
Conteúdo do tutorial
- Da teoria à prática: criando um recomendador de livros com IA
- Configurando o ambiente: ferramentas e recursos necessários
- Do prompt à API: desenvolvendo o motor de recomendações
- Desenvolvendo a interface web: simplicidade e rapidez com Gradio
- Elevando o projeto: implementação em JavaScript
Da teoria à prática: criando um recomendador de livros com IA
O primeiro conteúdo que vi sobre desenvolvimento pra uso de IA foi este curso gratuito de engenharia de prompt. Em um dos tópicos, o curso mostra como construir um chatbot simples. Nesse exercício, eu fiz um chatbot de recomendação de livros, já que as minhas maiores conversas com IA são pra descobrir autores que possam me interessar.
Nos últimos dois meses, tenho trabalhado desenvolvendo aplicações que usam IA pra resolver problemas. Precisei aplicar técnicas mais avançadas, como RAG e embeddings. Mas a ideia do recomendador de livros ficou na minha cabeça.
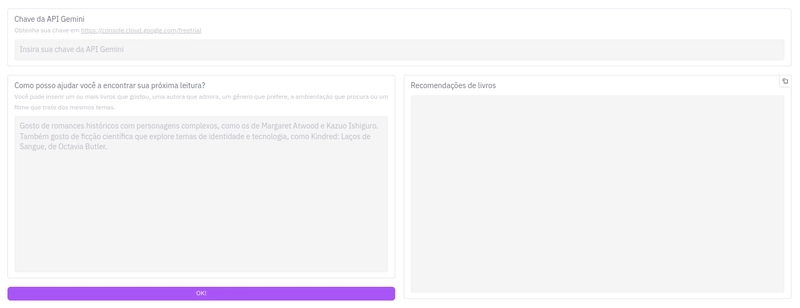
Assim, neste tutorial, vamos criar uma aplicação web simples que utiliza um modelo de linguagem de grande escala (LLM, ou large language model) para recomendar livros para a usuária com base no que ela deseja ler. Para isso, vamos usar Python puro.
Configurando o ambiente: ferramentas e recursos necessários
Se você quiser apenas rodar a aplicação e ver como ela funciona, pode acessar o repositório. As instruções estão no README.md.
No entanto, se preferir seguir o tutorial para fazer sua própria versão da app, é necessário:
- instalar o Python e
- criar uma chave da API Gemini.
A escolha do Python é óbvia: Python é a linguagem com o ecossistema mais extenso voltado pra IA [x]. Além disso, é notadamente intuitiva, com sintaxe fácil de entender e, portanto, bastante acessível para iniciantes.
Optar por usar uma API da Google já não é tão óbvio. Eu escolhi a Gemini API da Google porque ela oferece um limite alto pra teste gratuito sem a necessidade de inserir um cartão de crédito. Mas é importante ter em mente que existe um motivo pelo qual é gratuito.
⚠️ Lembre-se: Se você não paga pelo produto, você é o produto.
Eu até tentei rodar um modelo offline com Ollama, mas meu computador pessoal tem 4GB de RAM, e obviamente não rolou. Usar a API da Google não é o ideal mas, pra este tutorial, no qual não vamos compartilhar informações sensíveis, vai ter que servir.
Do prompt à API: desenvolvendo o motor de recomendações
A vantagem do Python fica aparente na primeira página da documentação da Gemini API. Todos os modelos que testei têm clientes Python pra facilitar a comunicação. Usar um modelo é simples assim:
from google import genai
client = genai.Client(api_key="YOUR_API_KEY")
response = client.models.generate_content(
model="gemini-2.0-flash",
contents="Em um parágrafo, por favor, explique por que usar Python para desenvolver aplicações que usam IA.",
)
print(response.text)
Rodando o código (no prompt do interpretador interativo Python):
Python se tornou a linguagem predominante para desenvolvimento de IA por diversas razões. Sua sintaxe clara e legível simplifica a escrita e a compreensão do código, acelerando o desenvolvimento. A vasta gama de bibliotecas e frameworks especializados, como TensorFlow, PyTorch, Scikit-learn e Keras, oferece ferramentas poderosas para aprendizado de máquina, processamento de linguagem natural, visão computacional e outras áreas da IA. Além disso, a grande e ativa comunidade Python fornece suporte abrangente, tutoriais e recursos, tornando o aprendizado e a resolução de problemas mais fáceis. A portabilidade de Python e a compatibilidade com diferentes sistemas operacionais também contribuem para sua popularidade, permitindo que os desenvolvedores implantem seus modelos de IA em diversas plataformas.
Vamos criar uma função que utilize a mesma lógica para solicitar recomendações de livros.
from google import genai
def get_book_recs(key: str, prompt: str) -> str:
client = genai.Client(api_key=key)
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=prompt
)
return response.text
if __name__ == "__main__":
import os, sys
key = os.environ.get("GOOGLE_API_KEY")
prompt = sys.argv[1] if len(sys.argv) > 1 else "Recomende livros de ficção científica"
print(get_book_recs(key, prompt))
📌 Ponto importante: A função que nos interessa é
get_book_recs, que recebe uma chave (string) e um prompt (string), instancia um cliente para se comunicar com a API da Google e, por fim, retorna conteúdo (string) usando o modelogemini-2.0-flash(no momento, gratuito).
O código que vem depois, iniciado pela cláusula de guarda if __name__ == "__main__":, permite que o script seja executado diretamente. Para rodar a função get_book_recs, o script busca a chave em uma variável de ambiente e, em seguida, recebe o prompt da linha de comando.
Se salvarmos o script acima em um arquivo .py (exemplo: suggestions.py), podemos executá-lo da seguinte forma:
export GOOGLE_API_KEY="SUA_CHAVE_AQUI"
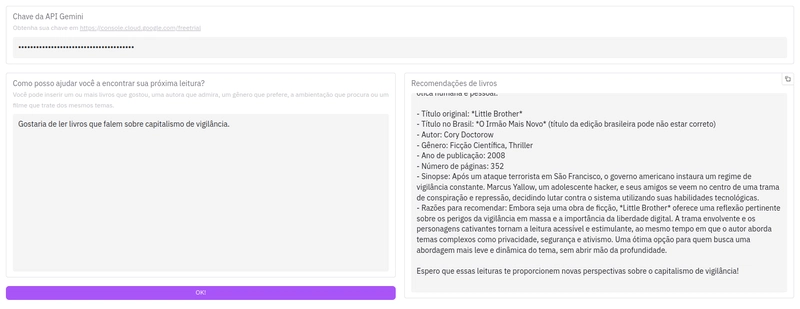
python suggestions.py "Gostaria de ler livros que falem sobre capitalismo de vigilância."
A resposta:
Com certeza! O capitalismo de vigilância é um tema crucial e há diversos livros excelentes que o exploram sob diferentes perspectivas. Aqui estão algumas recomendações, organizadas para ajudar você a escolher por onde começar:
Livros Fundamentais:
- A Era do Capitalismo de Vigilância: A Luta por um Futuro Humano na Nova Fronteira do Poder (The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power), de Shoshana Zuboff: Este é considerado a obra seminal sobre o assunto. Zuboff cunhou o termo "capitalismo de vigilância" e explora profundamente como empresas como Google e Facebook transformaram a experiência humana em dados para lucro, erodindo a autonomia individual e as bases da democracia. É um livro denso, mas essencial para entender o tema em profundidade.
Livros Mais Acessíveis e Introdutórios:
- O Que Você Não Sabe Faz um Estrago: O Que Todo Mundo Precisa Saber Sobre Privacidade e Segurança de Dados (Data and Goliath: The Hidden Battles to Collect Your Data and Control Your World), de Bruce Schneier: Embora não use o termo "capitalismo de vigilância" explicitamente, Schneier oferece uma análise clara e acessível sobre como os dados são coletados e usados por governos e empresas, e os impactos na privacidade e na segurança.
- Como as Democracias Morrem (How Democracies Die), de Steven Levitsky e Daniel Ziblatt: Este livro não foca exclusivamente no capitalismo de vigilância, mas oferece um contexto importante sobre como a manipulação da informação e a polarização política, amplificadas pelas plataformas digitais, podem minar as instituições democráticas.
Livros com Foco em Aspectos Específicos:
- Nada é Grátis: Como o Vale do Silício Engana para Controlar Seu Dinheiro e Sua Vida (Nothing Is Free: How Silicon Valley Manipulates Us and Bankrupts America), de Robert Bryce: Uma crítica contundente ao modelo de negócios do Vale do Silício, argumentando que a promessa de serviços "gratuitos" esconde um custo alto em termos de privacidade, dados e impacto social.
- Permanent Record, de Edward Snowden: Embora seja uma autobiografia, o livro de Snowden oferece um relato em primeira mão sobre a extensão da vigilância governamental e como as empresas de tecnologia colaboram com essa vigilância.
Outras Recomendações:
- Vigilância Líquida (Liquid Surveillance), de Zygmunt Bauman e David Lyon: Uma análise mais teórica sobre a natureza da vigilância na sociedade contemporânea, explorando como ela se tornou fluida, onipresente e difícil de resistir.
Dicas para Escolher:
- Se você quer uma introdução geral ao tema: Comece com "O Que Você Não Sabe Faz um Estrago" ou "Nada é Grátis".
- Se você quer uma análise profunda e abrangente: "A Era do Capitalismo de Vigilância" é a escolha certa, mas esteja preparado para uma leitura mais densa.
- Se você está interessado nas implicações políticas e democráticas: "Como as Democracias Morrem" oferece um contexto valioso.
- Se você quer uma perspectiva em primeira pessoa sobre a vigilância governamental: "Permanent Record" é uma leitura fascinante.
Recursos Adicionais:
- Artigos e ensaios: Além dos livros, muitos autores e acadêmicos escrevem artigos e ensaios sobre o capitalismo de vigilância. Procure por publicações como The Guardian, The New York Times, Wired e revistas acadêmicas especializadas em tecnologia e sociedade.
- Documentários: Documentários como "O Dilema das Redes" (The Social Dilemma) na Netflix oferecem uma introdução visual e impactante ao tema.
Espero que essas recomendações sejam úteis! Se tiver mais alguma pergunta, pode perguntar.
A resposta foi bastante informativa, mas repare que o modelo recomendou 6 livros, 3 fontes pra pesquisa de artigos e 1 documentário (que, aliás, é incrível). Além disso, o modelo se colocou à disposição para continuar a conversa. Tanto as informações adicionais quanto o formato de chat saem do escopo da aplicação que estamos tentando construir.
Pra delimitar melhor o que o modelo deve responder, vamos prover instruções adicionais. Estas instruções não serão visíveis para a usuária, mas acompanharão todas as requisições que forem feitas.
# contents.py
INSTRUCTIONS = """
Preciso que você me ajude a encontrar minhas próximas leituras, fazendo recomendações exclusivamente de LIVROS DE FICÇÃO OU NÃO-FICÇÃO de acordo com meu gosto literário. O tom da nossa conversa pode refletir o tipo de livro que eu quero ler. Assim, por exemplo, se eu pedir recomendação de livros divertidos, você pode ser engraçadinha e irreverente. Se, ao contrário, eu solicitar recomendações de livros densos ou intelectuais, você pode ser mais séria e profunda em suas reflexões.
A seguir, vou mencionar alguns dados sobre meus gostos, como livros que já favoritei, autoras preferidas, gêneros que mais leio, `vibe` que estou procurando, temas pelos quais tenho interesse etc. Você deve levar isso em consideração para sugerir três LIVROS PUBLICADOS que se encaixem no meu perfil. ATENÇÃO: NÃO RECOMENDE DOCUMENTÁRIOS, FILMES, SÉRIES OU QUALQUER OUTRA MÍDIA QUE NÃO SEJA LIVRO.
As recomendações devem considerar:
1. O estilo literário que aprecio (ex: mais denso, leve, filosófico, humorístico, etc.)
2. O tipo de narrativa ou estrutura que prefiro (ex: linear, não linear, com múltiplos pontos de vista, etc.)
3. Os temas ou tópicos de que gosto (ex: fantasia, mistério, drama psicológico, questões sociais, etc.)
4. O tom da obra (ex: otimista, melancólico, sombrio, etc.)
Por favor, seja criativa e forneça uma explicação breve para cada recomendação, destacando o que faz com que o livro se encaixe no meu perfil. O formato de cada recomendação DEVE ser exatamente assim:
- Título original: [Nome original do livro no idioma de publicação]
- Título no Brasil: [Se você não tiver certeza absoluta sobre o título oficial no Brasil, informe-o, mas também inclua a informação de que o título da edição brasileira pode não estar correto.]
- Autora: [Nome da autora]
- Gênero: [Gênero literário]
- Ano de publicação: [Ano]
- Número de páginas: [Número de páginas]
- Sinopse: [Breve resumo do livro]
- Razões para recomendar: [Explicação do porquê o livro é uma boa escolha para mim]
Você pode terminar a interação com uma mensagem de despedida, mas não precisa se oferecer para responder mais perguntas, porque o objetivo é apenas fornecer as recomendações de livros.
Importante:
1. Nunca use o termo `chick-lit`. Este é um termo pejorativo e sexista para se referir a livros escritos por mulheres e voltados para uma parcela do público feminino. Prefira o termo `romance contemporâneo`, quando necessário.
2. Recomende apenas obras que existem de verdade e foram publicadas.
3. Verifique se suas recomendações são APENAS DE LIVROS, não de documentários ou outras mídias.
4. Não presuma conhecer os títulos das edições brasileiras a menos que tenha absoluta certeza. É melhor admitir incerteza do que fornecer informações incorretas.
5. NUNCA traduza literalmente o título original para criar um suposto "título brasileiro".
Obrigada por me ajudar a encontrar minha próxima leitura!
"""
🔍 Observação: Eu não cheguei nas instruções acima de primeira. Ao contrário, fui testando e refinando o prompt pra tentar minimizar imprecisões. A engenharia de prompt tem um impacto muito maior no resultado que o modelo utilizado. Por isso, as instruções acima são essenciais pra controlar e até mesmo formatar a resposta.
Por ora, precisamos alterar o arquivo principal, suggestions.py, para usar as instruções adicionais.
from google import genai
from contents import INSTRUCTIONS # Importa as instruções
def get_book_recs(key: str, prompt: str) -> str:
client = genai.Client(api_key=key)
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=f"{INSTRUCTIONS}\n{prompt}" # Usa as instruções com o prompt fornecido
)
return response.text
if __name__ == "__main__":
[...]
Rodando o script novamente:
Perfeito! Preparada para mergulhar de cabeça nos meandros do capitalismo de vigilância? Segue uma seleção de livros que vão te fazer repensar cada clique, curtida e pesquisa online:
- Título original: The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power
- Título no Brasil: A Era do Capitalismo de Vigilância: A Luta por um Futuro Humano na Nova Fronteira do Poder
- Autora: Shoshana Zuboff
- Gênero: Não-ficção, Sociologia, Economia
- Ano de publicação: 2019
- Número de páginas: 691
- Sinopse: Zuboff explora o surgimento do capitalismo de vigilância, um novo tipo de capitalismo que monetiza dados pessoais extraídos de nossas vidas cotidianas, muitas vezes sem nosso conhecimento ou consentimento. Ela argumenta que essa prática representa uma ameaça fundamental à autonomia individual e à democracia.
- Razões para recomendar: Este livro é um divisor de águas. Se você quer entender a fundo como suas informações são coletadas e utilizadas para fins comerciais e políticos, e como isso afeta sua liberdade e escolhas, essa é a leitura essencial. Zuboff é uma pesquisadora renomada e oferece uma análise profunda e bem embasada do tema.
- Título original: Permanent Record
- Título no Brasil: Em Defesa da Verdade ou Vigilância Permanente (título da edição brasileira pode não estar correto)
- Autor: Edward Snowden
- Gênero: Não-ficção, Biografia, Política
- Ano de publicação: 2019
- Número de páginas: 339
- Sinopse: A autobiografia de Edward Snowden, o ex-analista de sistemas da CIA e da NSA que revelou ao mundo os programas de vigilância em massa do governo dos Estados Unidos. Ele narra sua trajetória, desde a infância fascinada por computadores até a decisão de denunciar as práticas ilegais de espionagem.
- Razões para recomendar: Um relato em primeira mão de dentro do sistema, que expõe as entranhas da vigilância governamental. Snowden não apenas detalha as práticas de espionagem, mas também oferece uma reflexão profunda sobre as implicações éticas e políticas da vigilância em massa.
- Título original: Nothing to Hide
- Título no Brasil: Nada a Esconder (título da edição brasileira pode não estar correto)
- Autor: Daniel J. Solove
- Gênero: Não-ficção, Direito, Tecnologia
- Ano de publicação: 2011
- Número de páginas: 254
- Sinopse: Solove desconstrói o argumento de que "se você não tem nada a esconder, não tem nada a temer" em relação à vigilância. Ele argumenta que a vigilância em massa, mesmo quando não revela segredos embaraçosos, pode ter um efeito chilling na liberdade de expressão e no pensamento crítico.
- Razões para recomendar: Este livro oferece uma perspectiva jurídica e filosófica sobre os perigos da vigilância, mesmo para aqueles que acreditam não ter nada a esconder. Solove apresenta argumentos convincentes sobre como a vigilância em massa pode corroer a confiança, a criatividade e a liberdade individual. Espero que essas recomendações te proporcionem ótimas leituras e insights valiosos sobre o tema!
Todos os livros existem. Mas o título brasileiro do livro do Snowden não está correto e o terceiro livro não foi traduzido para o Português. Testei o mesmo prompt com o Claude 3.7 Sonnet, e a resposta foi melhor. Os títulos brasileiros estão corretos, e a única imprecisão é que o terceiro livro também foi publicado no Brasil, mas o modelo não sabe.
- Livro 1
- Título original: The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power
- Título no Brasil: A Era do Capitalismo de Vigilância: A luta por um futuro humano na nova fronteira do poder Autora: Shoshana Zuboff
- Livro 2
- Título original: Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy
- Título no Brasil: Algoritmos de Destruição em Massa: Como o Big Data Aumenta a Desigualdade e Ameaça a Democracia
- Livro 3
- Título original: Privacy is Power: Why and How You Should Take Back Control of Your Data
- Título no Brasil: (Não tenho certeza sobre o título da edição brasileira, pois não posso confirmar se foi publicado no Brasil)
De qualquer forma, mesmo com a resposta do Gemini, fica fácil fazer uma busca pelo autor para encontrar os títulos que foram publicados no Brasil. Pra esta aplicação, é suficiente: mesmo com eventuais imprecisões, podemos seguir, já que a finalidade é recreativa. Se estivéssemos desenvolvendo uma aplicação profissional, teríamos que utilizar uma API externa para validar as recomendações.
Desenvolvendo a interface web: simplicidade e rapidez com Gradio
Gradio é um pacote Python que serve pra criar interfaces web de um jeito fácil e rápido. O pacote é voltado pra machine learning porque ele tem diversas funcionalidades prontas pra criar um chatbot ou plotar gráficos, por exemplo. Mas ele pode ser usado pra qualquer código Python.
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch()
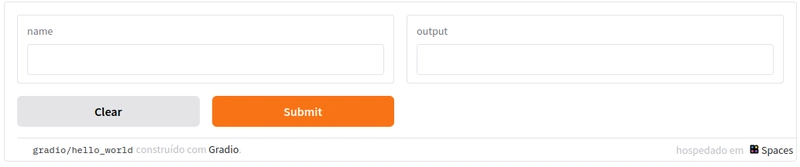
A classe Interface transforma qualquer função Python em uma interface web com poucas linhas de código. No exemplo acima, da documentação do Gradio, só precisamos passar a função que vai processar o input e o tipo do input e do output. No caso, ambos são do tipo texto.
🚀 Dica prática: O Gradio possibilita, inclusive, e com uma linha de código, a criação de uma versão online temporária da aplicação.
demo.launch(share=True)

O exemplo acima é o exemplo mais simples possível. Mas, na app de recomendações, vamos usar a classe Blocks, que permite criar um layout mais customizado.
Em linhas gerais, o arquivo app.py vai ter a estrutura abaixo.
import gradio as gr
from suggestions import get_book_recs
with gr.Blocks() as bibliobot:
with gr.Row():
key = gr.Textbox(
[...]
)
with gr.Row():
with gr.Column():
prompt = gr.Textbox(
[...]
)
submit_btn = gr.Button(
[...]
)
with gr.Column():
response = gr.Textbox(
[...]
)
submit_btn.click(
fn=get_book_recs,
inputs=[key, prompt],
outputs=response
)
bibliobot.launch()
Primeiro, importamos o pacote gradio e a função get_book_recs de suggestions.py.
🔍 Observação: Agora que importamos
get_book_recs, podemos remover o bloco da cláusula de guardaif __name__ == "__main__":.
Em seguida, usamos a classe Blocks e, dentro dela, estabelecemos o layout com duas fileiras, com a segunda fileira dividida em duas colunas.
Depois, configuramos o comportamento do botão, que usa a nossa função get_book_recs com os inputs key e prompt (ambos Textbox que criamos) e recebe o output response (mais um Textbox).
Por fim, rodamos nossa instância bibliobot.
Vamos ver como ficou o código completo, com todas as customizações. Para o tutorial, eu comentei o código para explicar as opções utilizadas.
import gradio as gr
from contents import UI_TEXTS
from suggestions import get_book_recs
# CSS para esconder o rodapé padrão do Gradio
CSS = """
footer {visibility: hidden;}
"""
# Personalizando um dos temas disponíveis no Gradio
theme = gr.themes.Base(
primary_hue="purple",
secondary_hue="gray"
)
# Obtendo textos da interface a partir de um arquivo de conteúdo
api_key = UI_TEXTS["api_key"]
prompt_text = UI_TEXTS["prompt"]
response_text = UI_TEXTS["response"]
button_text = UI_TEXTS["button"]
# Criação da interface com Blocks
with gr.Blocks(
css=CSS,
theme=theme,
title="Bibliobot",
) as bibliobot:
with gr.Row():
key = gr.Textbox(
label=api_key["label"], # Texto descritivo
info=api_key["info"], # Informação adicional exibida como tooltip
placeholder=api_key["placeholder"], # Texto de exemplo
type="password", # Tipo da caixa
autofocus=True # Foco neste campo após o carregamento da página
)
with gr.Row():
# Coluna esquerda com prompt e botão
with gr.Column():
prompt = gr.Textbox(
label=prompt_text["label"],
info=prompt_text["info"],
placeholder=prompt_text["placeholder"],
type="text",
lines=14, # Altura fixa de 14 linhas
max_lines=14 # Limita o texto a 14 linhas
)
submit_btn = gr.Button(
button_text["label"],
size="sm", # Botão de tamanho pequeno
variant="primary" # Estilo primário (cor de destaque)
)
# Coluna direita com resposta
with gr.Column():
response = gr.Textbox(
label=response_text["label"],
show_copy_button=True, # Botão para copiar o texto
type="text",
lines=18, # Altura maior para a resposta
max_lines=18,
autoscroll=False # Sem rolagem automática
)
# Definindo a ação do botão
submit_btn.click(
fn=get_book_recs, # Função que será chamada ao clicar
inputs=[key, prompt], # Inputs que serão passados para a função
outputs=response # Componente que receberá o resultado
)
# Iniciando a aplicação
bibliobot.launch(
favicon_path="favicon.ico", # Ícone personalizado para a aba do navegador
)
Os textos utilizados na interface foram levados para um arquivo separado (contents.py) pra facilitar a manutenção e a legibilidade do código.
✨ Resultado: Essencialmente, criamos uma interface web interativa, funcional, responsiva e agradável usando apenas arquivo em Python.

Isso é particularmente útil para projetos pequenos como o nosso, com foco em funcionalidade e rapidez.
Elevando o projeto: implementação em JavaScript
Mesmo usando esta interface web básica do Gradio, é possível melhorar a apresentação dos dados. O Gradio oferece temas com várias opções de personalização. Além disso, podemos instruir o modelo com um formato de resposta que usa HTML e CSS, por exemplo. E aí, em vez de exibir a resposta em um Textbox, podemos usar o componente Markdown.
No entanto, se o foco passar a ser customização, design e layout, nem precisamos usar o Gradio. É possível, por exemplo, utilizar Flask, um framework do Python, pra criar a interface com HTML, CSS e Javascript puro.
Mas não só de Python puro ou Javascript puro vive a desenvolvedora...
💻 As verdades aparecendo: Todo full stack tem sua preferência: a minha é frontend, e meu coração frontender queria ver uma app que mostrasse as capas dos livros sugeridos.
Para realizar a minha visão pra essa app, fiz uma versão dela em Vue, que é a perfeição em forma de framework. Esta versão usa a lib axios pra bater direto na API da Google. O modelo recebe instrução pra formatar a resposta como json. A string da resposta é parseada em json, e aí a app usa a API da OpenLibrary pra buscar as capas do livros.



Eu AMEI o resultado. O visual minimalista combina demais comigo. ❤️ E é assim que a gente integra um modelo de IA na nossa app.

Top comments (0)