
Originally posted at Serverless on September 16th, 2019
Functions-as-a-Service (FaaS) offerings such as AWS Lambda are key components in modern Serverless application stacks as they receive and process the event data generated by other cloud services such as storage buckets or databases.
AWS announced AWS Lambda, their FaaS service, back in late 2014 alongside an S3 integration which made it possible to react on changes happening in S3 buckets. The primary use cases for AWS Lambda back then was to streamline the data processing pipelines many companies operate to crunch through the data stored in such buckets.
The announcement of AWS API Gateway support for AWS Lambda finally made it possible to build 100% serverless web applications, removing the need to run and maintain a dedicated web server which processes incoming requests and serves responses. Since then web applications are the top use-case for serverless applications.
Due to the growing interest in serverless web applications AWS introduced another type of Lambda function which is called Lambda@Edge. With Serverless Framework v1.52.0 we’re adding native support for Lambda@Edge functions.
In this post we’ll take a deeper dive into serverless web applications to see how they can benefit from Lambda@Edge functions. Before we get ahead of ourselves and talk about Lambda@Edge let’s recap what a typical serverless web application consists of.
Building serverless web applications
Roughly speaking web applications can be broken down into 2 parts: The frontend and the backend. Although serverless web applications are composed of several different cloud services one can still separate them into those 2 parts.
Let’s take a look at the different pieces a modern, serverless web application is made of.
The frontend
The frontends main purpose is to serve the .html, .css and .js files alongside other static assets such as images which will be rendered by the consumer (usually the web browser) to display a UI our users can interact with.
While our browser renders the static content it will also use our front ends JavaScript code to interact with our serverless backend (more on that in a minute).
When using AWS to serve our frontend to our users we could use AWS S3 which is a storage solution to host our static assets and AWS CloudFront, a CDN service, to automatically distribute such assets in data centers all over the world.
One might be asking, why CloudFront is necessary in this setup. Isn’t it enough to upload all the files to the S3 bucket and call it a day?
Usually when a user would access our website, his request would be routed to our S3 bucket which in turn serves our public assets (such as .html, .css and .js files). While this initial setup works just fine, it's often a better idea to cache content which is infrequently changed. That's where AWS CloudFront comes in. With CloudFront we can set up a caching layer in front of our S3 bucket. This cache is distributed around the globe. User's won't download our assets from S3 but rather pull them from a CloudFront location nearby, which is way faster compared to an S3-only solution.
The backend
Having the frontend up and running, it’s time to take a quick look at a potential serverless web application backend. Depending on the use cases we usually need an API Gateway, data processing capabilities and a data storage solution.
To satisfy such requirements, serverless web applications are usually built with AWS API Gateway which serves as the API Gateway, AWS Lambda to process the incoming event data and AWS DynamoDB which is used as the persistence layer (other DB solutions are available as well).
When the user interacts with our web application frontend and wants to update his password, for example, a request will be sent from the frontend to API Gateway which is the entrypoint of our backend. API Gateway translates this request into an event which triggers our Lambda function. Such Lambda function will then process the event data and store the updated password in the DynamoDB table. Once done, a response is generated and sent back to the user via the API Gateway.
As previously stated this setup is a very typical one for serverless web applications.
Looking at the full stack consisting of frontend and backend one might ask if it’s truly necessary to perform a full roundtrip from the frontend to the backend and back again for every single user request.
Imagine you’re operating a social networking site and you want to redirect mobile users to a dedicated “lite” version of your site which serves fewer content and hence loads faster. Wouldn’t it be a waste of time and resources to let the request travel all the way to your backend which detects that your user is using a mobile device and issues a redirect to your optimized mobile web app. Wouldn’t it be better to process that request “at the edge” without hitting the backend at all?
That’s where Lambda@Edge comes in!
Lambda@Edge
Lambda@Edge is a compute offering by AWS which makes it possible to deploy AWS Lambda functions to edge locations which are served by CloudFront. Lambda@Edge functions are triggered by CloudFront events such as incoming requests or outgoing responses and can use this event information to rewrite such requests and responses (in our case inspecting the device type to issue a redirect when it’s a mobile device).
Lambda@Edge functions are quite similar to regular AWS Lambda functions. In fact they are normal AWS Lambda functions which need to adhere to a few limitations: Only versioned Lambda functions can be turned into Lambda@Edge functions Lambda@Edge functions can have a maximum memory size of 128 MB Lambda@Edge functions can have a maximum timeout of 5 seconds The Lambda@Edge handler response is different compared to normal Lambda functions
That being said there’s nothing new which needs to be learned in order to leverage Lambda@Edge functions. In fact the Serverless Framework v1.52.0 takes care of the heavy lifting for you. The only thing you need to do is to provide the function code and setup the corresponding cloudFront event in your serverless.yml file.
Curious how this looks like? Let’s take a look at an example.
Example
Let’s implement our example of redirecting mobile users to a “light” web app URL without doing a full round trip from the frontend to the backend and back again.
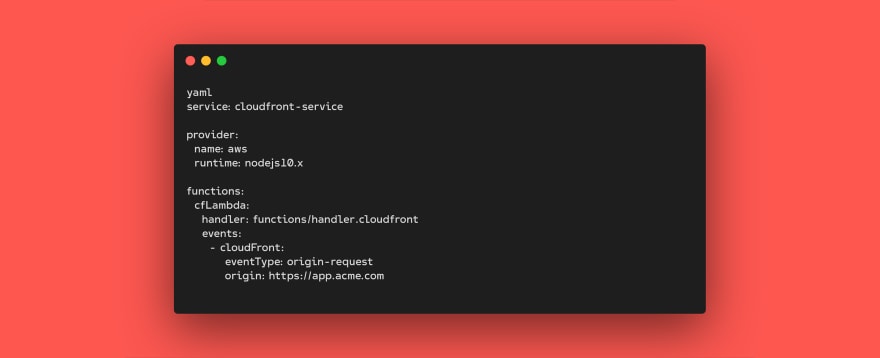
Let’s start with our serverless.yml file and turn our regular Lambda function into a Lambda@Edge function. Doing this is as easy as adding the cloudFront event to the events definition and setting the correct configuration parameters:
Here you can see that we’ve added the cloudFront event with an eventType configuration of origin-request and an origin configuration of https://app.acme.com. This configuration tells the Serverless Framework that we want to invoke our cfLambda function every time a request is sent to the https://app.acme.com origin.
Next up we need to write the function logic to redirect mobile users to our “lite” version of our web application.
This functionality is triggered every time a request is routed through our CloudFront distribution. Once this happens we take a look into the request headers to see if it’s a mobile user. If that’s the case we prepend the /lite string to our uri and return the request.
That’s it. We’re now ready to deploy our Lambda@Edge function. As per usual, deploying this service is a simple as running serverless deploy.
Note that the deployment might take a while since AWS will setup a CloudFront distribution for you behind the scenes and replicates your Lambda function across the globe.
Once done you should see the CloudFront endpoint in your deployment summary. If you visit this endpoint with a mobile device you’ll be redirected to the “lite” version of your webapp!
A note about removals
When you’re done with testing you might want to remove the service via serverless remove. Note that the removal also takes a little bit longer and won't remove your Lambda@Edge functions automatically. The reason is that AWS has to cleanup your functions replicas which can take a couple of hours. Removing the Lambda functions too early would result in an error.
The solution for this problem right now is to manually remove the Lambda@Edge functions via the AWS console after a couple of hours. You might want to automate this process with a script which issues AWS SDK calls to streamline this cleanup process.
Conclusion
AWS Lambda@Edge is a great way to run function code in edge locations which are near to the user and therefore typically offer lower latency.
Lambda@Edge functions are regular, “trimmed down” Lambda functions which can read and modify the request and response data. This makes it possible to e.g. intercept incoming requests and return a response immediately without passing the data through to the backend services. Typical Lambda@Edge uses cases include rewriting of response URLs based on device types or IP addresses, identifying crawlers and serving static, pre rendered assets, on-the-fly content compression or authentication header manipulations.
With Serverless Framework v1.52.0 we’re adding native support for Lambda@Edge functions via the cloudFront event. Every Lambda function can easily be turned into a Lambda@Edge function and deployed via the familiar serverless deploy command. You can read more about the cloudFront event type in our cloudFront event documentation.
We hope that you enjoy this new functionality. What do you think about Lambda@Edge? How are you planning to use it? Let us know via @goserverless on Twitter or leave a comment below!
Originally published at https://www.serverless.com.

Top comments (0)