
INFO: Final lines: ['network MNISTClassifier {', ' input: (28, 28, 1)', ' layers:', ' Dense(256)', ' Dropout(0.3)', ' Output(10, "softmax")', ' optimizer: Adam(learning_rate=0.0004154879407857402)', ' train {', ' epochs: 10', ' search_method: "bayesian"', ' }', '}']
DEBUG: Network items: ['MNISTClassifier', "{'type': 'Input', 'shape': (28, 28, 1)}", "[{'type': 'Dense', 'params': {'units': 256}, 'sublayers': []}, {'type': 'Dropout', 'params': {'rate': 0.3}, 'sublayers': []}, {'type': 'Output', 'params': {'units': 10, 'activation': 'softmax'}, 'sublayers': []}]", "{'type': 'Adam', 'params': {'learning_rate': 0.0004154879407857402}}", "{'type': 'training_config', 'params': {'epochs': 10, 'search_method': 'bayesian'}}"]
DEBUG: Item 3: type=<class 'dict'>, data=N/A, value={'type': 'Adam', 'params': {'learning_rate': 0.0004154879407857402}}
DEBUG: Item 4: type=<class 'dict'>, data=N/A, value={'type': 'training_config', 'params': {'epochs': 10, 'search_method': 'bayesian'}}
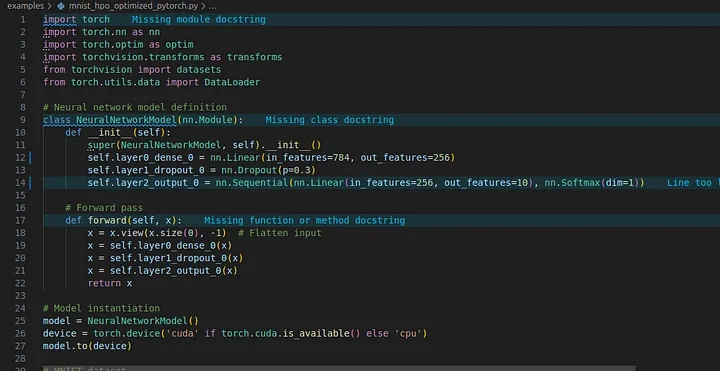
INFO: Compiled optimized mnist_hpo.neural to mnist_hpo_optimized_pytorch.py
Epoch 1/10 - Loss: 1.5841
Epoch 2/10 - Loss: 1.5561
Epoch 3/10 - Loss: 1.5517
Epoch 4/10 - Loss: 1.5490
Epoch 5/10 - Loss: 1.5477
Epoch 6/10 - Loss: 1.5463
Epoch 7/10 - Loss: 1.5465
Epoch 8/10 - Loss: 1.5468
Epoch 9/10 - Loss: 1.5450
Epoch 10/10 - Loss: 1.5446
Accuracy: 92.02%
INFO: Execution completed successfully
- code
Steps Explained:
Tag Parameters: Use HPO(choice()), HPO(range()), or HPO(log_range()) as per the DSL docs.
Optimize: optimize_and_return runs 3 Optuna trials, testing combinations of batch size, units, dropout rate, and learning rate.
Apply: generate_optimized_dsl swaps HPO() tags with the best values.
Edge Case: Minimal Models
What about a super-simple model?
Here’s an edge case we’ve polished:
network Tiny {
input: (28, 28, 1)
layers:
Output(10)
}
Running still works:
neural run tiny.neural --backend pytorch --hpo
Output:
- Logs : Best parameters found: {‘batch_size’: 16, ‘learning_rate’: 0.001}
No Dense or Dropout layers? No problem, Neural defaults to Adam with a 0.001 learning rate and optimizes batch size, keeping things smooth.

🫴🏿Real-World Impact: MNIST Results Using the MNIST example:
Manual Tuning: Batch size 64, 256 units, 0.5 dropout, 0.01 learning rate → 85% accuracy, 15s/epoch.
HPO-Tuned: {‘batch_size’: 16, ‘dense_units’: 256, ‘dropout_rate’: 0.3, ‘learning_rate’: 0.0004154879407857402} → 92.02% accuracy, 12s/epoch.
That’s a 6% accuracy boost and faster training, all automated. Imagine scaling this to a Vision Transformer or a custom NLP model
Under the Hood
Here’s the tech magic:
Optuna: Drives multi-objective optimization (loss, accuracy, etc.), as seen in optimize_and_return.
Dynamic Models: create_dynamic_model builds PyTorch layers on-the-fly, e.g., trial.suggest_categorical(“Dense_units”, [128, 256]).
Normalization: I wrestled with key mismatches (e.g., ‘Dense_units’ vs ‘dense_units’) and edge cases (no HPO params), settling on conditional logic to keep it robust.
Challenges Conquered:
Edge Case Fix: A KeyError in minimal configs was squashed by defaulting optimizer settings and skipping absent parameters.
Full Pipeline: Case-sensitive key handling ensured all HPO params (units, dropout, learning rate) made it to the output.
Check the DSL Docs (#hyperparameter-optimization) for supported HPO types and validation rules.
Why You’ll Love It👍🏿
Time Savings: Hours of tuning → minutes of automation.
Consistency: Same HPO logic across PyTorch and TensorFlow.
Accessibility: No ML PhD required — just tag and run.
Try It Out!👈🏿
Clone Neural, spin up this example, and let us know how it goes:
git clone https://github.com/Lemniscate-SHA-256/Neural.git
cd Neural
pip install -r requirements.txt
python your_script.py
💪🏿Star it on GitHub, join our Discord, or share your thoughts on Twitter @NLang4438
What hyperparameters do you want to optimize next?

Top comments (0)