This article helps cloud engineers, security engineers, Machine Learning Ops (MLOps) engineers, and data scientists understand the various components of building a secure enterprise machine learning (ML) platform. from AWS whitepaper documentation.
Introduction
Building an enterprise ML platform for regulated industries such as financial services can be a complex architectural, operational, and governance challenge.
AWS offers a comprehensive suite of services that enable the development of flexible, secure, and scalable ML platforms for demanding use cases. This resource provides architecture patterns, code samples, and best practices to guide the construction of an enterprise ML platform on AWS.
Building an enterprise machine learning platform requires the collaboration of different cross-functional teams such as:
Cloud and security engineers: Cloud engineering, and security engineering teams are responsible for creating, configuring, and managing the AWS accounts, and the resources in the accounts. They set up AWS accounts for the different lines of business and operating environments and configure networking and security. Also work with other security functions, such as identity and access management, to set up the required users, roles, and policies to grant users and services permissions to perform various operations in the AWS accounts.
Data engineers: Work closely with data scientists and ML engineers to help identify data sources, and build out data management capabilities, and data processing pipelines. They establish security controls around data to enable both data science experimentation and automated pipelines.
MLOps engineers: Build and manage automation pipelines to operationalize the ML platform and ML pipelines for fully/partially automated CI/CD pipelines, such as pipelines for building Docker images, model training, and model deployment. They utilize different services such as pipeline tools, code repository, container repository, library package management, model management, and ML training.
Data scientists and ML engineers: they are the end-users of the platform. They use the platform for experimentation, such as exploratory data analysis, data preparation and feature engineering, model training, and model validation.
IT Auditors: Responsible for analyzing system access activities, identifying anomalies and violations, preparing audit reports for audit findings, and recommending remediations.
Model risk managers: Responsible for ensuring machine learning models meet various external and internal control requirements.
Identity and Access Management
To establish a secure ML environment, both human and machine identities need to be defined and created to allow for the intended access into the environment. AWS Identity and Access Management (IAM) is the primary access control mechanism for provisioning access to AWS resources in your environment.
User Roles
Data scientist/ML engineering role: The IAM role provides access to the resources and services that are mainly used for experimentation. These services could include SageMaker Studio or Notebook, Amazon S3 for data access, and Athena for data querying.
Data engineering role: The IAM role provides access to the resources and services mainly used for data management, data pipeline development, and operations. These services could include S3, AWS Glue, Amazon EMR, Athena, Amazon RDS, and SageMaker Notebook.
MLOps engineering role: The IAM role provides access to the resources and services mainly used for building automation pipelines and infrastructure monitoring. These services could include SageMaker, AWS CodePipeline, AWS CodeBuild, AWS CloudFormation, Amazon ECR, AWS Lambda, and AWS Step Functions.
Service roles
SageMaker notebook execution role: This role is assumed by a SageMaker Notebook instance or SageMaker Studio Application when code or AWS commands (such as CLI) are run in the notebook instance or Studio environment.
SageMaker processing job role: This role is assumed by SageMaker processing when a processing job is run. This role provides access to resources such as an S3 bucket to use for input and output for the job.
SageMaker training/tuning job role: This role is assumed by the SageMaker training/tuning job when the job is run. Similarly, the SageMaker notebook execution-role can be used to run the training job.
SageMaker model execution role: This role is assumed by the inference container hosting the model when deployed to a SageMaker endpoint or used by the SageMaker Batch Transform job.
Other service roles: Other services such as AWS Glue, Step Functions, and CodePipeline also need service roles to assume when running a job or a pipeline.
The figure below shows the user and service roles for a SageMaker user and SageMaker service functions.

Encryption with AWS KMS
Amazon SageMaker automatically encrypts model artifacts and storage volumes attached to training instances with AWS managed encryption key.
For regulated workloads with highly sensitive data, you might require data encryption using an AWS KMS key (formerly CMK). The following set of AWS services provide data encryption support with a KMS key.
- SageMaker Processing, SageMaker Training (including AutoPilot), SageMaker Hosting (including Model Monitoring), SageMaker Batch Transform, SageMaker Notebook instance, SageMaker Feature Store, Amazon S3, AWS Glue, Amazon ECR, AWS CodeBuild, AWS Step Functions, AWS Lambda, Amazon EFS.
Building the ML platform
The ML platform needs to provide several core platform capabilities, including:
- Data management with tooling for data ingestion, processing, distribution, orchestration, and data access control.
- Data science experimentation environment with tooling for data analysis/preparation, model training/debugging /validation/ deployment, access to code management repos and library packages, and self-service provisioning.
- Workflow automation and CI/CD pipelines.
Data Management
Amazon S3 serves as the primary storage solution for an ML platform on AWS. It is recommended to ingest datasets into S3 to ensure convenient and secure access from various data processing and machine learning services. The AWS Lake Formation service can be considered for constructing the data lake architecture.
The following figure shows a high-level data management architecture for ML

For machine learning workflow support, the following S3 buckets should be considered:
- Buckets for users/project teams: It's used to pull data from the enterprise data management platform or other data sources and store them in these buckets for further wrangling and analysis.
- Buckets for common features.
- Buckets for training/validation/test datasets.
- Buckets for ML automation pipelines: Used to store data needed for automation pipelines and should only be accessible by the automation services.
- Buckets for models.
Enabling self-service
To improve onboarding efficiency consider developing a self-service capability using the Service Catalog. The Service Catalog enables you to create self-service portfolio and products using CloudFormation scripts, and data scientists can directly request access to SageMaker Notebook / SageMaker Studio and other related AWS services without going through manual provisioning.

Automation pipelines
Automated MLOps pipelines can enable formal and repeatable data processing, model training, model evaluation, and model deployment.
MLOPS pipeline consists of the following components:
- Code repository: A code repository is the source for an MLOps pipeline run.
- Code build service: Used to build custom artifacts such as custom Docker containers and push containers to a Docker image repository such as Amazon ECR.
- Data processing service: Used to process raw data into training/validation/testing datasets for model training purposes.
- Model training service: Used for model training in an automated pipeline.
- Model registry: Contains the metadata associated with model artifacts such as the location of the model artifacts, the associated inference container image, and the IAM role for running the container.
- Model hosting service: SageMaker provides a model hosting service for both real-time inference and batch inference.
- Pipeline Management: End-to-end pipeline management is controlled by the AWS CodePipeline service.
The following figure illustrates one MLOps pipeline reference architecture that works across multiple AWS accounts to build a custom container.

The pipeline consists of five stages:
- Change commit stage: The data scientist/ML engineer commits code changes into a code repository.
- Pipeline start stage: A CodePipeline pipeline run is triggered in the Shared Services account.
- Container build stage: A CodeBuild project is then run as the next step in the pipeline in the Shared Services account.
- Model building stage: Upon the successful Docker image build, the model training step is kicked off across the account (from the Shared Services account to the Test/UAT account) by launching an AWS CloudFormation script in the Test/UAT account. The AWS CloudFormation script first creates an AWS Step Functions state machine workflow consisting of a SageMaker processing step, a SageMaker model training step, and an endpoint deployment step in the test/UAT account for testing purposes.
- Model registration stage: For centralized model management and inventory control.
- Production deploymentstage: When it is ready for production deployment, a separate CodePipeline workflow can be invoked in the Shared Services account to obtain release approval and run a CloudFormation script in the Production account to stand up a SageMaker endpoint for real-time inference.
Cross-account CodePipeline setup
When create a pipeline with actions from multiple accounts, you must configure the actions with proper permission so that they can access resources within the limitations of cross-account pipelines.

CodePipeline A represents the training pipeline, and CodePipeline A2 represents the production deployment pipeline.
- CodePipeline Role A: This role is assumed by CodePipeline A to run the model training pipeline in the Test/UAT account using CloudFormation.
- Cross Account Role B: This role is used to run the CloudFormation script to set up the Step Functions.
- Cross Account Role A2: This role is assumed by CodePipeline A2 to run the model deployment pipeline in the production account.
-
Cross Account Role C: This role is us
 ed to run the CloudFormation script to set up the SageMaker endpoint and other related resources.
ed to run the CloudFormation script to set up the SageMaker endpoint and other related resources. - CodePipeline Input/output bucket: This bucket is used for sharing artifacts across different pipeline stages and different accounts. AWS Lambda supports bucket policies that can directly be attached to a bucket.
- KMS Key: Required to encrypt data in the CodePipeline input/output bucket. The KMS key needs to provide access to the Test/UAT account, Production account, and CodePipeline role A.
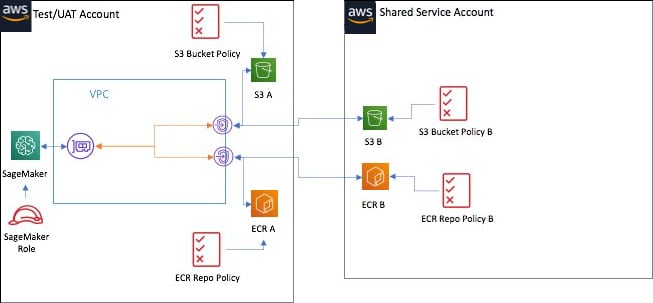
Cross-account resource access via VPC endpoint
To ensure all network communication takes place within the private network, private endpoints should be used for accessing resources within the same AWS account or across different AWS accounts.

The preceding figure illustrates how Amazon S3 and ECR can be accessed across accounts using VPC endpoints. SageMaker is attached to a VPC in the Test/UAT account through an Elastic Network Interface (ENI), and the VPC endpoints for S3 and ECR are attached to the Test/UAT account.
Deployment Scenarios
Depending on the deployment requirements, different pipelines need to be developed.
- End-to-end pipeline: This pipeline builds everything from a source code repository and input data and deploys a model to a production endpoint.
- Docker build pipeline: This pipeline builds Docker images using source code (a Docker file).
- Model training pipeline: This pipeline trains/retrains a model with an existing Docker container image and dataset.
- Model registration pipeline: This pipeline registers an existing model saved in S3 and its associated inference container in ECR in the SageMaker model registry.
- Model deployment pipeline: This pipeline deploys an existing model from the SageMaker model registry to an endpoint.
There are several ways to trigger a pipeline run, including:
- A source code change
- A scheduled event
- On-demand via CLI / API
ML Platform Monitoring

There are three main areas of an ML platform that require monitoring:
- Automation Pipeline: Configure the AWS environment to monitor automation pipelines for pipeline status, and trigger notifications when important events are detected.
- Model training: You can monitor the model building pipeline for training status and metric reporting. The various services used in the pipeline can provide job status and integrate with other AWS services to support data collection, analysis, and real-time notification.
- Production model serving: Monitor production endpoints for system health, data drift, model drift, data, and model bias, and explanation for each prediction. The SageMaker endpoint reports a set of system metrics such as CPU and memory utilization and model invocation metrics.
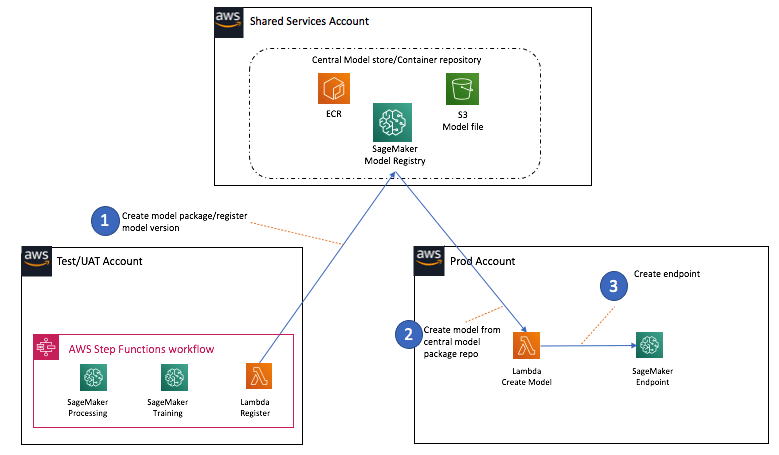
Model Inventory Management
it's an important component of model risk management (MGM). All models deployed in production need to be accurately registered and versioned to enable model lineage tracking and auditing.
There are several approaches for managing the model inventory, Following are two different approaches within the context of building an ML platform:
- Distributed model management approach: The model files are stored in the account/environment in which it is generated, and the model is registered in the SageMaker model registry belonging to each account.
-
Central model management approach: All models generated by the automated pipelines are stored in the Shared Services account along with the associated inference Docker container images, and a model package group is created to track different versions of a model.
Audit Trail Management
Operations against AWS services are logged by AWS CloudTrail, and log files are stored in S3.

CloudTrail provides features for accessing and viewing CloudTrail events directly in the console. CloudTrail can also integrate with log analysis tools such as Splunk to further processing and reporting.
SageMaker services such as notebook, processing job, or training job report the IAM roles assumed by these individual services against the different API events. To associate these activities with each individual user, consider creating a separate IAM role for each user.
Data and Artifacts Lineage Tracking
Tracking all the artifacts used for a production model is an essential requirement for reproducing the model to meet regulatory and control requirements.

- Code versioning: Code repositories such as GitLab, Bitbucket, and CodeCommit support versioning of the code artifacts.
- Dataset versioning: Training data can be version controlled by using a proper S3 data partition scheme.
- Container versioning: Amazon ECR uniquely identifies each image with an Image URI (repository URI + image digest ID). Images can also be pulled with repository URI + tag.
- Training job versioning: Each SageMaker training job is uniquely identified with an ARN, and other metadata such as hyperparameters, and model output URI are automatically tracked with the training job.
- Model versioning: A model package can be registered in SageMaker using the URL of the model files in S3 and URI to the container image in ECR.
- Endpoint versioning: Each SageMaker endpoint has a unique ARN, and other metadata, such as the model used, are tracked as part of the endpoint configuration.
Infrastructure Configuration Change Management
AWS Config is a service that enables you to assess, audit, and evaluate the configuration of AWS resources. It tracks changes in CodePipeline pipeline definitions, CodeBuild projects, and CloudFormation stacks, and it can report configuration changes across timelines.
Tag Management for an ML platform
The tagging mechanism in AWS enables to assign metadata information to virtually any AWS resource. Each tag is represented by a key-value pair.
Common use cases of using tags include:
- Business tags and cost allocation
- Tags for automation
- Security and risk management
In an ML platform, tagging should be considered for the following resources:
- Experimentation environment resources: The SageMaker Notebook provision should be automated using CloudFormation script and tags such as owner name, owner id, dept, environment, and project should be automatically populated by the CloudFormation script.
- Pipeline automation resources: Resources automated by the automation pipeline should be probably tagged. The pipeline should be automatically provisioned using CloudFormation scripts and tags.
- Production resources: Resources such as SageMaker endpoints, model artifacts, and inference images should be tagged.
Conclusion
Getting started with an enterprise-grade ML platform can be challenging for organizations due to the complexity of architecture components and the additional considerations around data science, data management, and governance.
This article offers a thorough understanding of the different components involved in building a secure ML platform. It provides implementation guidance for constructing an enterprise ML platform from scratch, including the setup of an experimentation environment, automation pipeline, and production model serving, using AWS services.

Top comments (0)