
Welcome back to the DevOps series. If you read last week's article, I listed some of the defining properties of DevOps projects. This week I will cover in detail the aspect of quality in DevOps projects and also in non-DevOps projects. So let's begin.
Quality
Many teams have wildly different definitions of quality, such as having few open issues in your bug tracker, how well the software meets requirements, how readable the source code is, how fast it is, and so on. These aspects are all significant, but there is one crucial trait that dominates how highly-looked upon the project is, and that is the ability to complete all stages of the project quickly, or in other words, a high turnover time. When the teams for programming, architecting, QA, testing, system administrators, DBAs, and specification drafting coordinate with each other to correct misunderstandings about the project, the software can get from the planning stage to the maintenance stage quickly. And arguably, this is the defining feature of DevOps; If everybody works together, then they spend less time at meetings debating about how they think or not think they should perform the work, right?
And this is a typical problem when teams are assigned to work in silos. When you have each member of a small (4 to 8 person) team working in their own room, and they don't talk to each other, then each person goes their own way. The person managing them has no idea what progress is being made because each person will give different answers depending on what they know.

When team members work isolated from each other, they have a different view of overall progress.
And this concept can be extended to multiple teams in a department. In this case, they don't share rooms, but regular meetings between the different teams are essential to foster understanding of the project's state. Teams don't need to exchange as much information with other teams. Still, you do have to make sure that you are transmitting essential input to other teams because misaligned ideas of progress within a whole department are much more significant than within a team. A single team can be disbanded, but it's harder to restructure an entire department since more people are involved.
A second, more closely related definition of quality is the behavior of software at runtime. Operations see this aspect best because they are responsible for correcting faults. Faults can be defined as specific behavior in applications triggered in the right conditions to cause a failure. In contrast, a failure is any symptom of degradation, unresponsiveness, or unavailability in one or more parts of an application.
Unfortunately, many people think that they can add quality to a project after it has been written by performing rigid testing. That approach will not work, not only because the above definitions of quality preclude any change towards high turnover time, but also because tests, by definition, cannot make a project adhere to its specification if it is programmed to do something deviant of it. They can only prevent unintentional bugs from getting into production systems.
Senarios
Let us look at some examples of how projects that do not make use of DevOps are organized and their resulting quality.
Standards-confirming project with poorly-written code
There's only one version of the project that operations can run without problems, and that is the current version. However, because the source code is cryptic, it is unmaintainable for development. Therefore, operations may think that the software is high quality, but development views it as low quality. The poorly-written source code has the side effect that future updates and bug fixes will be similarly unmaintainable but will also be of worse quality to operations. Since development cannot update the code correctly, they can't guarantee if it's specification-conformant. Operations will notice this while it's running in the form of more faults and failures. Therefore, we say that this kind of software is low quality.
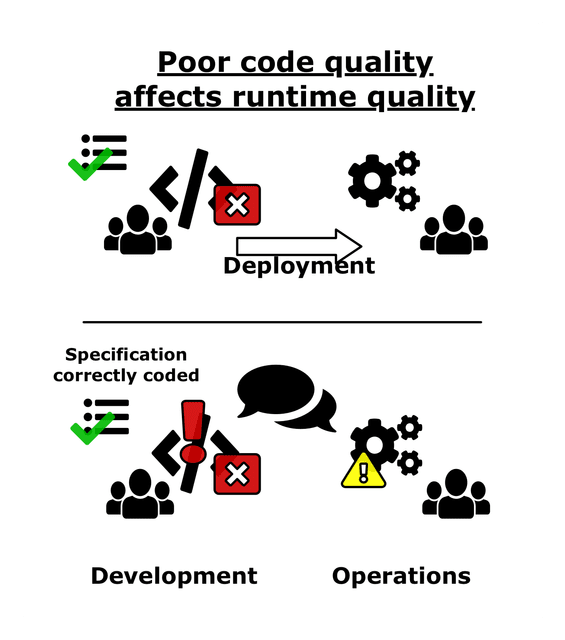
If the final software runs well but the codebase is low quality, it will eventually lower runtime a
quality as well.
Unbalanced development and operations staff
A project may already have a fast release cycle and conform to its specification. Still, If an operations staff has too few people, then the team will be overwhelmed by development's release cycle and won't be able to catch all faults in time to remedy them before they turn into failures. Development may not be getting enough log files and problem reports which they need to diagnose bugs as well. This increases pressure on operations to make the software more stable, so they "accomplish" this by stalling or outright blocking newer versions from being pushed into production, which of course, will anger development, who will argue with operations about it. Meanwhile, the cooperation between development and operations deteriorates, which causes the code to become lower quality.

A small operations team overwhelmed with rapid releases from development
The maven manager
The final example involves what I call a "maven manager" hired explicitly to improve a deployed low-quality project, who has a rudimentary understanding of the responsibilities of all the departments they manage (this is the critical part). They would not attempt to take down the worse project version all at once (because business revenue or some other infrastructure relies on it). Instead, he organizes a blue/green deployment where operations are initially left maintaining the problematic software, along with minimal development staff enough to patch bugs. At the same time, they instruct project management to create a revised specification ameliorating flaws in the initial design. Meanwhile, he reorganizes the rest of development into better combinations of teams that can efficiently communicate with each other. The new specification is handed to them to program and test a higher quality software out on time. Then the majority of operations is rolled over to the newer software, and a second set of communication channels are made for them, linked together to development's channels by a few gateways to enable rapid coordination to resolve failures, eliminate faults and find blank spaces in the software where new features are desirable.
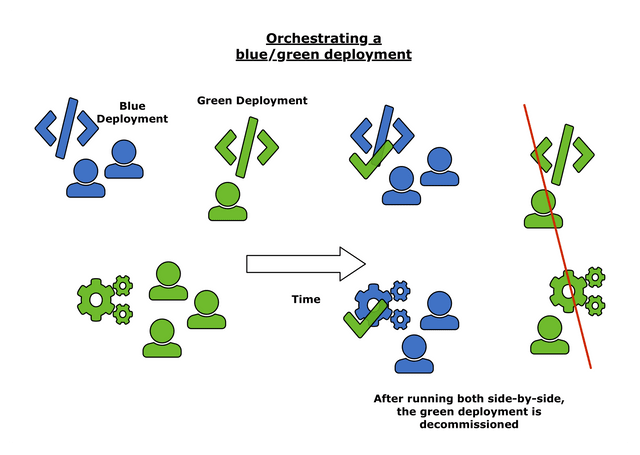
How a manager can initiate a blue/green deployment to improve low-quality software
How does quality get into a project anyway?
As development makes more builds of software and tests them, they don't get handed to operations until they fix all of the bugs. Each set of patches that goes into a build reduces the number of bugs inverse-exponentially (i.e., at the rate of an inverse exponential graph). When operations run the software and find a bug, the availability of detailed log reports enables development to fix the issue quickly. And like this, usually, only a few problems are found and subsequently fixed at a time, easing the development load.
On Quality Assurance
Quality Assurance (QA) is the process of ensuring the software meets the specifications of the project and also that the end-user experience is good and the software has high performance. In a traditional project, there is a separate team responsible for all of this.
In a DevOps project, these tasks are performed by the whole development and operations department. There is no separate QA team, although there are QA specialists who may be in the development or operations departments. Having all team members perform QA allows them to know for themselves how well the project runs to show it to their co-workers and other staff. This makes it easier to alleviate specification deviations because people don't have to take it by word and mouth that a project is deviant; they can verify it themselves. With this trustless model, there can be no possibility of high-running feelings between different teams resulting from misunderstandings.
You do not need DevOps if you just need better quality
This is an important point. If you are tasked to fix a sinking project that suffers from low quality, you probably don't have the funding to orchestrate a full transition to DevOps. And you definitely don't want to leave your staff in an intermediate state half-way between a traditional and DevOps project because they all would need to learn two different processes to do the same action in a company.
Instead, it would be best if you focused on incrementally replacing individual units of an application that are already self-replaceable by revising the specification for that part, have your developers use better programming and testing practices to write this newer component, and deploy that part separately using a blue/green deployment scheme. Have operations roll back the production environment to the old component if the newer one fails and communicate with them the failures and then have everybody involved fix it together. Once the component is stable enough, decommission the older component (freeing operations resources) and solely run on the newer component. Repeat this for the rest of the parts of the application until everything is upgraded.
But what if you have monolithic software that you can divide into components? Then your blue/green deployment has to have enough resources to support all parts of both old and new projects simultaneously. Hopefully, you have the funding to secure that, but in case you don't, focus on making the more recent project as small as possible. Remove features seldomly used and optimize the program, especially the back-end, to use less memory and disk space. Any money thrown at the legacy monolithic project not being used to fix failures and security vulnerabilities is a waste and will deplete your budget, so avoid trying to patch a broken project.
That all for now. See you next week for more DevOps concepts!

Top comments (0)