
So we've created a pretty awesome Google results spider that can crawl normal results plus related video results in the last two parts. Now, we're going to extend it: let's go looking for the wiki!
WARNING: Don't ever use this spider to scrape lots of data. As of Google provides a public API that allows you to call 100 times for free, your IP will be banned if Google noticed the unusual traffic from your computer. This spider is built only for learning purposes, and it shouldn't be used in real projects. So keep that in mind, and we'll get started.
Our Goal
Okay, let me explain it. If you search Google for Python, you will see a card containing wikis of Python in the upper-right corner.
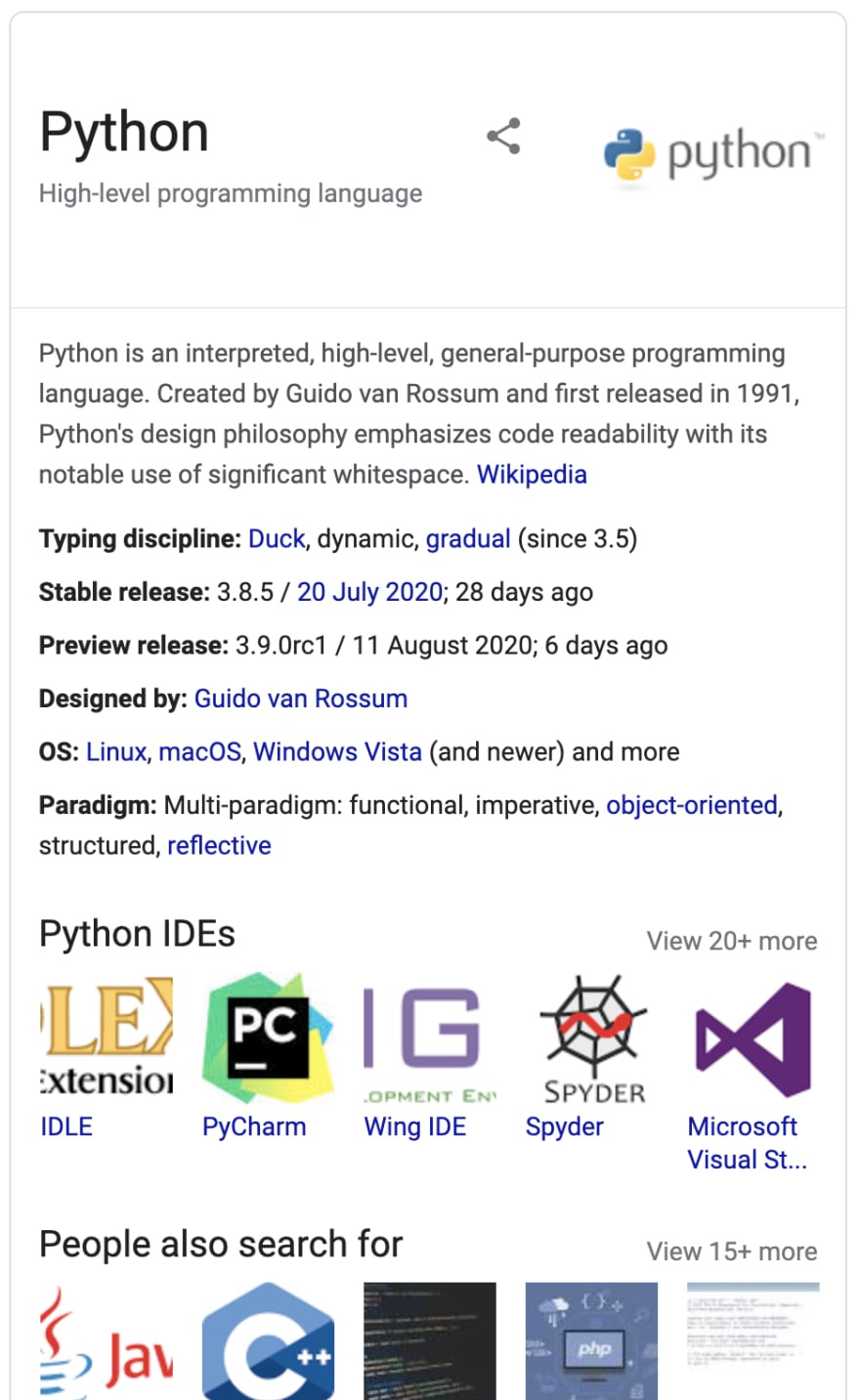
Understood? All right, then let's analyze our page as usual.
Let's Analyze!
Container
Take a close look at the source code. What's the container? Right, it's a div element with class kp-wholepage as the picture shown below.
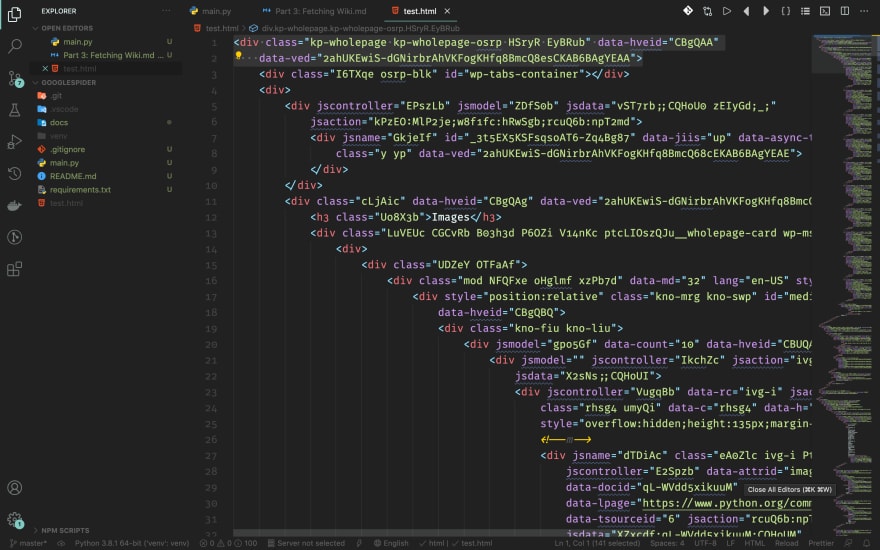
Wiki Title
Next, we'll look for the wiki's title. In our example, it's Python. It's inside a h2 element whose data-attrid is title.

Wiki Subtitle
Some wikis have subtitles, such as our example. To get it, we need to find a div with attribute data-attrid="subtitle" and get its text.
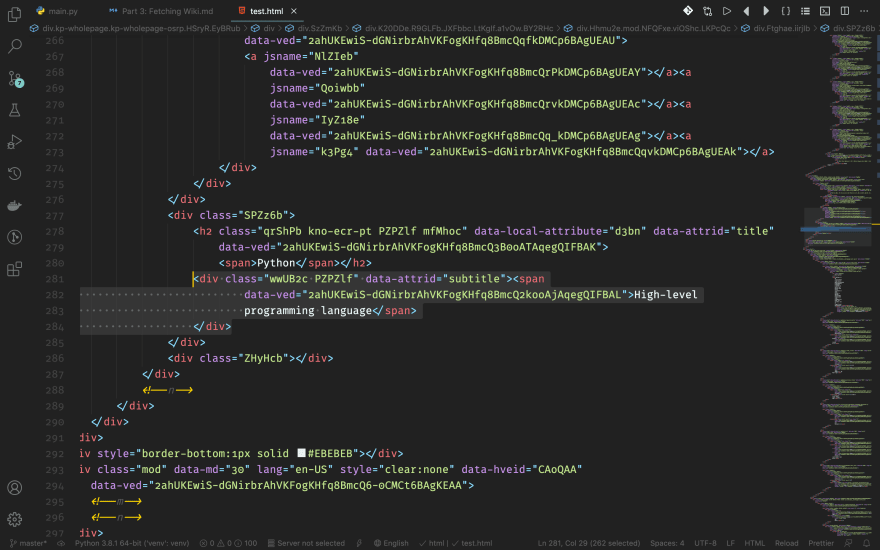
Wiki Description
Wikis also have descriptions. Its content is inside a span tag with a parent div. The div has a class called kno-rdesc.
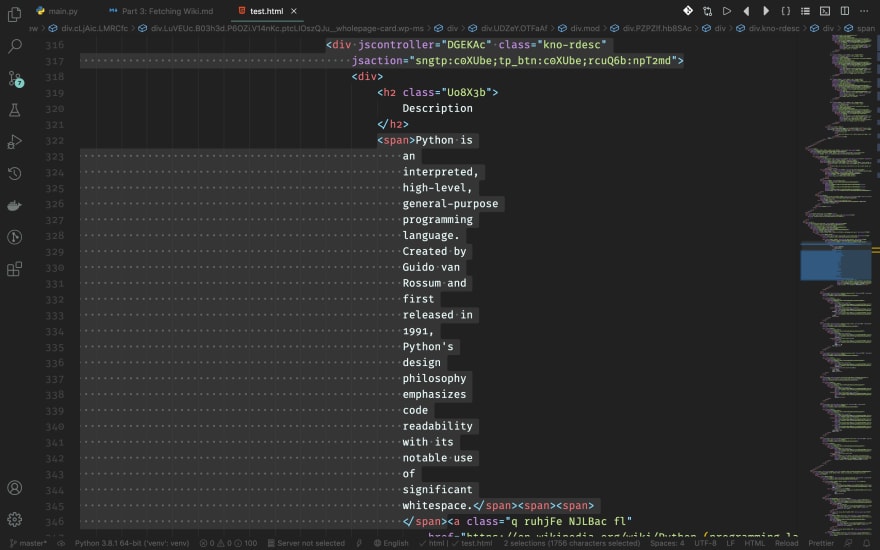
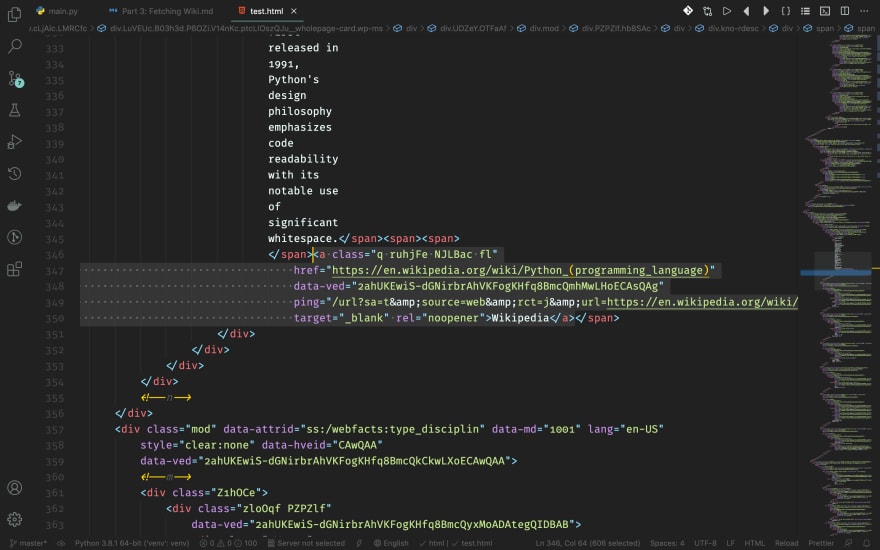
Wiki Link
Did you see that all wikis have a wikipedia link after each of their descriptions? Well, that's the link that we're going to crawl. It's right below wiki's description, and in the same parent span.
Wiki Details
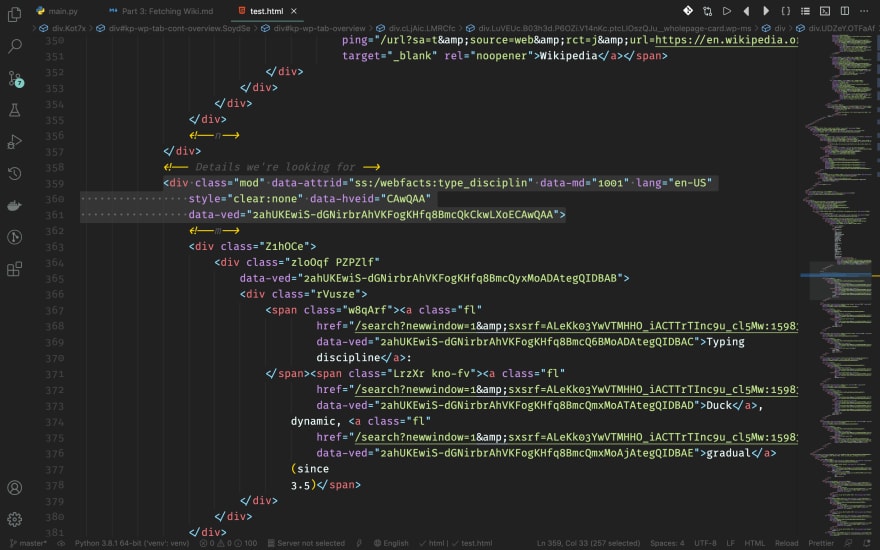
Finally, we've reached the hardest part of this post. We are going to fetch for the details as shown below.

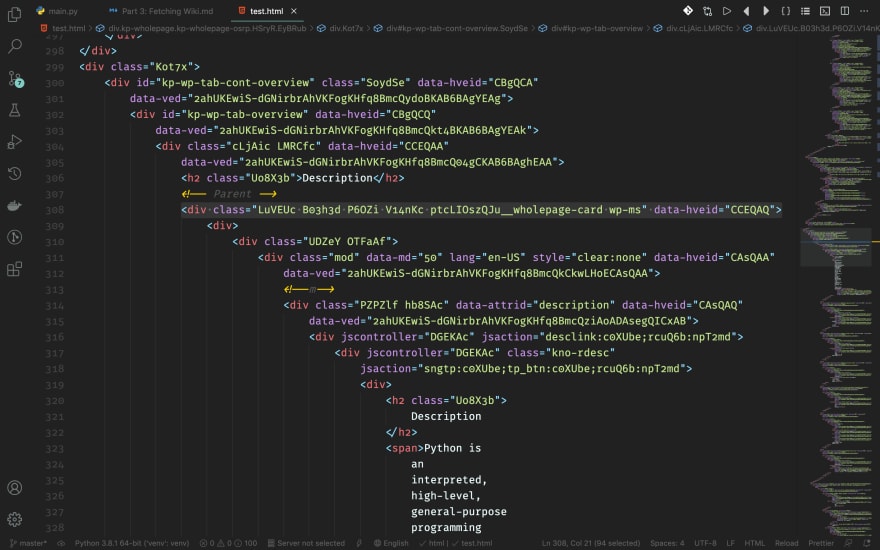
No, it's not a table, sorry. In fact, it's generated with several divs. Take a close look. Each detail is actually surrounded by a div styled with class mod. But, if you search for class="mod" in the HTML, you'll get an extra one: the description (There's one more out there, but not in the same parent). We'll just skip that using [1:]. So, to be clear, we are going to look for several divs with class mod and has a parent div with class wp-ms.
The parent:
The details that we're looking for:
Name
We also look into the details. We need to fetch for two things in order to get this thing complete: the name and the detail description. First, let's take a look at the names. It's right inside the first span element of the div. We'll strip the : part out when we code.
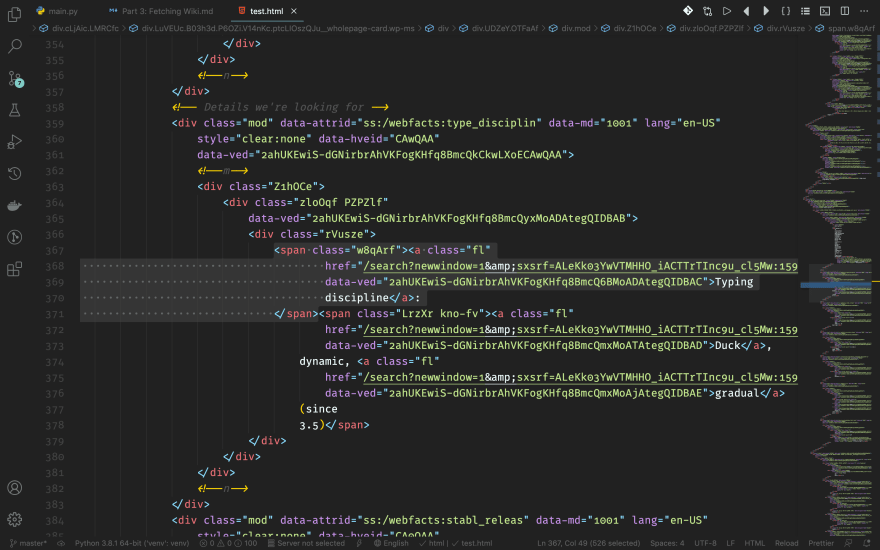
Description
Then comes the description. It's in the rest of spans of our div, except for the first one.
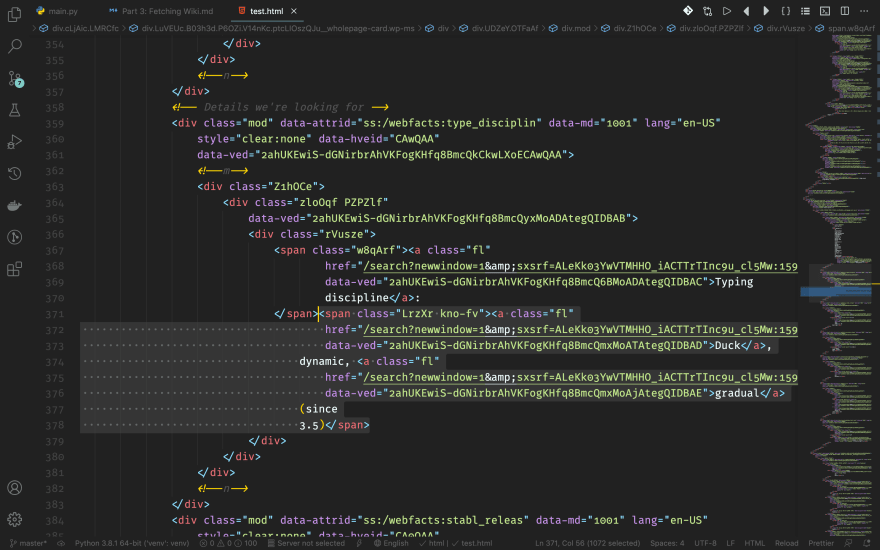
The reason I say it this way, not saying the last one, is because there might be two spans being the description together. For example, the File extension tab of our HTML:
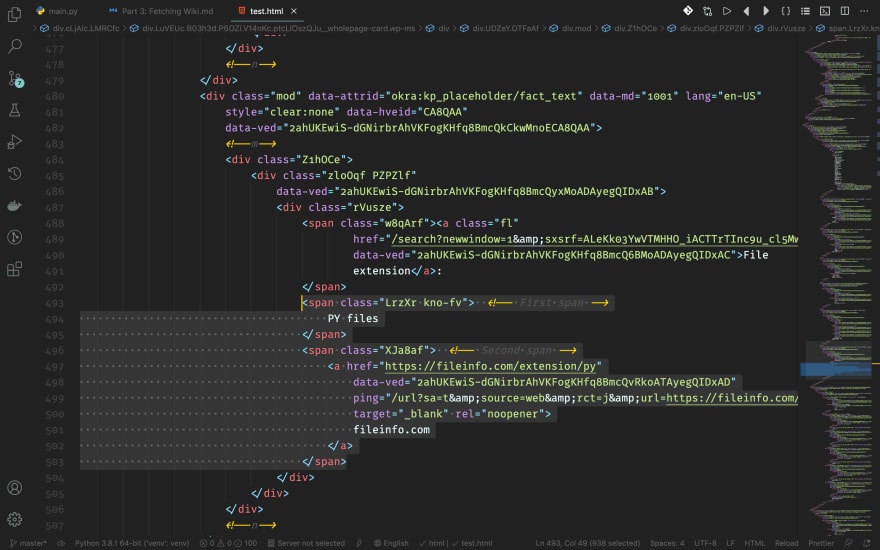
There are two spans in our sight. We need to add a for loop to keep adding spans to our target string variable.
Coding Time
All right, I guess you all are enough with analyzing stuff. Let have some fun now! Open up your favorite IDE, and let's start coding!
First, create a new method in class GoogleSpider as usual. I'll name it __search_wiki:
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
"""Search for wiki results based on the given response
Args:
response (requests.Response): The response requested to Google
Returns:
list: A list of wiki results, usually only one if found.
"""
pass
# ...
And add it to our search function:
class GoogleSpider(object):
# ...
def search(self, query: str, page: int = 1) -> dict:
# ...
video = self.__search_video(response)
result = self.__search_result(response)
wiki = self.__search_wiki(response) # <---
pages = self.__get_total_page(response)
results.extend(result)
results.extend(video)
results.extend(wiki) # <---
return {
'results': results,
'pages': pages
}
OK. We're ready to develop our __search_wiki method now! First of all, we need to create a BeautifulSoup object and get the wiki container:
class GoogleSpider(object):
# ...
def __search__wiki(self, response: requests.Response) -> list:
# ...
soup = BeautifulSoup(response.text, 'html.parser')
# Get the info container card
container = soup.find('div', class_='kp-wholepage')
# ...
And we will detect wether the container is empty or not:
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
# If the container is empty (None), then there isn't a wiki tab for the
# given response.
if container is None:
return []
Then, we will collect the details (I'm going to just paste my code here, leave a comment if you don't understand something):
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
# Title
title = container.find('h2', attrs={'data-attrid': 'title'}).text
# Subtitle
try:
subtitle = container.find(
'div', attrs={'data-attrid': 'subtitle'}).text
except AttributeError:
subtitle = None
# Description
des = container.find('div', class_='kno-rdesc').find('span').text
# The link to Wikipedia
url = container.find('div', class_='kno-rdesc').find('a')['href']
Finally, we will create the details part together. First, let's find the container (the table):
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
# Details table
try:
table = container.findAll(
'div', class_='wp-ms')[1].findAll('div', class_='mod')[1:]
except IndexError:
table = []
I've added a try-except here is that because not every result has a in-detail description table, so it might throw a IndexError while looking for the first div using [1]. If that's the case, then we will set table to [] (empty).
Then, we will loop through the table:
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
details = []
# Loop through all details
for row in table:
pass
And fetch the name:
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
details = []
# Loop through all details
for row in table:
name = row.find('span').text.strip(': ')
Here I removed : using strip. Note the whitespace! It won't work without it.
Then, we need to get the description:
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
details = []
# Loop through all details
for row in table:
# ...
# Find all spans and get their text one-by-one
detail_ = row.findAll('span')[1:]
...And the most interesting part comes. In order to get the formatted, nice-looking description even including several spans, we need to add another small loop:
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
details = []
# Loop through all details
for row in table:
# ...
# Find all spans and get their text one-by-one
detail_ = row.findAll('span')[1:]
detail = ''
# Get their text
for _ in detail_:
pass
Then, we will connect these spans together into one single string:
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
details = []
# Loop through all details
for row in table:
# ...
# Get their text
for _ in detail_:
detail += _.text + ' ' # Add a whitespace to prevent descriptions connected to each other
As it saids in the comment, you must add into another whitespace to make it working. Otherwise, you'll get the response like this:
'PY filesfileinfo.com'
If you add it, it would look like this:
'PY files fileinfo.com '
So we need to strip it again when we add it into the result dict:
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
details = []
# Loop through all details
for row in table:
# ...
details.append({
'name': name,
'detail': detail.strip()
})
And append everything into the final result and return it:
class GoogleSpider(object):
# ...
def __search_wiki(self, response: requests.Response) -> list:
# ...
result = {
'title': title,
'subtitle': subtitle,
'des': des,
'url': url,
'details': details,
'type': 'wiki'
}
return [result]
The main reason I return it as a list is because that way, you will get the same response type for all private search methods. So that way, we can use extend method to any search type to append it into the final result list.
Full Code
The full code of this tutorial until Part 3 is below.
# Import dependencies
from pprint import pprint
from urllib.parse import quote
import requests
from bs4 import BeautifulSoup
class GoogleSpider(object):
def __init__(self):
"""Crawl Google search results
This class is used to crawl Google's search results using requests and BeautifulSoup.
"""
super().__init__()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:79.0) Gecko/20100101 Firefox/79.0',
'Host': 'www.google.com',
'Referer': 'https://www.google.com/'
}
def __get_source(self, url: str) -> requests.Response:
"""Get the web page's source code
Args:
url (str): The URL to crawl
Returns:
requests.Response: The response from URL
"""
return requests.get(url, headers=self.headers)
def __get_total_page(self, response: requests.Response) -> int:
"""Get the current total pages
Args:
response (requests.Response): the response requested to Google using requests
Returns:
int: the total page number (might be changing when increasing / decreasing the current page number)
"""
soup = BeautifulSoup(response.text, 'html.parser')
pages_ = soup.find('div', id='foot', role='navigation').findAll('td')
maxn = 0
for p in pages_:
try:
if int(p.text) > maxn:
maxn = int(p.text)
except:
pass
return maxn
def __search_video(self, response: requests.Response) -> list:
"""Search for video results based on the given response
Args:
response (requests.Response): the response requested to Google search
Returns:
list: A list of found video results, usually three if found
"""
soup = BeautifulSoup(response.text, 'html.parser')
try:
cards = soup.find('g-scrolling-carousel').findAll('g-inner-card')
except AttributeError:
return []
# Pre-process the video covers
covers_ = soup.find('span', id='fld').findNextSiblings('script')[1:]
# Get the cover images
covers = []
for c in covers_:
# Fetch cover image
try:
covers.append(str(c).split('s=\'')[-1].split(
'\';var ii')[0].rsplit('\\', 1)[0])
except IndexError:
pass
results = []
# Generate video information
for card in cards:
try:
# Title
# If the container is not about videos, there won't be a div with
# attrs `role="heading"`. So to catch that, I've added a try-except
# to catch the error and return.
try:
title = card.find('div', role='heading').text
except AttributeError:
return []
# Video length
length = card.findAll('div', style='height:118px;width:212px')[
1].findAll('div')[1].text
# Video upload author
author = card.find(
'div', style='max-height:1.5800000429153442em;min-height:1.5800000429153442em;font-size:14px;padding:2px 0 0;line-height:1.5800000429153442em').text
# Video source (Youtube, for example)
source = card.find(
'span', style='font-size:14px;padding:1px 0 0 0;line-height:1.5800000429153442em').text
# Video publish date
date = card.find(
'div', style='font-size:14px;padding:1px 0 0 0;line-height:1.5800000429153442em').text.lstrip(source).lstrip('- ') # Strip the source out because they're in the same container
# Video link
url = card.find('a')['href']
# Video cover image
try: # Just in case that the cover wasn't found in page's JavaScript
cover = covers[cards.index(card)]
except IndexError:
cover = None
except IndexError:
continue
else:
# Append result
results.append({
'title': title,
'length': length,
'author': author,
'source': source,
'date': date,
'cover': cover,
'url': url,
'type': 'video'
})
return results
def __search_result(self, response: requests.Response) -> list:
"""Search for normal search results based on the given response
Args:
response (requests.Response): The response requested to Google
Returns:
list: A list of results
"""
# Initialize BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Get the result containers
result_containers = soup.findAll('div', class_='rc')
# Final results list
results = []
# Loop through every container
for container in result_containers:
# Result title
title = container.find('h3').text
# Result URL
url = container.find('a')['href']
# Result description
des = container.find('span', class_='st').text
results.append({
'title': title,
'url': url,
'des': des,
'type': 'result'
})
return results
def __search_wiki(self, response: requests.Response) -> list:
"""Search for wiki results based on the given response
Args:
response (requests.Response): The response requested to Google
Returns:
list: A list of wiki results, usually only one if found.
"""
soup = BeautifulSoup(response.text, 'html.parser')
# Get the info container card
container = soup.find('div', class_='kp-wholepage')
# If the container is empty (None), then there isn't a wiki tab for the
# given response.
if container is None:
return []
# Title
title = container.find('h2', attrs={'data-attrid': 'title'}).text
# Subtitle
try:
subtitle = container.find(
'div', attrs={'data-attrid': 'subtitle'}).text
except AttributeError:
subtitle = None
# Description
des = container.find('div', class_='kno-rdesc').find('span').text
# The link to Wikipedia
url = container.find('div', class_='kno-rdesc').find('a')['href']
# Details table
try:
table = container.findAll(
'div', class_='wp-ms')[1].findAll('div', class_='mod')[1:]
except IndexError:
table = []
details = []
# Loop through all details
for row in table:
name = row.find('span').text.strip(': ')
# Find all spans and get their text one-by-one
detail_ = row.findAll('span')[1:]
detail = ''
# Get their text
for _ in detail_:
detail += _.text + ' ' # Add a whitespace to prevent descriptions connected to each other
details.append({
'name': name,
'detail': detail.strip()
})
result = {
'title': title,
'subtitle': subtitle,
'des': des,
'url': url,
'details': details,
'type': 'wiki'
}
return [result]
def search(self, query: str, page: int = 1) -> dict:
"""Search Google
Args:
query (str): The query to search for
page (int): The page number of search result
Returns:
dict: The search results and the total page number
"""
# Get response
response = self.__get_source(
'https://www.google.com/search?q=%s&start=%d' % (quote(query), (page - 1) * 10))
results = []
video = self.__search_video(response)
result = self.__search_result(response)
wiki = self.__search_wiki(response)
pages = self.__get_total_page(response)
results.extend(result)
results.extend(video)
results.extend(wiki)
return {
'results': results,
'pages': pages
}
if __name__ == '__main__':
pprint(GoogleSpider().search(input('Search for what? ')))
I've also uploaded all the tutorial code to GitHub, so check that out if you want. Click on this link to see the code for this tutorial until Part 3.
Conclusion
So that's pretty much all for today, and I hope it will help you. Leave a comment below for either suggestions or questions for this tutorial, and see you next time!

Top comments (2)
Is it ethical to crawl Google Search? Cause they have disallowed all user-agents for scrapping
/searchpath in robots.txt.Generally speaking, it's fine as long as you don't scrape for a lot of data. That's why I put the warning at the beginning of this post.