
DynamoDB is increasingly gaining the spotlight as a performant, low-cost and serverless NoSQL Database.
For good reason! It's a fast, highly available, and serverless key-value & document database that is fully managed.
Meaning: Once you understand DynamoDB concepts, developers enjoy increased development speed by letting DynamoDB handle the things that typically time — database scaling, availability, etc.
In this post we're going cover the basics of DynamoDB: how it models data & access patterns, tips on when it's best to be used vs. using something like SQL, and how to extend access patterns across more of your data using something called Secondary Indexes.
What's NoSQL?
NoSQL means simply: a database that doesn't typically follow the SQL style of a tabular, relational database, and the SQL language of accessing and querying data that data.
In comparison, Relational Databases (MySQL, PostgreSQL, etc.) do most of the the query processing for you—however you choose to define it— and right at the data source (e.g. calculating total count of users, filtering of data, etc.).
For NoSQL, it goes in reverse: a “query first” approach to identify the queries your application needs before you design the database schema.
What this means for the developer: you need to understand you data access patterns beforehand to fully utilize DynamoDB effectively, or you will run into issues later.
Tip: If you are unsure how your access patterns are going to be and that they might change in the future, it might be better to use a SQL type of database.
What is DynamoDB?

DynamoDB is a popular NoSQL database provided by Amazon Web Services that acts as a key-value & document store that provides data with millisecond performance at scale.
Basically, it's super fast, serverless, almost fully managed, and works at any scale.
Some of the primary benefits of DynamoDB are:
- Performance — S*ingle digit* millisecond response times at any scale
- Serverless — With no servers to manage, DynamoDB takes all the headache away of managing and maintaining database servers.
- Consistency — ACID transactions for industries like business & finance. If you put data into it, it's immediately available, and you can assure it'll never get lost (barring disasters, of course).
- Widely adopted: It used by many leading tech companies today, from AirBnB to Samsung, and more.
DynamoDB Pricing & Capacity
DynamoDB pricing exists in two modes: provisioned and on-demand.
- Provisioned is more cost effective if you have consistent workloads, with auto scaling capability.
- On-Demand Takes care of managing capacity for you, and you only pay for what you consume. You should start with this, especially for personal projects.
DynamoDB Basics - Tables and Keys
Data is organized in Tables, that have a collection of items set according to a schema.
Table: a collection of items
Item: collection of attributes (similar to a row or records in databases or spreadsheets).
Let's imagine we have a table of users that is a summary of game scores. The table below has games they played, and some stats like Top Scores and date, and Wins and Losses. GameScores is the table, and each row below is an item:
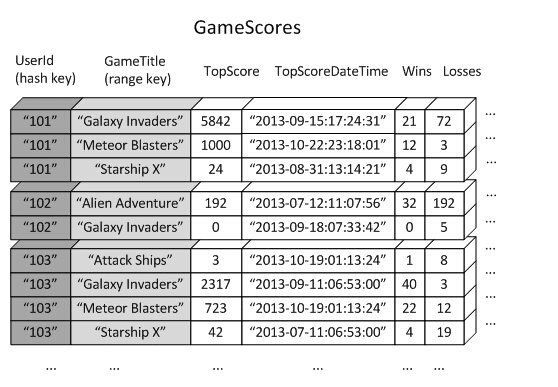
In order for us to setup a table, we need to tell DynamoDB what our partition key will be, and in effect, what our data access patterns will be.
This is because DynamoDB stores and accesses data according to this value. This is key to understanding why it's important to understand your access patterns getting started—if they change, you might finding yourself having to create a new table and moving over your stored data!
Partition & Composite Keys
When you make a table, each table must have a primary key that uniquely identifies each item in a table (this is how DynamoDB knows where to find an item). A primary key can be one of two items:
- Partition Key: A simple key that is one attribute (like userID). (also called a hash key, since it is used internally in Dynamo as output from the hashing function)
-
Composite Key: In the GameScores table above, a user can have multiple forum posts. To make each item unique, we add a sort Key together with the partition key that will make each item unique in the table. This is called the composite key, where together with the sort key, all items are unique.
-
**Example: Pulling all scores with
userID101, and then sorting by theGameTitleto get all high scores for all games.
-
**Example: Pulling all scores with
Accessing data in DynamoDB
You can access data with two primary operations:
- A query operation returns items based on a particular key (
userID, etc.). This is the primary, recommended method. It's fast, affordable, and is how DynamoDB should generally be used. - A scan looks through the entire table for items based on set attributes or filter, and returns all the items that match the attributes.
- Tip: This can get expensive and is generally not recommended, as your charges will be higher, scans are slower, and scan the entire table.
Expanding your Access Patterns with Secondary Indexes
In the table above we can only query forum posts by a user and sort by a date, but that's it. What if we want to expand further? For example, in the image above, what if we wanted to get each userID sorted by TopScoreDateTime?
With Dynamo we can use something called Secondary Indexes.
A secondary index allows applications to benefit from having one or more secondary keys, to expand your access to your data with attributes that are different from your primary key.
Secondary Indexes come in two flavors: local and global.
A local secondary index (LSI for short) allows you to have an alternate sort key *for your table, while having the *same primary key.
- For our GameScores table, if we have an LSI to get
TopScoreDateTime, our LSI would have theUserIdbe the same primary key, and the second sort key would beTopScoreDateTime, which would allow us to a user by sorted Top Score datetimes. - You can only have one LSI on a table, and only 10GB total table size.
- You can only add an LSI when you create a table!
What about applications that might need many different queries on a table?
A global secondary index or GSI allows you to have an infinite amount of partition and sort keys on your table, at the cost of data replication. This means:
- You pay for the extra replicated data.
- But you can have multiple access patterns on the same table, up to 20.
- GSIs are only eventually consistent, meaning — you may not have access to the data on the GSI right after you write to a table. This is often done within a second, however.
- Example: In the table above, what if we wanted to query
TopScorebyGameTitle? We would create a new GSI calledGameTitleIndexwithGameTitleas the primary key andTopScoreas the sort key. When we query it, we can then see whichUserIdgot the top score across all games.
Conclusion
This post should help you understand what DynamoDB is, what makes it special, and understand how DynamoDB structures its data and how to query it.
We didn't cover other topics like DynamoDB Accelerator for things like caching, or Streams for things like triggering lambda function after data entry. Those will be covered other posts, along with relational data.
I hope this post was beneficial in understanding DynamoDB!
I help companies with cloud and mobile software, so if you have questions or need help, please feel free to reach out.
Cheers!
Stephen





Top comments (0)