Problem Statement:
Let’s design a Twitter like social networking service.
Users of the service will be able to post tweets, follow other people and favorite tweets.
Step-1: What is Twitter ?
Twitter is an online social networking service where users post and read short 140-character messages called “tweets”.
Registered users can post and read tweets, but those who are not registered can only read them.
Users access Twitter through their website interface, SMS or mobile app.
Step-2: Requirements and Goals of the System
Functional Requirements:
- Users should be able to post new tweets.
- A user should be able to follow other users.
- Users should be able to mark tweets favorite.
- The service should be able to create and display user’s timeline consisting of top tweets from all the people the user follows.
- Tweets can contain photos and videos.
Non-Functional Requirements:
- Our service needs to be highly available.
- Acceptable latency of the system is 200ms for timeline generation.
- Consistency can take a hit (in the interest of availability), if a user doesn’t see a tweet for a while, it should be fine. System should be highly available.
- Read Heavy & Fast rendering
Extended Requirements:
- Searching tweets.
- Reply to a tweet.
- Trending topics – current hot topics/searches.
- Tagging other users.
- Tweet Notification.
- Who to follow? Suggestions?
- Moments.
Step-3: Capacity Estimation and Constraints
Let’s assume we have 1 Billion total users, With 200 Million daily active users (DAU).
Also, we have 100 Million new tweets every day, and on average each user follows 200 people.
Storage Estimates:
let say we have 140 Chars in a tweet & we need 2 byte to store one char total 280 bytes + assume extra 30 Bytes to store some metadeta near to 300 bytes
As we have near to 100M tweets per day = 100 X10^6 x .3 x10^3 = 30 GB
Total Storage needed for 5 years: 5 * 365 * 30GB = 54.75 TB
Not all tweets will have media, let’s assume that on average every 5th tweet has a photo and every 10th has a video.
Let’s also assume on average a photo is 200KB and a video is 2MB.
Total New Media in a day: (100M/5 photos * 200KB) + (100M/10 videos * 2MB) ~= 24TB/day
Total Storage needed for 5 years: 5 * 365 * 24TB = 43,800 TB
=~ 43PB
Step-4: System APIs
Parameters:
api_dev_key (string): API developer key that will be used to, among other things, throttle users based on their allocated quota.
tweet_data (string): The text of the tweet, typically up to 140 characters.
tweet_location (string): Optional location (longitude, latitude) this Tweet refers to.
user_location (string): Optional location (longitude, latitude) of the user adding the tweet.
media_ids (number[]): Optional list of media_ids to be associated with the Tweet. (All the media photo, video, etc.) need to be uploaded separately.
Returns: (string)
A successful post will return the URL to access that tweet. Otherwise, an appropriate HTTP error is returned.
postTweet(api_dev_key, tweet_data, tweet_location, user_location, media_ids, maximum_results_to_return)
Follow or unfollow a user
This API will allow the user to follow or unfollow another user.
follow(followerID: UUID, followeeID: UUID): boolean
unfollow(followerID: UUID, followeeID: UUID): boolean
Get newsfeed
This API will return all the tweets to be shown within a given newsfeed.
getNewsfeed(userID: UUID): Tweet[]
Step-5: High Level System Design
We need a system that can efficiently store all new tweets, 100M/86400s => 1150 tweets / s & read 28B/86400s => 325K tweets / s.
It is clear from the requirements that this will be a read-heavy system.
At high level, we need multiple application servers to serve all requests with load balancers in front of them for traffic distributions.
On the backend, we need an efficient database that can store all the new tweets and can support a huge number of reads.
We would also need some file storage to store photos and videos.
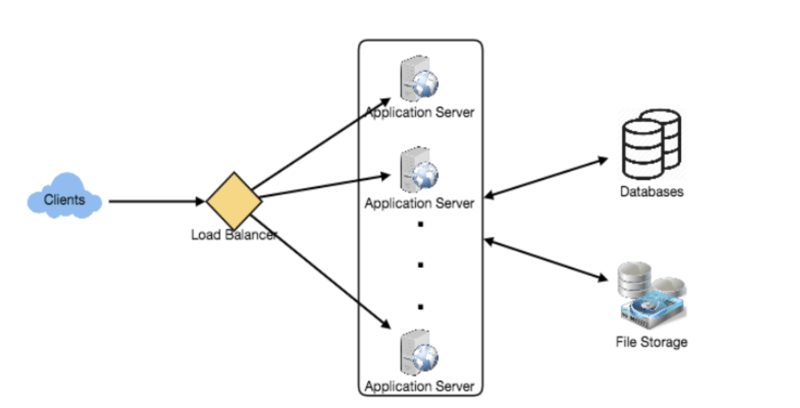
This traffic will be distributed unevenly throughout the day, though, at peak time we should expect at least a few thousand write requests and around 1M read requests per second.
We should keep this thing in mind while designing the architecture of our system.
Step-6: Database Schema
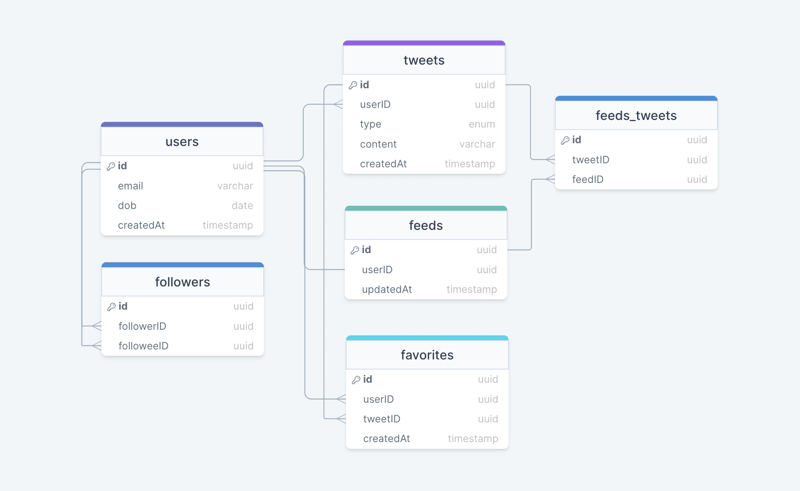
We have the following tables:
users
This table will contain a user's information such as name, email, dob, and other details.
tweets
As the name suggests, this table will store tweets and their properties such as type (text, image, video, etc.), content, etc. We will also store the corresponding userID.
favorites
This table maps tweets with users for the favorite tweets functionality in our application.
followers
This table maps the followers and followees as users can follow each other (N:M relationship).
feeds
This table stores feed properties with the corresponding userID.
feeds_tweets
This table maps tweets and feed (N:M relationship).
What kind of database should we use?
While our data model seems quite relational, we don't necessarily need to store everything in a single database, as this can limit our scalability and quickly become a bottleneck.
We will split the data between different services each having ownership over a particular table. Then we can use a relational database such as PostgreSQL or a distributed NoSQL database such as Apache Cassandra for our use case.
Step-7: Data Sharding
Since we have a huge number of new tweets every day and our read load is extremely high too, we need to distribute our data onto multiple machines such that we can read/write it efficiently.
Step-8: Cache
We can introduce a cache for database servers to cache hot tweets and users.
We can use an off-the-shelf solution like Memcache that can store the whole tweet objects.
Application servers before hitting database can quickly check if the cache has desired tweets.
Based on clients’ usage pattern we can determine how many cache servers we need.
What if we cache the latest data ?
Our service can benefit from this approach. If 80% of users see tweets from past 3 days only, try to cache all the tweets from past 3 days.
Let’s say we have dedicated cache servers that cache all the tweets from all users from past 3 days.
As estimated above, we are getting 100 million new tweets or 30GB of new data every day (without photos and videos).
If we want to store all the tweets from last 3 days, we would need less than 100GB of memory.
This can easily fit into 1 server, but replicating it to multiple servers distributes all read traffic to reduce load on cache servers.
So to generate a user’s timeline, ask the cache servers if they have all the recent tweets for that user, if yes, simply return all the data from the cache, if not query backend to fetch that data.
On a similar design, we can try caching photos and videos from last 3 days.
Our cache would be like a hash table, where ‘key’ would be ‘OwnerID’ and ‘value’ would be a doubly linked list containing all the tweets from that user in past 3 days.
Since we want to retrieve most recent data first, we can always insert new tweets at the head of the linked list, which means all the older tweets will be near the tail of the linked list.
Therefore, we can remove tweets from the tail to make space for newer tweets.
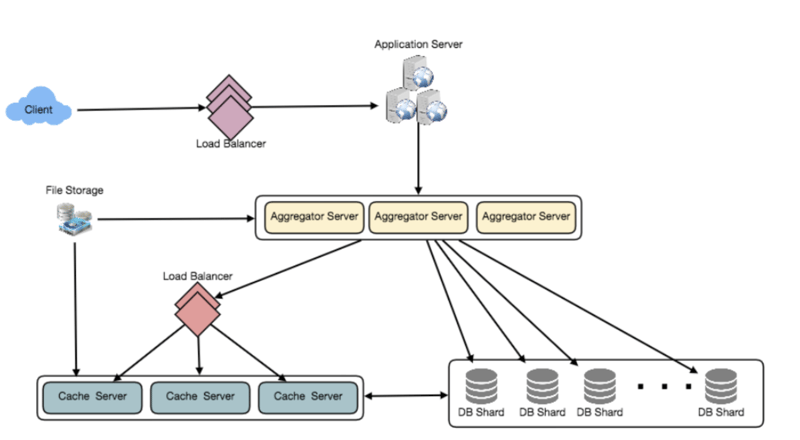
Step-10: Replication and Fault Tolerance
Since our system is read-heavy, we can have multiple secondary database servers for each DB partition.
Secondary servers will be used for read traffic only.
All writes will first go to the primary server and then will be replicated to secondary servers.
This scheme will also give us fault tolerance, as whenever the primary server goes down, we can failover to a secondary server.
Step-13: Extended Requirements
How to serve feeds ?
Get all the latest tweets from the people someone follows and merge/sort them by time.
Use pagination to fetch/show tweets.
Only fetch top N tweets from all the people someone follows.
This N will depend on the client’s Viewport, as on mobile we show fewer tweets compared to a Web client.
We can also cache next top tweets to speed things up.
Alternately, we can pre-generate the feed to improve efficiency, similar to ‘Ranking and timeline generation’ of Instagram.
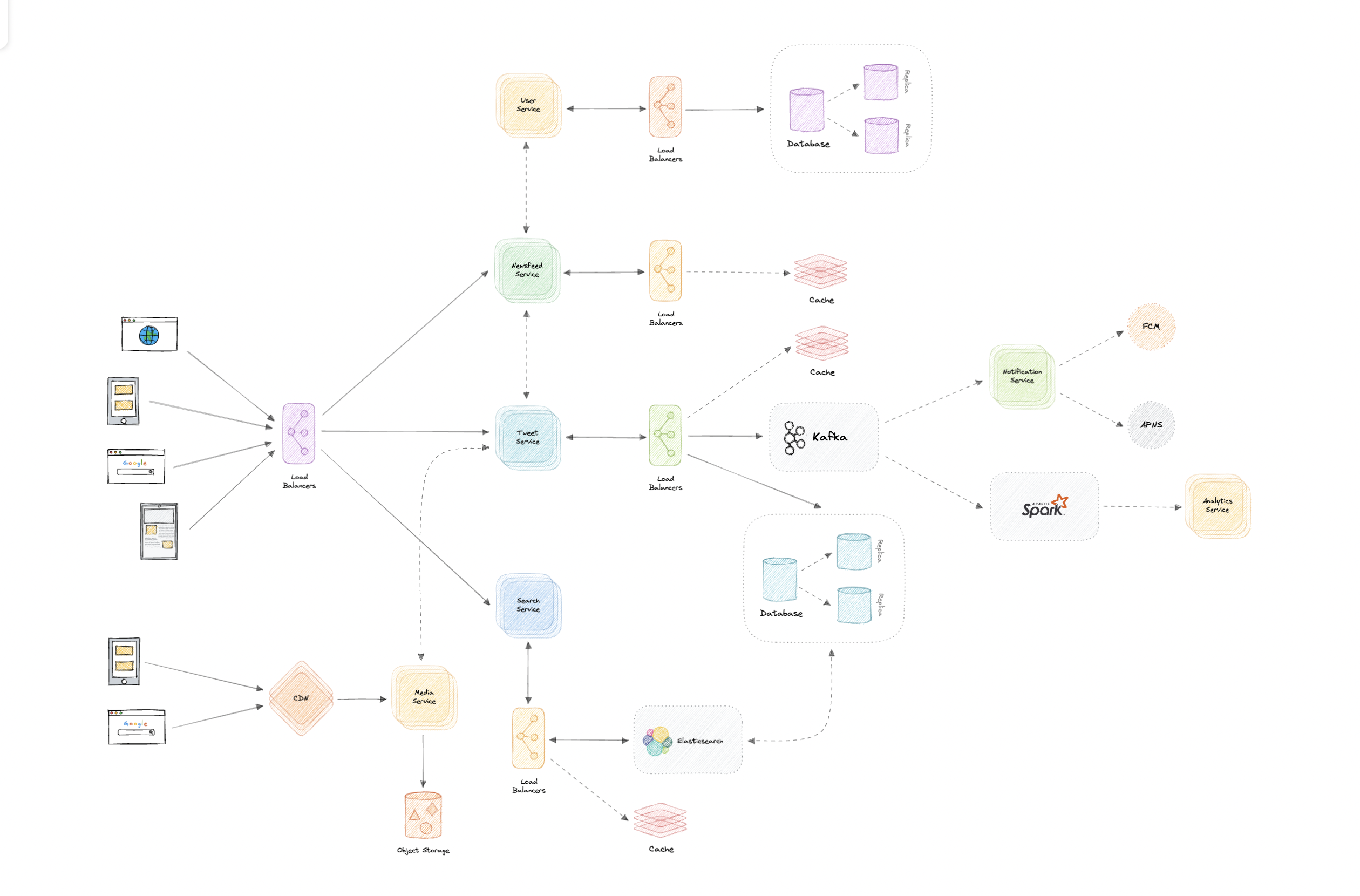
Step-14: Architecture
We will be using microservices architecture since it will make it easier to horizontally scale and decouple our services. Each service will have ownership of its own data model. Let's try to divide our system into some core services.
User Service
This service handles user-related concerns such as authentication and user information.
Newsfeed Service
This service will handle the generation and publishing of user newsfeeds. It will be discussed in detail separately.
Tweet Service
The tweet service will handle tweet-related use cases such as posting a tweet, favorites, etc.
Search Service
The service is responsible for handling search-related functionality. It will be discussed in detail separately.
Media service
This service will handle the media (images, videos, files, etc.) uploads. It will be discussed in detail separately.
Notification Service
This service will simply send push notifications to the users.
Analytics Service
This service will be used for metrics and analytics use cases.
Newsfeed
When it comes to the newsfeed, it seems easy enough to implement, but there are a lot of things that can make or break this feature. So, let's divide our problem into two parts:
Generation
Let's assume we want to generate the feed for user A, we will perform the following steps:
Retrieve the IDs of all the users and entities (hashtags, topics, etc.) user A follows.
Fetch the relevant tweets for each of the retrieved IDs.
Use a ranking algorithm to rank the tweets based on parameters such as relevance, time, engagement, etc.
Return the ranked tweets data to the client in a paginated manner.
Feed generation is an intensive process and can take quite a lot of time, especially for users following a lot of people. To improve the performance, the feed can be pre-generated and stored in the cache, then we can have a mechanism to periodically update the feed and apply our ranking algorithm to the new tweets.
Publishing
Publishing is the step where the feed data is pushed according to each specific user. This can be a quite heavy operation, as a user may have millions of friends or followers. To deal with this, we have three different approaches:
Pull Model (or Fan-out on load)
newsfeed-pull-model
When a user creates a tweet, and a follower reloads their newsfeed, the feed is created and stored in memory. The most recent feed is only loaded when the user requests it. This approach reduces the number of write operations on our database.
The downside of this approach is that the users will not be able to view recent feeds unless they "pull" the data from the server, which will increase the number of read operations on the server.
Push Model (or Fan-out on write)
newsfeed-push-model
In this model, once a user creates a tweet, it is "pushed" to all the follower's feeds immediately. This prevents the system from having to go through a user's entire followers list to check for updates.
However, the downside of this approach is that it would increase the number of write operations on the database.
Hybrid Model
A third approach is a hybrid model between the pull and push model. It combines the beneficial features of the above two models and tries to provide a balanced approach between the two.
The hybrid model allows only users with a lesser number of followers to use the push model. For users with a higher number of followers such as celebrities, the pull model is used.
Retweets
Retweets are one of our extended requirements. To implement this feature, we can simply create a new tweet with the user id of the user retweeting the original tweet and then modify the type enum and content property of the new tweet to link it with the original tweet.
For example, the type enum property can be of type tweet, similar to text, video, etc and content can be the id of the original tweet. Here the first row indicates the original tweet while the second row is how we can represent a retweet.
Search
Sometimes traditional DBMS are not performant enough, we need something which allows us to store, search, and analyze huge volumes of data quickly and in near real-time and give results within milliseconds. Elasticsearch can help us with this use case.
Elasticsearch is a distributed, free and open search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured. It is built on top of Apache Lucene.
How do we identify trending topics?
Trending functionality will be based on top of the search functionality. We can cache the most frequently searched queries, hashtags, and topics in the last N seconds and update them every M seconds using some sort of batch job mechanism. Our ranking algorithm can also be applied to the trending topics to give them more weight and personalize them for the user.





{kind=link}
Top comments (0)