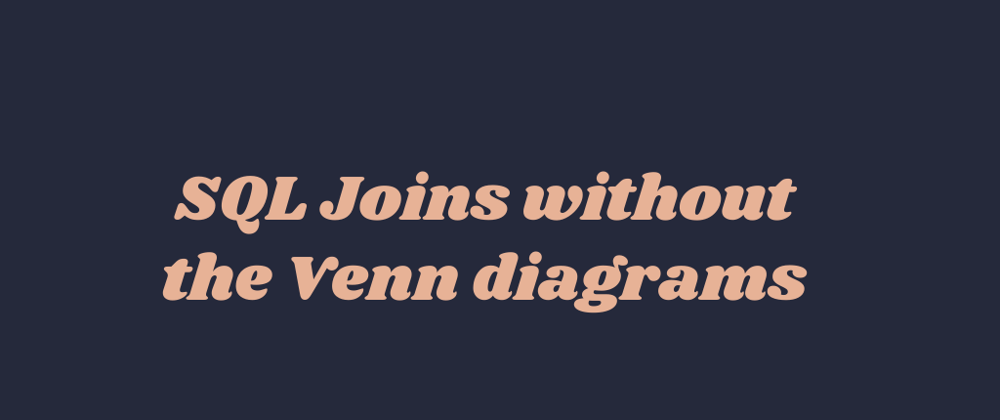
JOINs are the first big learning curve after getting your head around SQL basics. You may not find everything you need in one table so it's important to know which JOIN clause to use to get the data you need.
While there are plenty of guides to JOINs that use Venn diagrams to get the point across, I prefer something more visual.
INNER JOIN
Use an INNER JOIN, shortened to 'JOIN', when you want to find the match between two tables. You need to have a column on both tables that you join ON, and that's where the match happens. Any results where there is not a match are discarded.

select
o.order_item,
i.inventory_item
from
orders o
inner join
inventory i
on o.order_item = i.inventory_item
LEFT JOIN
Use a LEFT JOIN when you want to find a match between two tables, but also show a NULL where there is no match from the right table. A RIGHT JOIN does the same but in reverse.
Like the INNER JOIN, you need a column to join ON. Unlike the INNER JOIN, a NULL is used to show there is no match between the two tables.

select
o.order_item,
i.inventory_item
from
orders o -- this is the left table
left join
inventory i -- this is the right table
on o.order_item = i.inventory_item
CROSS JOIN
A CROSS JOIN joins everything with everything. There is no need to provide a column to join on, and it can result in a very big data set, (and a really big image so you’ll have to use your imagination when reviewing the image below).
Proceed with caution.

select
o.order_item,
i.inventory_item
from
orders o
cross join
inventory i
UNION
While a JOIN combines columns horizontally a UNION combines rows vertically. This is technically a set operator rather than a JOIN clause but as we are talking about combining datasets this is a good opportunity to introduce it.
Using a UNION combines the result of two queries into one column and removes duplicates.
If your query has multiple columns, they need to be in the same order to complete the UNION.

select *
from
orders
union
select *
from
inventory
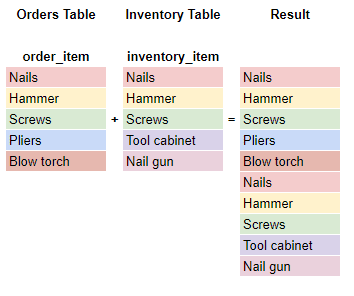
UNION ALL
The UNION ALL combines the results of two queries the same as a UNION but keeps the duplicates in the result.
select *
from
orders
union all
select *
from
inventory
The best way to get your head around JOINs is to start using them. If you aren't working with a SQL database already, check out SQLZoo or Hacker Rank to experiment with JOINs.
Read more

This post first appeared on helenanderson.co.nz





Top comments (4)
To start with, I generally like the look of this explanation as an article.
I'm going to be picky and cruel in saying this: but I think it's a disservice to not show that even inner joins enact row multiplications when there are multiple instances of the join value.
It's fair enough to not do so in the very first example of an inner join. Alas, having the multiplication of rows then only be shown later when the cross join is taught leaves a dreadful legacy.
I have spent many hours re-teaching analysts - who have sometimes been writing SQL for years - that have not been aware that repeated values on either side of the inner join can cause row expansions in the result. As I am wont to say - if something can happen at all in data, then at some time it will happen.
I think the basic relational fact of row expansions needs to be taught as soon as the inner join has been taught. I find that helps avoid a lot of misunderstandings about left joins too. I'm not saying it's easy, even less so in static print/screen material - I usually have the luxury of doing live peer guidance with a whiteboard, so I don't have a magic solution to proffer. I would suggest going to the bother of doing a second example of the inner join but showing a value in there twice on one side and thrice on the other (because a 2-1 or a 2-2 leaves room for the learner to misunderstand what's happening).
Of course, there will be some environments that new data analysts may encounter where enough tables have primary keys and so row multiplying joins might be rare. But I'd have to say that over my years of experience that this is becoming less common not more. Indeed I've been seeing "big data" users getting advice to not bother with key constraints for performance reasons and newer platforms such as Hadoop having fewer available constraints anyway.
I certainly don't enjoy dealing with multi-megabyte SQL scripts in which there is an unknown spot of row multiplication to be debugged. The most subtly pernicious is the combination of the coders thinking that join values are unique but having done nothing to ensure that they are - and when the data reality is that the data is only very-nearly-always unique.
While it can seem that such problems are really about managing the uniqueness in the tables I do think that a naiveté about inner joins allows problems to spread like an infection in a data processing sequence. I think that such an innocence comes from not being shown inner join row multiplications in the tuition phase.
In 20 years of writing SQL I have never found a legitimate use for RIGHT JOIN in production code. RJ indicates you don't understand your data as it can always be rewritten as a LJ.
One issue that often catches new users is the filter predicate. If you apply it to the Join clause on a LJ you only drop the joined record,; if you add it to the WHERE clause you drop the entire row.
Great advice! Thanks for sharing :)
The colors make this perfect. So clear and understandable