
Recently, I got an opportunity to write a microservice using NodeJS that consume messages from Kafka, transforms it and produce to another topic.
However, I had to go through the interesting phase of convincing fellow developers and other stakeholders why we should be using NodeJS based microservice instead of Spring Boot.
There are a few existing microservices that are written in NodeJS / Python and are integrated with Kafka. These services are written in the span of last 2 to 3 years. Few libraries were tried and apparently the best at that time was chosen (kafka-node). These services do not work as per expectations and occasionally drops messages.
I have been following KafkaJS npm package and it looks modern and promising so I proposed it.
With little extra efforts, I developed a proof of concept. My goal was to address all the concerns raised by other developers who had bad experience with NodeJS + Kafka stack.
Here is the high level design -
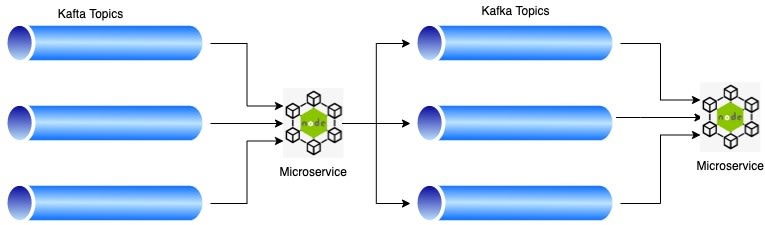
Primary responsibility of the microservice is
- Consume Json messages
- Transform the Json into multiple small Json objects
- Produce it on multiple Kafka topics based on some conditions
I compared the microservices based on SpringBoot vs NodeJs.
Following are my observations
Of course, it is well known fact that NodeJs is much better than Java in terms of resource consumption, I had to add these details as well to emphasise that it really make sense to use NodeJS.
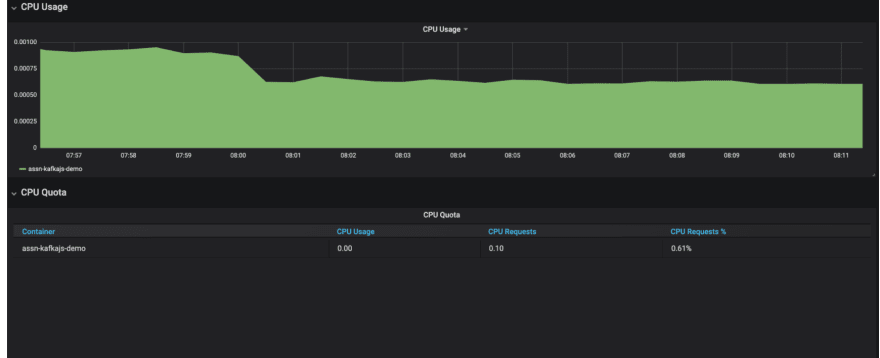
NodeJS based Microservice
CPU Utilisation
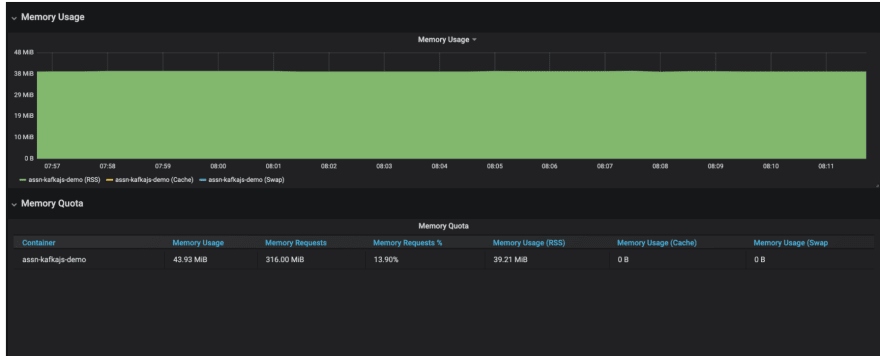
Memory Utilisation
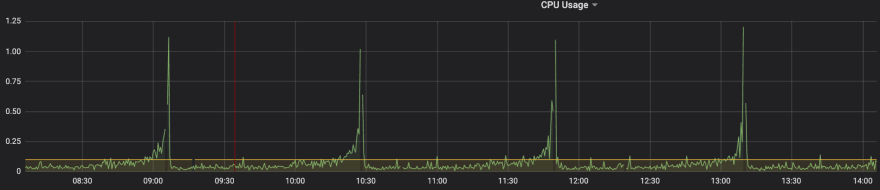
SpringBoot based Microservice (similar load)
CPU Utilisation
Memory Utilisation
The resource requirement for Java application is 6 times+ more than NodeJS application, so is the monthly AWS bill.
I used streaming feature, consuming one message at a time to keep it simple. Batch processing requires extra care and love.
Throughput can be increased by having more partitions.
Following are some of the concerns and my response
- KafkaJS may not be reliable in long run
KafkaJS usage is steadily increasing and they have got a very supportive developers and community. It is less likely to go away in near future.
- There are few open issues in the Library
There are open issues in all well established technologies that includes Java and Springboot. This cannot be the ground to reject the proposal. It is proved in POC that the functionality we needed works fine.
- Does KafkaJS support particular version and implementation of Kafka that we are using?
This was proved in POC
- Is Consumer/Producer Rebalancing supported?
When one consumer/producer goes down, another processor should attach itself to the partition and consume/produce the messages. This was proved as part of POC
- Does it recover from broker going down and another instance coming up?
When one of the brokers goes down, consumer application should be able to reestablish the connection with new instance. This was proved in POC.
To prove that KafkaJS library is good enough, I prepared demo consumer/producer microservices and ran those over 3 to 4 days. These services processed thousands of messages in this time without dropping a single message in all failure situations.
Finally, the POC helped to make the way for KafkaJS in our tech stack. Nevertheless, I really appreciate my team and all for raising concerns and completing POC more convincingly.
At the end, I also believe that however much good are the platform and technology, it is up to a developer how he/she writes the code and take care of corner cases. Development cannot be always plug n play :).
Refer following links for more information on KafkaJS
https://kafka.js.org/docs/getting-started
https://github.com/tulios/kafkajs
https://www.npmjs.com/package/kafkajs

Top comments (5)
One of the authors of KafkaJS here 👋 Thanks for the write-up, and I'm glad to hear that you had success introducing KafkaJS to your team.
While you are correct that KafkaJS isn't going anywhere anytime soon, that's not because of DigitalOcean's support. They have been providing some credits to run infrastructure, but they are not supporting the development itself. Currently there is no corporate sponsorship of KafkaJS, just the time that we and our community contributors put in - but as far as I know that's the same for all other Kafka clients except the official Java one (and maybe librdkafka).
Nice to hear from you @Tommy. I am impressed with the simplicity and documentation of KafkaJS. It did not let me down a single time in my POC.
Java - out of the box, is horrendous on resources. Spring Boot makes things worse still. Sure, there's things you can do to minimise these (and overall artefact size), like jlink or native compilation, or using a different JVM, configuring memory limits, etc etc etc...
But I'm curious why your team weren't already aware of this core difference between Node and Java, why did you have to prove it to them?
Java vs NodeJS is just one of the reasons.
But the other is fear of NodeJS + KafkaJS stack.
KafkaJS stood with all tests.
There are more reasons but do not wish to pen down here :)
You said: To prove that KafkaJS library is good enough, I prepared demo consumer/producer microservices and ran those over 3 to 4 days. These services processed thousands of messages in this time without dropping a single message in all failure situations.
Are there any code examples of these demos? This would be very useful to look at as I've been tasked with something similar.
I'm trying to validate kafka failover in a 3 node cluster with a very basic 3 partition 3 consumer group reading messages using eachMessage and I am verifying whether there are dropped messages. There are. However, that could be due to my configuration setup. The producers work fine, it's just my consumers.
Thank you!!!
Ira Klotzko