
"Where's Waldo?" game is very well known by everyone, in this post I'll explain how to make such game with Azure Custom Vision and LEGO minifigures. This was my weekend project, feel free to recreate it and while learning how Azure Custom Vision works you can also entertain your child to help you out with it.
I'll be using Chewbacca LEGO minifigure (nicknamed Chewie) that AI should detect in image among other minifigures.

Board where Chewbacca will be hiding can be seen on the following image, it consist of 49 different LEGO minifigures.

In order to follow next steps you should have an Azure account, if you don't have one you can create it here.
When you sign in with your Azure account into Custom Vision (www.customvision.ai) you'll see a page that shows your projects.
Clicking on "New project" will ask you to enter projects name, you can add description and you need to select resource.

If you are creating a new resource, you should define resource name, subscription, resource group, what kind of resource is that (CognitiveServices), location and pricing tier.

For new resource group you should just define name and location.
After you fill this in you can select type and domain for your new project.
Image classification is used when you want to classify the whole image, which object is represented the most in the image. Object detection is used to find location of content in the image and this is what we need for this project.
For domain we'll use General domain which is explained by Microsoft as "Optimised for a broad range of object detection tasks. If none of the other domains are appropriate, or you are unsure of which domain to choose, select the Generic domain". Feel free to read more about the domains here.

Once project is created you'll be able to see project page that is currently empty and gives you option to upload images to train your model.

I took several images of the LEGO Chewbacca minifigure from different angles. I also made a little trick, as you can see on the images below, I've placed minifigure on top of the LEGO catalogue and I switched pages for each image. That way model will be able to distinguish better what is minifigure and what is background in the image.

When images are uploaded you can manually tag them. UX is really nice here and you'll notice that tagging tool will suggest a frame around objects it detects. For first tag you'll need to enter a name, afterwards you can select it for other images. Adjusting frame to fit the minifigure is super easy.

We prepared the images and we can now start the training, in this case quick training. Advanced training should be used on advanced and challenging datasets.

When training is finished you'll see information about it:
- Precision: this number will tell you: if a tag is predicted by your model, how likely is that to be right
- Recall: this number will tell you: out of the tags which should be predicted correctly, what percentage did your model correctly find
- mAP: mean average precision will tell you: the overall object detector performance across all the tags

Quick test I made with the image of the whole board showed me that some objects were identified as target minifigure but with really low precision (20%). Dataset I made was really small number of images, so I was not surprised and I expected to see something like this.

Predictions allows you to see images that were used for prediction and here you can go into images and correctly tag them.
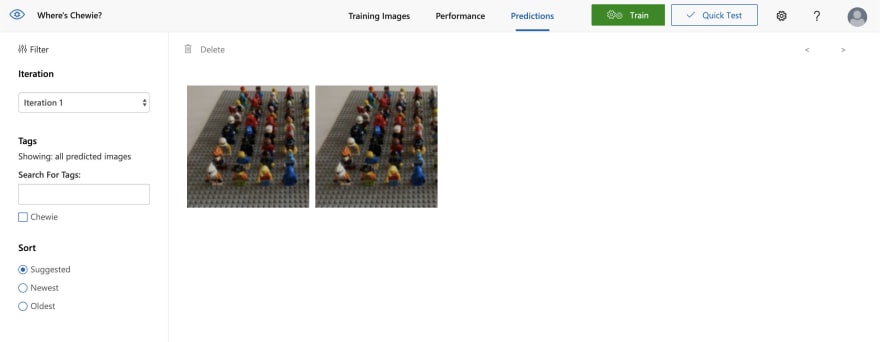
I fixed predictions several times and added much more images in my dataset. Once everything is in place this is quick and simple to do. After few iterations of my model I tried with new image (that Custom Vision model haven't seen yet) and it successfully found the Chewie with accuracy 40.8%!

Accuracy of the model can be improved further with adding more images to the data set, by using advanced training, etc. In my case I was happy with the result since this is what I aimed for: "Where's Waldo"-like game.
Thanks for reading!

Top comments (0)