
💡 The Motivation
Let’s be real. Nobody likes waiting in queues, especially not the ones where money’s on the line and fraudsters are already ten steps ahead. Batch-processing systems? Too slow. By the time they catch a fraud, your card’s already buying pizza in two continents.
So I set out to build a real-time fraud detection pipeline, one that catches shady transactions faster than you can say “Kafka.”
⚙️ Tech Stack
- Apache Kafka – for scalable, real-time data streaming
- Python – The glue that holds the pipeline together
- Scikit-learn – for the K-Nearest Neighbors model
- Matplotlib & Seaborn – graphs for nerdy satisfaction
- Docker Compose – one command to bring the whole circus alive
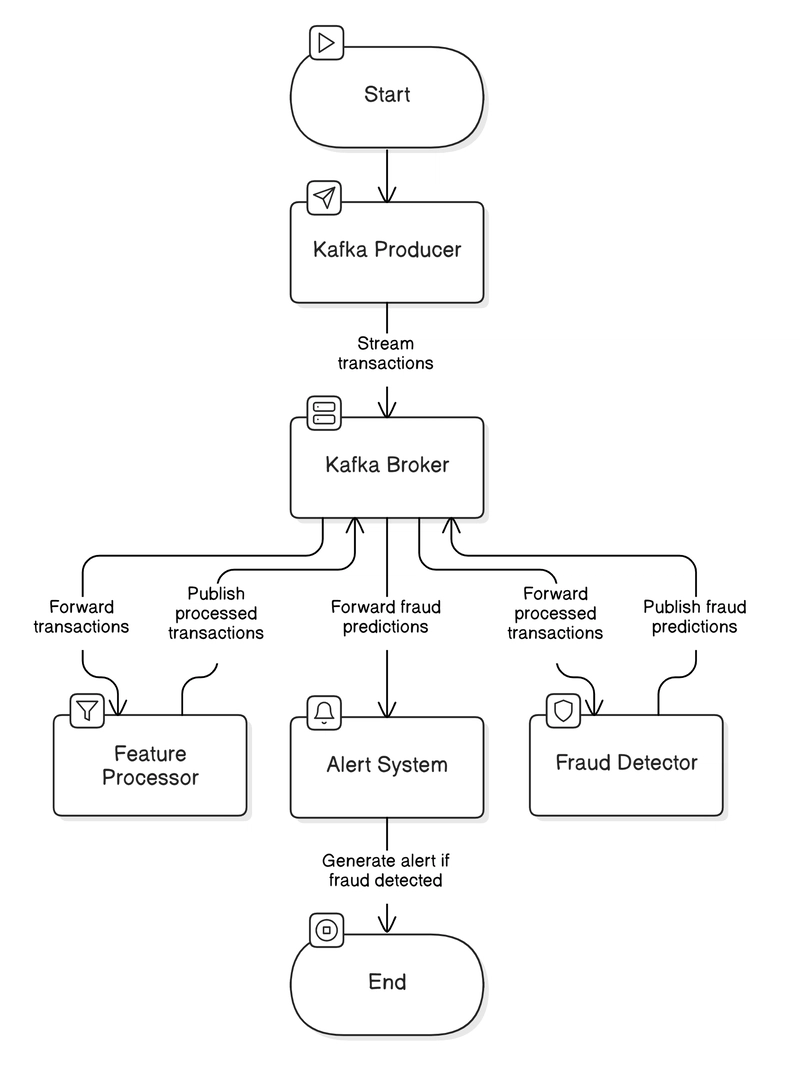
🧠 The Architecture (Visually)
🗂️ Project Structure
ccfraud_kafka/
│
├── pipeline/
│ ├── producer.py # Streams transaction data to Kafka
│ ├── feature_processor.py # Scales and preprocesses features
│ ├── fraud_detector.py # Runs the ML model and predicts fraud
│ └── alert_system.py # Sends alerts + plots graphs
│
├── models/
│ ├── train_model.py # Trains and evaluates KNN
│ ├── fraud_model.pkl # Saved model
│ ├── time_scaler.pkl # Time scaler
│ └── amount_scaler.pkl # Amount scaler
│
├── ccprod.csv # Sample chunk of the credit card dataset
└── docker-compose.yml # Container orchestration
⚙️ Pipeline Flow (TL;DR)
Producer reads transaction rows from CSV and streams them into the transactions Kafka topic.
Feature Processor consumes from that topic and applies RobustScaler to Time and Amount.
Fraud Detector loads a trained KNN model and evaluates fraud probability.
Alert System logs suspicious transactions with full timestamps and gives beautiful metrics and visualizations.
Best part? Some alerts clocked in under 30 milliseconds end-to-end! Take that, Flash.
🧠 Code Snippets You’ll Love
🌀 Streaming Producer
def _clean_transaction(self, transaction):
clean_tx = {k: float(v) for k, v in transaction.items()
if k not in ['Class']}
clean_tx['transaction_id'] = str(uuid.uuid4())
clean_tx['timestamp_received'] = datetime.utcnow().isoformat()
return clean_tx
🔬 Feature Processor
def _scale_features(self, transaction):
scaled = transaction.copy()
scaled['Time'] = self.scalers['Time'].transform([[transaction['Time']]])[0][0]
scaled['Amount'] = self.scalers['Amount'].transform([[transaction['Amount']]])[0][0]
return scaled
🤖 KNN Prediction
proba = self.model.predict_proba(features)[0][1]
if proba >= 0.8:
# It’s a fraud, my dude!
🛠️ Deployment (Docker-ized AF)
version: '3.8'
services:
kafka:
image: confluentinc/cp-kafka:7.0.1
zookeeper:
image: confluentinc/cp-zookeeper:7.0.1
# microservices are launched manually (or add them later!)
🚀The Superheroes: Kafka Topics
# Create raw transactions topic
docker compose exec kafka kafka-topics --create --bootstrap-server kafka:9092 --topic transactions --partitions 3 --replication-factor 1 --config retention.ms=604800000
# Create processed transactions topic
docker compose exec kafka kafka-topics --create --bootstrap-server kafka:9092 --topic processed_transactions --partitions 3 --replication-factor 1 --config retention.ms=604800000
# Create fraud predictions topic
docker compose exec kafka kafka-topics --create --bootstrap-server kafka:9092 --topic fraud_predictions --partitions 3 --replication-factor 1 --config retention.ms=2592000000
✨ Output Sneak Peek
🧠 Trained Model Metrics

💸 Real-Time Fraud Alerts (Sample Logs)

→ End-to-end latency: ~30ms
→ Fast enough to warn Batman before Joker hits send.
📊 Visualizations (via alert_system.py)



🚀 Results Worth Flexing
- Minimum Latency: 30ms 🚀
- Average Inference Time: Sub-500ms
- Peak Throughput: 1200 tx/min
- Accuracy: 93%
Built for speed, precision, and modular deployment.
💡 Future Scope
- Add Prometheus + Grafana for robust observability
- Upgrade to model versioning with MLFlow
- Shift to Spark Streaming or Flink if horizontal scaling is required
- Build a pipeline with the help of TARS and a conveniently located wormhole?(I need help)

“The path of the fraudster is beset on all sides by the Kafka-powered processor and the righteous model...”
– Not Jules. But let’s pretend.
If this sparked your curiosity or made you laugh (even a little), you know the drill.
Have questions? Ping me. I don’t bite (unless you're a fraudulent transaction). 💳💥

Top comments (14)
Amazing work creating this efficient pipeline with clear implementation details! What inspired the choice of tools and techniques used here?
Hey Nevo, I'm glad you liked my implementation!
The choice of tools was shaped by both hands-on experience and practical constraints. I used kNN instead of Random forest based on a comparative study of model performance for this particular dataset which I found on kaggle, although random forest stands out for problem statements regarding fraud and anomaly detection.
For the pipeline I specifically used kafka because of the theoretical familiarity I had about it; high throughput. Kafka's streaming capabilities addresses real world credit card transactions scenarios where thousands of transactions occur each second at varying time differences. Although after a thorough literature review of multiple research papers, Apache Flink stood out but I had already started my implementation and my faculty guide also supported me using Kafka for because of it's wider adoption in the industry.
I chose Docker mainly for consistency and ease of deployment. For a project like this that mimics production behavior, using containers felt closer to how things would run in the real world.
Great blog
Thank you Vedangi!
Love the little jokes if need help hit me up! And nice project for seminar
Thank you Arya!
Great work Ahad!
Loved how you combined technical depth with humour!! Great Project!
Thank you Rachit!
sensational
honestly, an amazing blog, one of the best reads in a long time.
great work Ahad!
Thank you Vishvesh!
Some comments may only be visible to logged-in visitors. Sign in to view all comments.