When it comes to working with SQL, we all want the same things: speed and scale. And on top of that we, want to be easy—maybe even fun. From data collection to processing, to analysis, to putting it into action; we work with data because we want to reach a goal, not because we love parsing JSON, type checking, inspecting logs, and writing documentation. That’s why we need good tools—especially ones that evolve with our changing pace and work styles. That’s why I wanted to share these tools with you today.
I’ve been working in SQL in a few roles, for a few years. It’s been long enough to understand the work, but not long enough to be tied to antiquated methodologies or systems. To me, these tools reflect a shift towards a modern SQL workflow to fit the pace and flexibility of modern work. I appreciate both the innovation of these tools and ingenuity used to solve laborious SQL tasks.
These tools cover everything from getting data into your database, to transforming your data, to analyzing your data, and even sharing your findings. Ok, enough with the intro, let’s get to the SQL tools!
Data Collection
Without data in your database, SQL is entirely useless. These tools make it easy to cross the bridge from messy data to a SQL database.
Numidian Convert
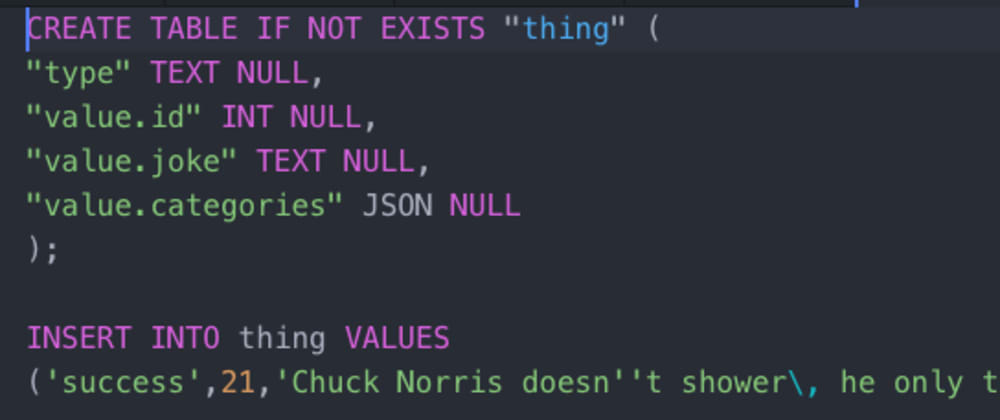
Everybody has run into the problem of having a database full of interesting data and some other file that would be a lot more interesting if it were in the database. Numidian Convert makes it incredibly easy to get data from JSON and CSV files into databases. All you have to do is input a file and define your transformations then it gives you the CREATE TABLE and INSERT statements.
Numidian convert supports Postgres, MySQL, and SQLite. They have a free offering that allows you to convert files up to 10MB, and they also offer a paid API when you need to convert a lot of data for $20/mo.
Panoply
You know the problem. All your data comes from a bunch of APIs, spreadsheets, and file systems and you just want it in one place where you can connect your SQL tools. Panoply is a cloud data warehouse with a ton of native data pipelines from including MySQL, MongoDB, Salesforce, Stripe, Google Analytics, Google Sheets and a ton of other integrations.
Panoply is built on AWS infrastructure and can be used with Azure too. It is basically the power of Redshift except 10x easier to setup, manage and scale. They offer a full-featured free trial that allows you to start querying all your data in less time than it takes to finish a cup of coffee.
Data Exploration
If you’ve ever had to wrap your head around a new DB, you’ve probably had to spend a lot of time querying system tables just to figure you where the good data lives and how much data there is.
Schema Explorer
Schema Explorer, recently open-sourced, is a friendly UI wrapper around all the queries that you would make to get familiar with a new database. What is especially nice about the tool is, if you have foreign key constraints in place, Schema Explorer will draw out a diagram of your database for you!

The software is pretty lean (it appears to be a one-man show) but it supports both Mac and Windows and is 100% free and open source on Github.
Data Transformations
When it comes to scaling, especially scaling out the complexity and application of data across an organization, you have to have a good process. These two tools are really impressive in how they’ve made complex data transformation workflows simple.
Dataform
Consistent with the, no/low maintenance infrastructure trend, Dataform wraps up the entire Transform segment of the ELT process into a SaaS application. This makes it easier than ever to democratize trustworthy tables for end-user analysis. The best part: everything is managed in SQL or in a well-designed UI.
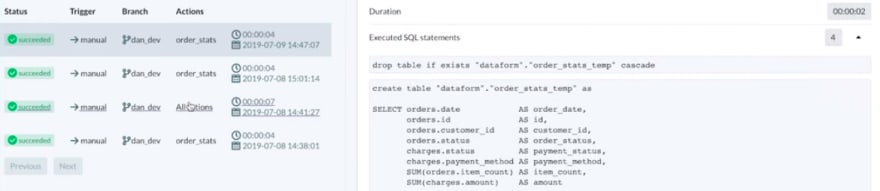
Dataform works with Redshift, BigQuery, Panoply, Azure SQL DW, and Snowflake data warehouses. It also seamlessly handles version control via Github within the UI. And again, all this power comes without maintaining any infrastructure!
DBT (Data Build Tool)
For those of you who like total control of your data pipelines (and don’t mind maintaining the infrastructure that comes along with it) DBT is the transformation tool for you. DBT is among my favorite Github repos because they have really thought about all the challenges of data preparation and transformation down to generating documentation on the fly! DBT predates Dataform so the DAG-ish workflows and templating feel similar except you can control every detail of your deployment.
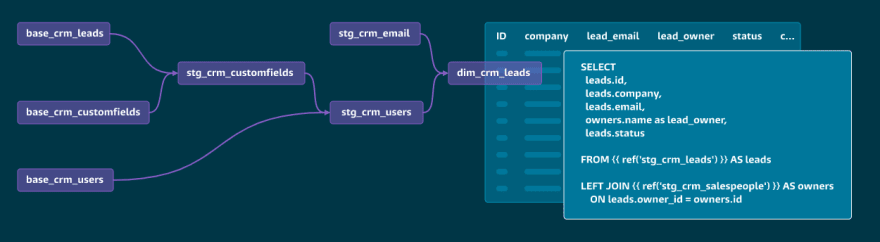
DBT is a command-line tool that supports Postgres, Redshift, Bigquery, Panoply, and Snowflake, community/partial support for Microsoft SQL Server, Presto, and Spark. Also, their community is really impressive. With “customers” like Hubspot and Seatgeek, you know you're amongst some solid data company.
Data Access and Sharing
This is probably the most solved problem in the SQL space (if not over-solved). But as our workflows evolve, so should our tools. These two tools stand out to me because they are natural extensions from modern collaboration tools, Slack and Google Sheets.
SQLBot
If you’re like me, you’ve integrated every app you use with Slack. I’m not kidding, I have a slash command for Chuck Norris jokes. It should come as no surprise that I was really excited when I learned about SQLBot. I had always thought it would be cool, security aside, to write SQL into Slack and get results back. SQLBot is the next best thing. It allows you to set up slash commands that return query results. You can get your reports without leaving your conversation!
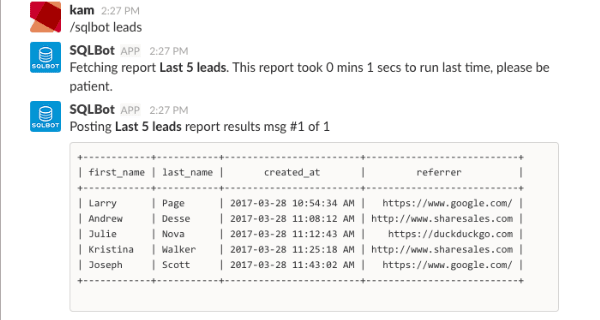
SQLBot is a newer app that is fresh from IndieHackers so while the functionality is amazing the Bootstrap interface keeps things pretty simple. It supports Postgres, MySQL, SQLServer, Amazon Redshift, and Panoply and allows you to drop variables in to your queries which is pretty slick.
SeekWell
As much as I believe that everybody should learn SQL, there are, and probably always will be those who love their spreadsheets too much to let them go. Lucky for us, SeekWell has built a bridge between your database and your co-workers spreadsheets. The tool allows you to write SQL, or Python via a Jupyter notebook and import the data directly into Google Spreadsheets and Slack. You can even schedule queries from both your database and Python notebooks.
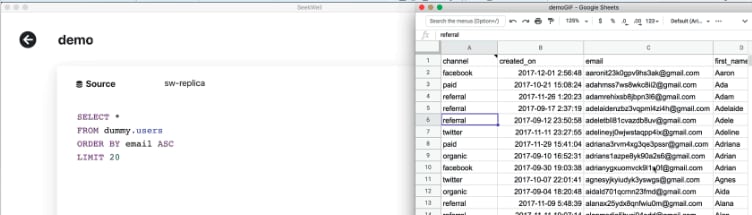
SeekWell supports MySQL, Postgres, Redshift, Panoply, Microsoft SQL Server, and Snowflake and I have been pretty impressed by their development speed. It seems like every time I check back with their product, the tool’s experience is becoming more seamless.
Documentation
At the intersection between nobody’s-got-time-for-that and this-is-so-useful lives our old friend documentation. Here is a new tool that will do the job nicely and is pretty painless.
dbdiagram.io
ER diagrams and data dictionaries are a data analyst’s best friends as they get acquainted with a new database or data warehouse but building these from scratch with Google Sheets or Google Drawings is lame and boring and doesn’t take advantage of code to take care of the repetitive tasks that we love to automate. dbiagram.io took a novel approach to this problem and translates a markup language that describes a database and it’s relationships into interactive diagrams that show the database tables.
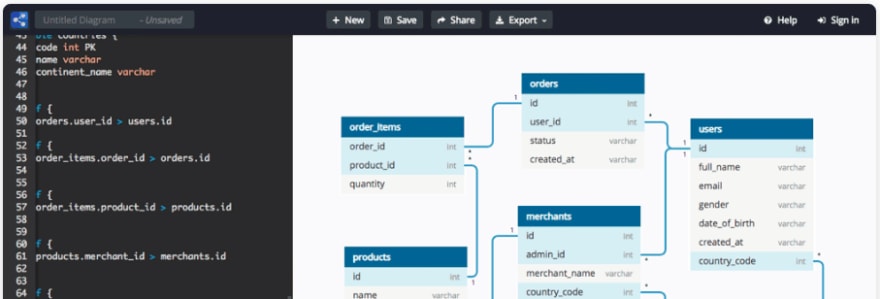
The free tool is open source, as is the DBML, their markup language that the tool uses, and is maintained by the good people at Holistics. If you have a big DB that you need to diagram, I’d recommend looking into dbdiagram.io to see how you can programmatically generate your ER diagram for free!
I hope some of these tools will bring joy to your SQL work in 2020!




Top comments (7)
Thanks for the mention Trevor! For anyone that'd like a sneak peak at what we're working on next or a demo of the current product, feel free to DM me on Twitter or email me at mike@seekwell.io. There's a 90 second demo fo the product here: loom.com/share/256e83c925744ad9977... (please pardon the background noise)
Nice article! On the Dataform section has a mistake "ELT" instead of "ETL"
Good catch Oluwasogo! It was intentional. The article Mike mentions below shows the difference. The main difference with DBT and Dataform and previous ETL solutions is that they are built to manage the "Transformation" part of the pipeline after the data is in a data warehouse rather than before the data is loaded, thus ELT.
that's probably on purpose, see here blog.panoply.io/etl-vs-elt-the-dif...
Great post Trevor! Do you think you could do an update for 2021? 🎉
Thanks, Trevor for this article. Many new tools for my belt :)
I think there's one more tool that should be on that list: github.com/k1LoW/tbls
I'll have to take a look!