
☁ Puff ☁
Python and Rust are near perfect compliments for each other.
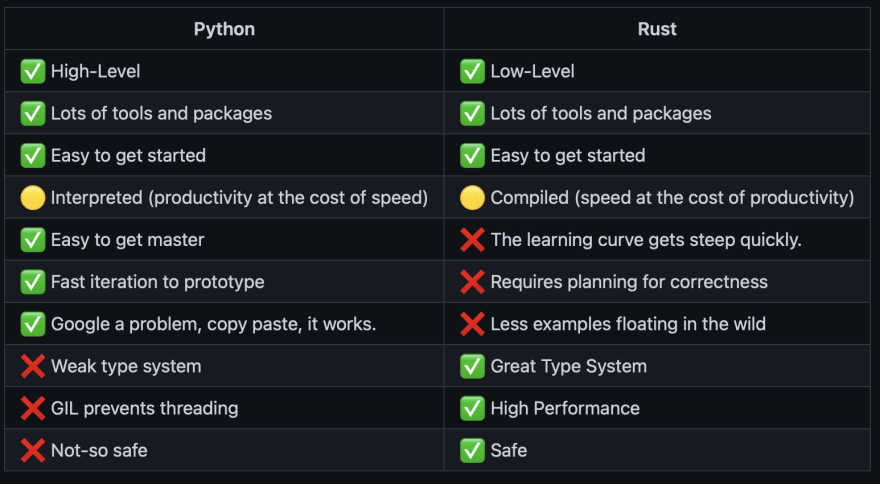
One of the primary challenges of writing Python is how to optimize core loops and logic of your application. Python has a lot of integrations that make it possible to write C code and get another level of performance, but those libraries historically have not been that viable due to a plethora of issues involving ease of use, portability and usefulness.
Rust is a great language that makes it easy to write high-performance code safely. However, the added safety can add a large degree of cognitive overhead that can sometimes get in the way and prevent you from just getting it done.
Puff recognizes that Python is a great logic layer but bad at computations and optimizations. Puff also recognizes that Rust is great at computations and optimizations but sometimes it is difficult to express extremely high level abstractions.
Puff is a "deep stack" framework to allow Rust to sit on another level as Python. It allows you to build a cohesive set of tools in Rust that use Cargo and the Rust ecosystem and easily talk to Python.
Puff makes the bold attempt at building a framework with full compatibility:
- Python Compatible
- Rust Compatible
- AsyncIO Compatible
- ASGI / WSGI Compatible
- Tokio Compatible
- Django Compatible
- Axum Compatible
- FastAPI Compatible
A hybrid approach utilizes the best of both languages. Use Python to control logic and high-level concepts. Use Rust to optimize tight loops and IO. Easily move between both in a fluid motion.
Full Service
Modern apps are complex and require API endpoints, database pools, redis, websockets, PubSub and more. Puff believes that those things should be part of a "standard library" so they all work well together. With this philosophy, Puff includes:
- Greenlets
- Asyncio
- Uvloop
- Postgres
- Redis
- Multi-node PubSub
- Http/Http2 Server
- GraphQL
Puff's Graphql engine has a couple of key features. It supports subscriptions allowing you to easily write websocket interfaces. The engine also accepts raw SQL returned from Python functions. It will take the SQL, run it on the current database pool and transform the rows to JSON without having to return to Python.
Most importantly it works on a "layer" basis. Most GraphQL libraries work on a "node" basis going to each object to resolve the fields. Puff works by "layers", collecting all information needed for every object in a field before it resolves it. This means you can make the minimum number of queries necessary.
See later in this post for a GraphQL example.
Quick Start
Puff requires Python >= 3.10, Rust / Cargo. Python's Poetry is optional.
Your Rust Puff Project needs to find your Python project. Even if they are in the same folder, they need to be added to the PYTHONPATH.
One way to set up a Puff project is like this:
cargo new my_puff_proj --bin
cd my_puff_proj
cargo add puff-rs
poetry new my_puff_proj_py
cd my_puff_proj_py
poetry install puff-py
And add the puff plugin for poetry.
[tool.poetry.scripts]
cargo = "puff.poetry_plugins:cargo"
Now from my_puff_proj_py you can run your project with poetry run cargo to access cargo from poetry and expose the virtual environment to Puff.
The Python project doesn't need to be inside off your Rust package. It only needs to be on the PYTHONPATH. If you don't want to use poetry, you will have to set up a virtual environment if needed and set PYTHONPATH when running Puff.
Example
Puff allows you to access Rust from Python easily.
use puff_rs::prelude::*;
use puff_rs::program::commands::PythonCommand;
// Use pyo3 to generate Python compatible Rust classes.
#[pyclass]
struct MyPythonState;
#[pymethods]
impl MyPythonState {
fn hello_from_rust(&self, py_says: Text) -> Text {
format!("Hello from Rust! Python Says: {}", py_says).into()
}
// Async Puff functions take a function to return the result with and offload the future onto Tokio.
fn hello_from_rust_async(&self, return_func: PyObject, py_says: Text) {
run_python_async(return_func, async {
tokio::time::sleep(Duration::from_secs(1)).await;
debug!("Python says: {}", &py_says);
Ok(42)
})
}
}
fn main() -> ExitCode {
let rc = RuntimeConfig::default().set_global_state_fn(|py| Ok(MyPythonState.into_py(py)));
Program::new("my_first_app")
.about("This is my first app")
.runtime_config(rc)
.command(PythonCommand::new("run_hello_world", "my_python_app.hello_world"))
.run()
}
Python:
from puff import global_state
rust_obj = global_state()
def hello_world():
print(rust_obj.hello_from_rust("Hello from Python!"))
# Rust functions that execute async code need to be passed a special return function.
print(puff.wrap_async(lambda ret_func: rust_obj.hello_from_rust_async(ret_func, "hello async")))
See puff-py repo and puff repo for more examples including Django, FastAPI, and more.
GraphQL Example
Here is an example of a Puff GraphQL app. Notice you can create Python objects and return them or you can return SQL strings.
The GraphQL example in the Repo has information about how to run it.
from puff import graphql
from dataclasses import dataclass
from typing import Optional, Tuple, List, Any
pubsub = puff.global_pubsub()
CHANNEL = "my_puff_chat_channel"
@dataclass
class SomeInputObject:
some_count: int
some_string: str
@dataclass
class SomeObject:
field1: int
field2: str
@dataclass
class DbObject:
was_input: int
title: str
@classmethod
def child_sub_query(cls, context, /) -> Tuple[DbObject, str, List[Any], List[str], List[str]]:
# Extract column values from the previous layer to use in this one.
parent_values = [r[0] for r in context.parent_values(["field1"])]
sql_q = "SELECT a::int as was_input, $2 as title FROM unnest($1::int[]) a"
# returning a sql query along with 2 lists allow you to correlate and join the parent with the child.
return ..., sql_q, [parent_values, "from child"], ["field1"], ["was_input"]
@dataclass
class Query:
@classmethod
def hello_world(cls, parents, context, /, my_input: int) -> Tuple[List[DbObject], str, List[Any]]:
# Return a Raw query for Puff to execute in Postgres.
# The elipsis is a placeholder allowing the Python type system to know which Field type it should tranform into.
return ..., "SELECT $1::int as was_input, \'hi from pg\'::TEXT as title", [my_input]
@classmethod
def hello_world_object(cls, parents, context, /, my_input: List[SomeInputObject]) -> Tuple[List[SomeObject], List[SomeObject]]:
objs = [SomeObject(field1=0, field2="Python object")]
if my_input:
for inp in my_input:
objs.append(SomeObject(field1=inp.some_count, field2=inp.some_string))
# Return some normal Python objects.
return ..., objs
@classmethod
def new_connection_id(cls, context, /) -> str:
# Get a new connection identifier for pubsub.
return pubsub.new_connection_id()
@dataclass
class Mutation:
@classmethod
def send_message_to_channel(cls, context, /, connection_id: str, message: str) -> bool:
print(context.auth_token) # Authoritzation bearer token passed in the context
return pubsub.publish_as(connection_id, CHANNEL, message)
@dataclass
class MessageObject:
message_text: str
from_connection_id: str
num_processed: int
@dataclass
class Subscription:
@classmethod
def read_messages_from_channel(cls, context, /, connection_id: Optional[str] = None) -> Iterable[MessageObject]:
if connection_id is not None:
conn = pubsub.connection_with_id(connection_id)
else:
conn = pubsub.connection()
conn.subscribe(CHANNEL)
num_processed = 0
while msg := conn.receive():
from_connection_id = msg.from_connection_id
# Filter out messages from yourself.
if connection_id != from_connection_id:
yield MessageObject(message_text=msg.text, from_connection_id=from_connection_id, num_processed=num_processed)
num_processed += 1
@dataclass
class Schema:
query: Query
mutation: Mutation
subscription: Subscription
Status of Project
Puff is an experiment, but the results are very promising in terms of performance and productivity. The Zen of Puff and the Deep Stack is that no one language has the answer and fluidity is key.

Top comments (1)
Amazing job! I'm very interested in learning more about and experimenting it :D