
Building an Intelligent BigQuery Chatbot with LLMs
In today's data-driven world, extracting insights from data warehouses like BigQuery remains challenging for many business users without SQL expertise. What if we could bridge this gap with natural language? In this post, I'll walk through how I built a BigQuery chatbot that translates natural language questions into optimized SQL queries using Google's Gemini AI.
The Challenge
Many organizations store terabytes of valuable data in BigQuery, but accessing this information typically requires:
- SQL knowledge
- Understanding of the database schema
- Query optimization skills
This creates bottlenecks where data analysts become the gatekeepers of information, slowing down decision-making across organizations.
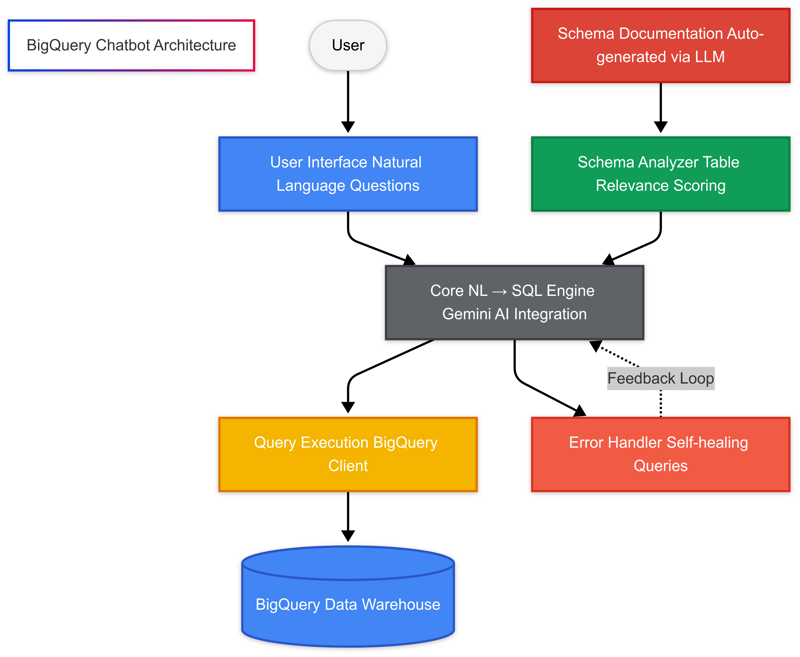
Solution Architecture
I developed a modular system that combines the power of large language models with BigQuery's performance. Here's how it works:
- Schema Understanding: The system first analyzes and documents the database schema, creating rich metadata
- Question Analysis: When a user asks a natural language question, the system identifies relevant tables and fields
- SQL Generation: Using Gemini AI, it converts the question into optimized SQL
- Query Refinement: The query undergoes multiple iterations of reflection and improvement
- Error Handling: If execution fails, the system automatically attempts to fix the query
- Results Delivery: The final data is returned to the user in an accessible format
Key Components
1. Schema Documentation Generator
The first module generates comprehensive documentation for the BigQuery schema:
def generate_table_description(table_name, schema_fields):
prompt = f"""
As a data analyst, generate a concise and precise description for a BigQuery table named '{table_name}' with the following fields:
{', '.join([field.name for field in schema_fields])}
Requirements:
1. Explain the table's primary purpose and its business context
2. Keep the description under 100 words
3. Focus on how this table would be used in data analysis
4. Mention any key relationships or important fields
Description format: [Table Purpose] | [Key Fields] | [Common Use Cases]
"""
response = model.generate_content(prompt)
return response.text
This creates a rich knowledge base that helps the LLM understand both the technical schema and business context of each table and field.
2. Question Analyzer
The system analyzes natural language questions to identify the most relevant tables:
def analyze_question_for_tables(question, schema_data):
"""Analyze a natural language question to identify relevant tables."""
relevant_tables = {}
question_terms = set(question.lower().split())
for table_name, schema in schema_data.items():
score = 0
matched_terms = set()
# Check table name, description, and fields for relevance
# ...
if score > 0:
relevant_tables[table_name] = {
"schema": schema,
"relevance_score": score,
"matched_terms": list(matched_terms)
}
return dict(sorted(relevant_tables.items(),
key=lambda x: x[1]["relevance_score"],
reverse=True))
This semantic matching ensures only the most relevant tables are considered for query generation.
3. SQL Generator with Reflective Improvements
The core of the system converts questions to SQL and refines them through iterative reflection:
def generate_sql_query(question, schema_data, context_manager=None):
relevant_tables = analyze_question_for_tables(question, schema_data)
prompt = format_prompt_with_relevant_tables(question, relevant_tables)
# Generate initial query
response = model.generate_content(prompt)
result = json.loads(json_match.group(0))
# Apply reflective improvement
current_query = result["query"]
for i in range(MAX_REFLECTIONS):
reflection_result = reflect_on_query(question, current_query,
relevant_tables, schema_data)
if reflection_result.get("is_correct", False):
break
current_query = reflection_result["improved_query"]
result["query"] = current_query
return result
This reflection stage is critical - it allows the system to scrutinize its own work and fix potential issues before execution.
4. Robust Error Handling and Query Execution
The system includes sophisticated error handling and automatic recovery:
def execute_query_with_retries(client, question, sql_query, schema_data,
relevant_tables, max_retries=MAX_RETRIES):
attempts = 0
current_query = sql_query
while attempts < max_retries:
try:
query_job = client.query(current_query)
results = query_job.to_dataframe()
return results, None, error_history
except Exception as e:
error_message = str(e)
attempts += 1
# Try to fix the query using LLM
fix_result = fix_sql_query(question, current_query,
error_message, schema_data,
relevant_tables)
if fix_result.get("fixed_query"):
current_query = fix_result["fixed_query"]
else:
return None, "Failed to fix query", error_history
Benefits and Results
Implementing this chatbot has transformed how our organization interacts with data:
- Democratized Data Access: Non-technical users can now get answers directly from BigQuery
- Reduced Analyst Workload: Data scientists focus on complex analysis rather than basic queries
- Faster Decision Making: Business insights are available in seconds rather than days
- Improved Data Literacy: Users learn about available data as they interact with the system
- Optimized Query Performance: Generated queries follow best practices for efficiency
Technical Considerations
When building similar systems, consider these factors:
- LLM Selection: Use a technically proficient model like Gemini 2.0 that understands SQL nuances
- Cost Optimization: Implement caching for common questions and rate limiting for API calls
- Security: Ensure proper authentication and data access controls
- Iterative Refinement: Multi-step generation with feedback loops produces better results than single-pass approaches
- Error Handling: Robust retry mechanisms with intelligent fixes are essential for production use
Next Steps
Future enhancements to the system include:
- Adding conversational memory for follow-up questions
- Implementing visual explanation of query execution plans
- Extending to multi-database support beyond BigQuery
- Adding export functionality to BI tools
- Building a user feedback loop for continuous improvement
Conclusion
By combining the natural language capabilities of LLMs with the analytical power of BigQuery, we've created a tool that truly democratizes data access. This approach not only saves time but fundamentally changes how organizations can leverage their data assets.
The most exciting aspect is that this is just the beginning - as LLMs continue to improve, so will the capabilities of systems built on top of them. The future of data interaction is conversational, and that future is already here.
What challenges have you faced when trying to make data more accessible in your organization? Share your thoughts in the comments below!

Top comments (0)