
Last week, I wrote about how the first six weeks at skwirl went. If you haven't read that blog yet you can read it here and if this is the first time you've heard of skwirl you can learn more here. This week, I'll give an overview of the backend.
Kevin pitched skwirl to me about 4 months ago. Before he even finished his pitch I already had some ideas in mind for the tech stack. I wanted to stick with what I already knew to reduce time to market. I also wanted to use bleeding edge tech that I was fairly confident is going to become mainstream in the future. Lastly, I wanted to pick technology that was popular and actively being developed/maintained. My thought process at that point:
- We'd start with a web app but we knew that we'd want a mobile app very soon
- The front/backends should be separated
- The backend would serve both the web frontend and a future mobile app
- I spent several years developing Ruby on Rails apps before switching over to DevOps and working on AWS
- Ideally, the backend would be some form of Ruby/ActiveRecord JSON API
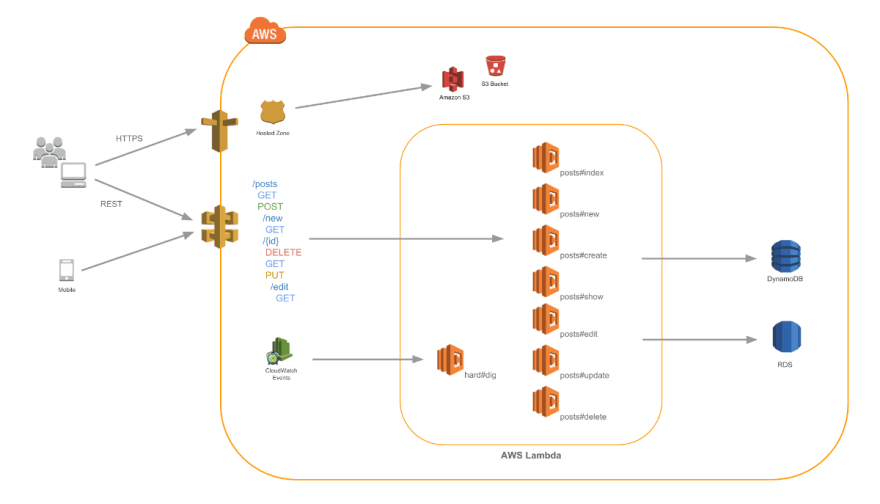
- I wanted to run everything on serverless (read to the end to learn why)
- This narrowed compute choices down to Lambda or Fargate
- Database options would be DynamoDB or Aurora
- React was a strong contender for the front end
- I have absolutely no front end experience
So I searched around the internet with the terms ruby lambda, ruby serverless, rails lambda, rails serverless. Eventually I came across and settled on using Ruby on Jets. Jets is actively being developed by Tung from BoltsOps. From the Jets homepage:
Ruby on Jets allows you to create and deploy serverless services with ease, and to seamlessly glue AWS services together with the most beautiful dynamic language: Ruby. It includes everything you need to build an API and deploy it to AWS Lambda. Jets leverages the power of Ruby to make serverless joyful for everyone.
What I like about Jets
- Has the same project structure as Rails which makes it easy for those with Rails experience to learn
-
Deploys seamlessly to AWS with
jets deployas long as the machine you run the command on has sufficient permissions - Every controller action is a deployed as a separate lambda
- This makes it easy to rewrite specific requests in other languages if needed
-
Lambda function properties are fully customizable at the app, controller, or action level.
- This means request that need more memory/compute can be configured independently
- Access to AWS resources such as S3 can be scoped to just the requests that need them.
- Prewarming is built in
-
routes.rb is automatically translated to API Gateway resources
- local server and console work the same as
rails sandrails c
- local server and console work the same as
- Scheduled jobs are automatically translated into Cloudwatch Event Rules
- Fairly easy to write triggers for lambda. This along with the previous point eliminates the need for something like DelayedJob.
-
Ability to deploy extra copies of your app in the same environment
- This can be used in a CI/CD pipeline to deploy the next version of the app and test it against live data before the end users see the changes
How's performance?
Our staging environment is configured with 512MB of memory. It's deployed in us-east-1 (North Virginia) and I'm in Vancouver, BC. Currently, the request with the longest response time is /login. After being warmed up (we have prewarming turned off in staging), it takes ~950ms. Keep in mind that an expensive hashing function was chosen intentionally. A more reasonable gauge of performance would be /listings. This returns the first 20 active listings created by the current authenticated user. The average response time is ~130ms. Shave off 70ms or so for the Vancouver to North Virginia round trip and we're looking at ~40ms compute/DB time. Not the best but certainly good enough for our use cases especially considering we've done no optimization. We'll likely increase the function memory which increases CPU. Our database is also underpowered. Speaking of which...
The database
I tried very hard to work with DynamoDB but I just couldn't justify using under current conditions. After a month of part time learning (I was still employed at this time), I decided to go with Postgresql. My rationale:
- One month of learning about DynamoDB/NoSQL can't compare to nearly a decade of experience working with Postgresql and ActiveRecord
- Time to market >> cost and performance
- If we ever get to the point where Postgresql doesn't scale enough, we have the best problem in the world (too many customers)
- We can use a db.t2.micro (free tier) in staging and Aurora Serverless in production. Hopefully, this means we can set it and forget it in production. Ask me again in six months how this goes.
- If we ever need anything like DynamoDB streams and triggering lambda off of DyanmoDB, we should be able to get similar results with Kinesis and Aurora
- There are many Ruby Gems like Kaminari for pagination that works with Postgresql/ActiveRecord but not DynamoDB
Authentication
Any minor mistake implementing authentication can lead to catastrophic results. It's a solved problem and I'm not as smart as the people who already solved it. At this point, I already determined that we would eventually have multiple front ends (web and mobile). Session cookies were a no go. So I started looking for a solution that would manage auth/refresh tokens for me.
Cognito was the first one I tried. At first glace, it met all my requirements. Cognito would manage all usernames/passwords as well as JWTs. However, I soon realized that Cognito is a forever solution. There is no way to export password hashes out of Cognito. If we ever needed to migrate away from Cognito, we would have to force all users to reset their password.
In the end, I went with rodauth. Popular solutions like Devise wouldn't work since it's built for Rails. Rodauth on the other hand works with any rack based application. I was pleasantly surprised to discover such as feature rich authentication gem. Janko wrote a great article about it using it with Rails. If there's enough demand I might write an article about using it with Jets.
The Full Serverless Dream?
My serverless dream involves setting up the infrastructure once and forgetting about it. Hopefully, when we get some crazy Black Friday like traffic, Lambda and Aurora can work it's magic and scale without me lifting a finger. Will it work and be seamless for users? Ask me again in 6-12 months. We may not be completely serverless at that point though.
There's a high chance we'll need some sort of dedicated search service like Elasticsearch in the future. I'm not aware of any serverless solution AWS provides. AWS Elasticsearch Service and Cloudsearch are fully managed services. What's the difference? Fully managed services still require you to configure instance type/size, multi-AZ, and in some cases storage/backup. I'm fairly comfortable working with AWS services and would have no problem configuring them to be highly available and durable but if I can off load this work I will.
Next week I'll write about why I chose NextJS and TailwindCSS for the frontend.





Top comments (0)